






文章目录
前言
样本不均衡在机器学习分类问题中常见,尤其是在二分类场景。比如欺诈检测、疾病诊断等,少数类样本数量远少于多数类。这种情况下,模型可能会偏向多数类,导致对少数类的预测效果差。
举个实际例子:
假设数据集中有 1000 条信用卡交易记录,其中:
- 980 条正常交易(负类,多数类)
- 20 条欺诈交易(正类,少数类)
此时正负类比例为 1:49,即典型的样本不均衡问题。如果模型将所有样本预测为正常交易,准确率高达 98%,但对欺诈交易的识别完全失败(召回率 0%)。这就是样本不均衡带来的陷阱。
解决策略
1. 数据层面的解决策略
核心在于提高少数样本的存在感,既不能出现过多噪声点,又不能丢失过多的关键信息。
- 过采样(Oversampling)
- 欠采样(Undersampling)
- 混合采样
2. 模型层面的解决策略
- 调整类权重
- 集成学习
过采样(Oversampling)
1.随机过采样
从少数类中随机复制样本,增加其数量以平衡数据集。这种方法简单但可能导致过拟合。
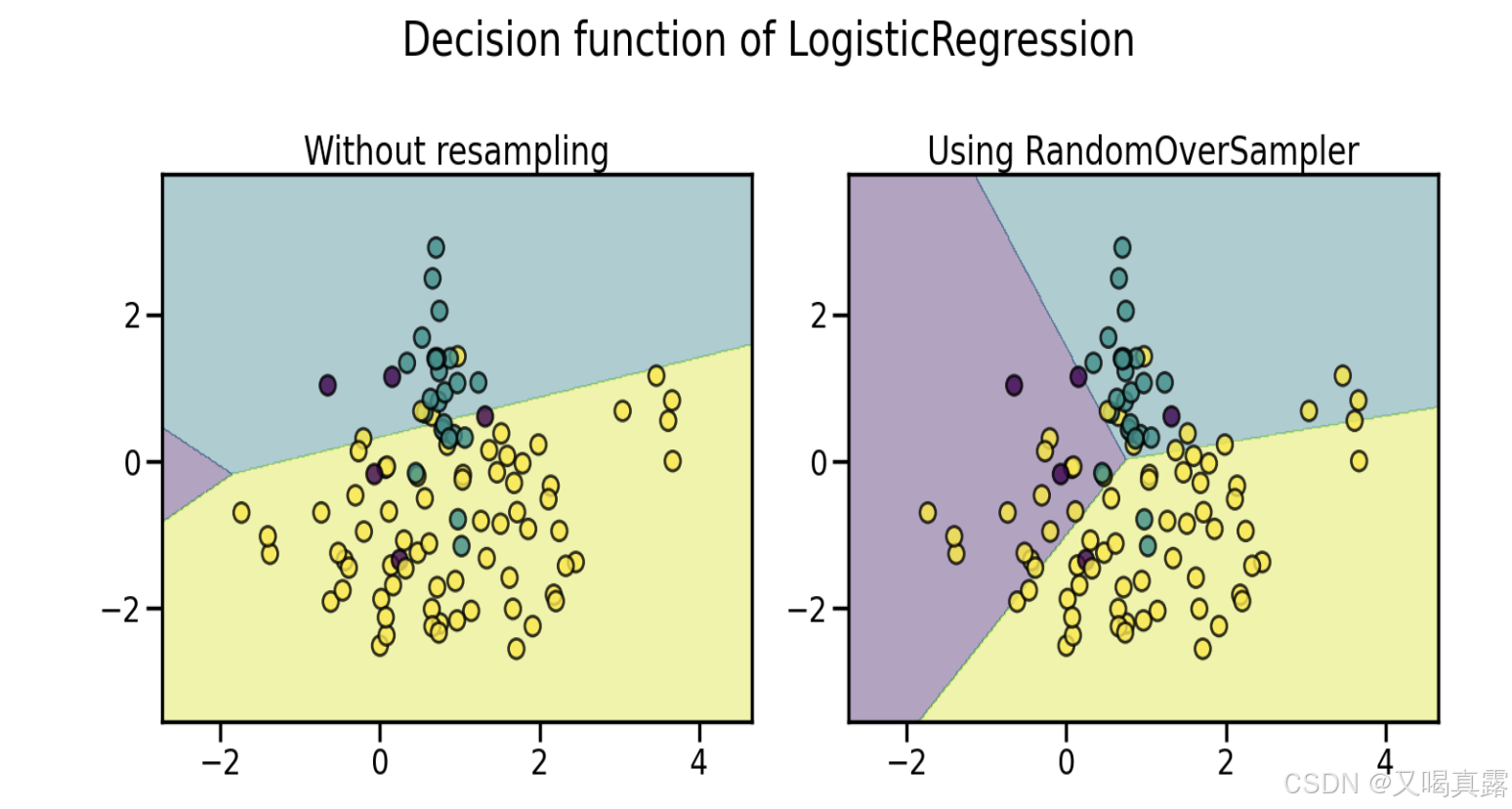
⚠️注意:未设置
shrinkage参数的随机过采样方法,只是对原有的少数样本进行复制,复制出来的新样本和原有的少数样本一模一样,所以图中所展示出的数据分布没有任何变化(只是紫色点的数量增多,重叠在一起),但由于少样本数量的增多,决策边界会发生改变。
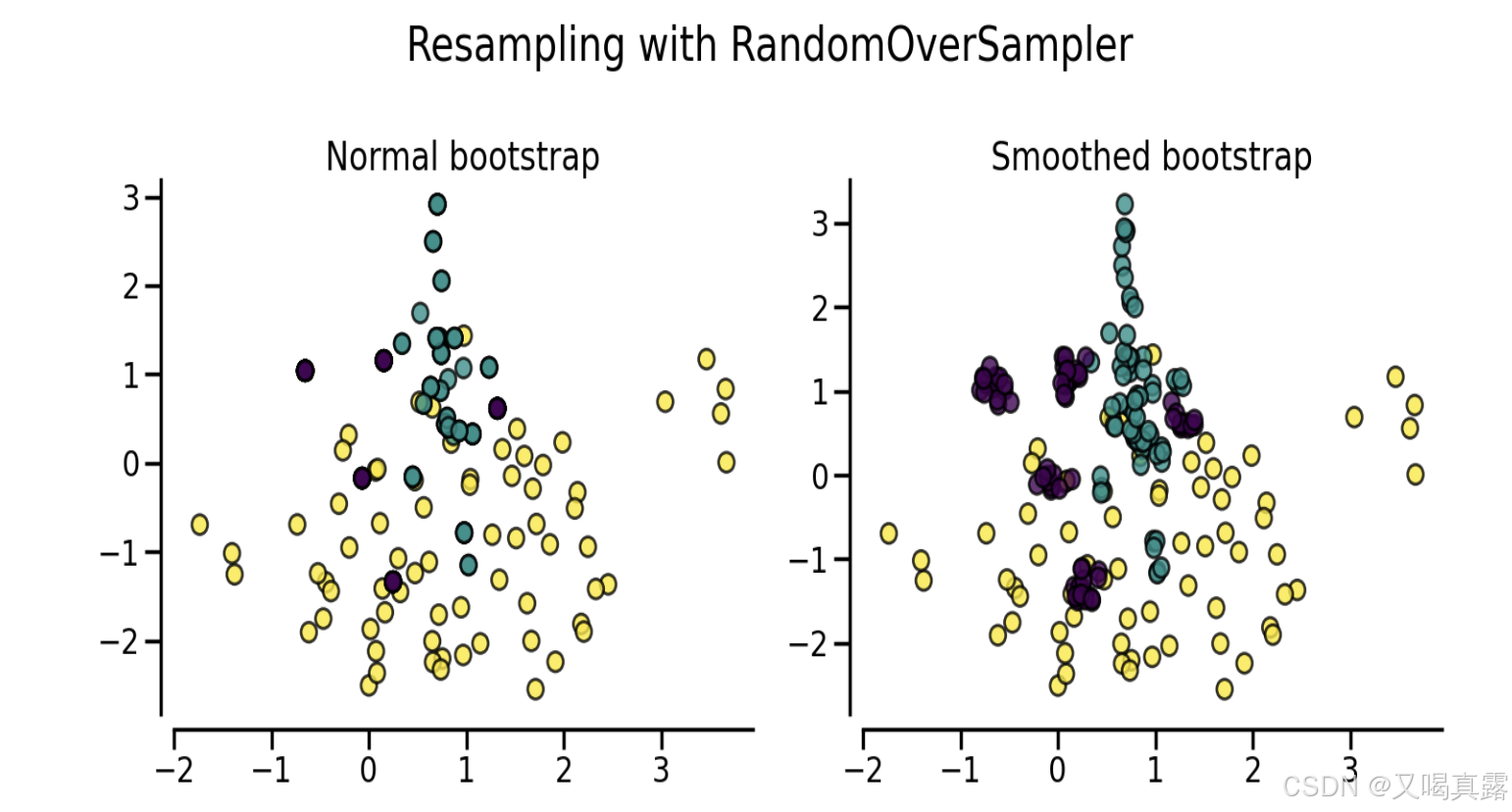
通过设置
shrinkage参数,进而控制了生成样本的分散度,实现生成的新样本不重叠。
代码示例如下:
from imblearn.over_sampling import RandomOverSampler
# 假设X是特征集,y是标签集
ros = RandomOverSampler(random_state=42)
X_resampled, y_resampled = ros.fit_resample(X, y)
除了在随机过采样中设置相关参数实现生成样本不重叠的效果,还可以采用SMOTE和ADASYN方法对少量样本进行过采样处理。
下图展示了三类过采样方法在生成少数样本时的区别:
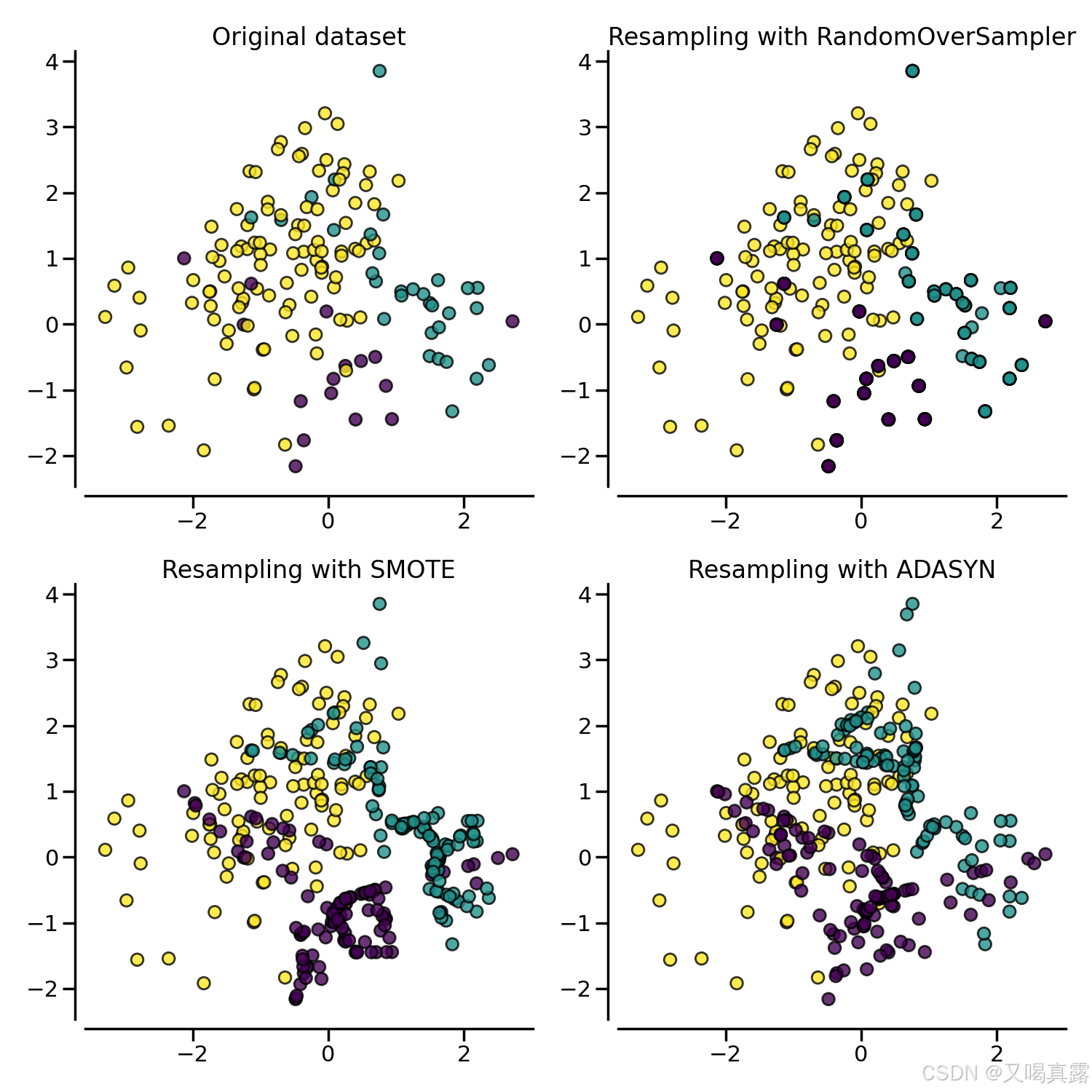
2.SMOTE(合成少数类过采样技术)
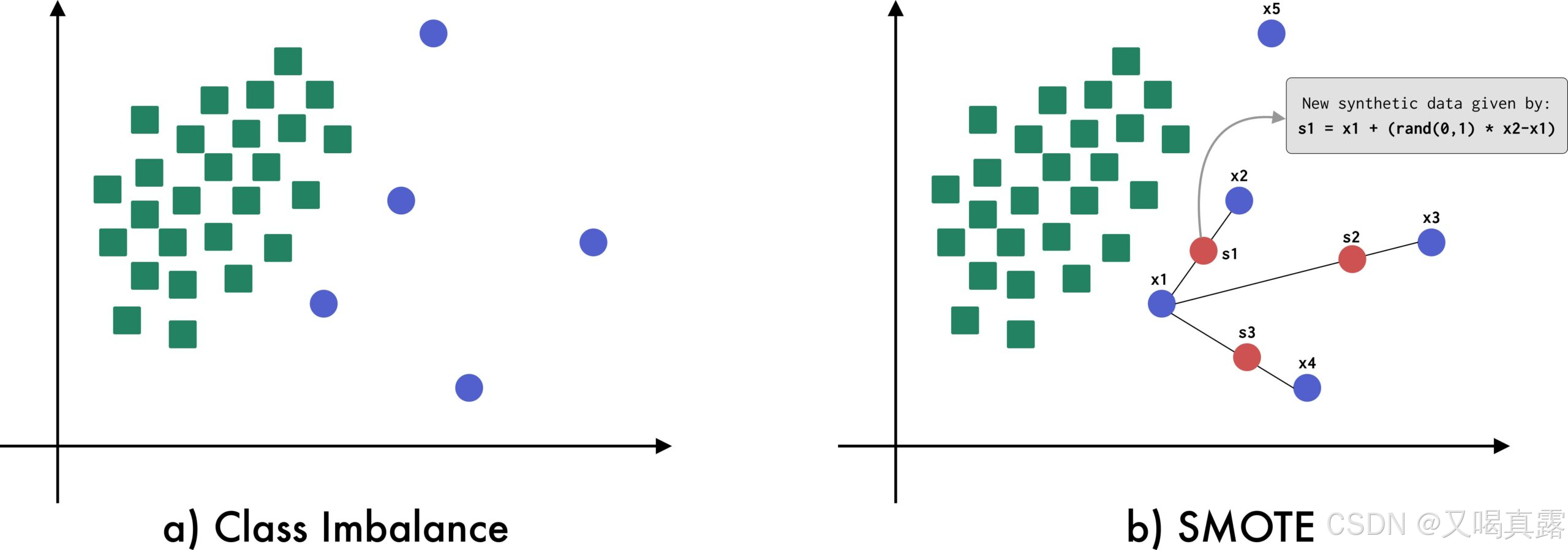
如图 (b) 所示,利用SMOTE算法 从 x1 生成合成数据,同时考虑 3 个最近邻居(x2、x3 和 x4)以生成合成数据 s1、s2 和 s3。
SMOTE 的整体思路:
对于少数类的每一个样本,找到其“k”个最近邻居(默认 k = 5),然后在样本与其每个邻居生成的点对之间生成新的合成数据,这个过程被称为插值(interpolation)。
通过插值生成新的少数类样本,不是简单地复制现有的少数类样本,从而避免简单复制带来的过拟合问题。
代码示例如下:
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
SMOTE算法本身仍存在一些局限性:
- SMOTE 仅适用于连续数据(离散数据不适用,例如:0/1分类);
- 生成的合成数据是线性相关的,这可能导致生成的数据出现偏差,从而产生过度拟合的模型。
Borderline-SMOTE
Borderline-SMOTE 检测哪些样本位于类空间的边界上,并将 SMOTE 技术应用于这些样本。
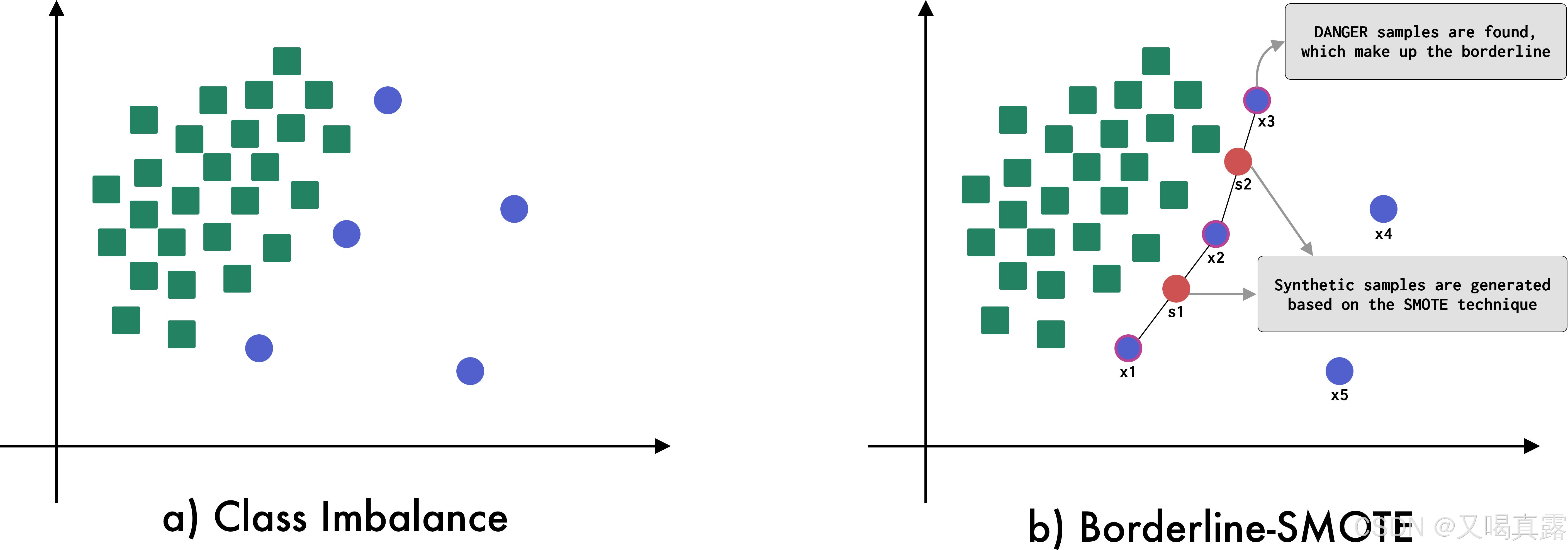
从上图可以看出,Borderline-SMOTE使用边界线的上的少数类样本,来合成新的样本。
3.ADASYN(自适应合成采样)
ADASYN 是一种基于 SMOTE 算法生成合成数据的技术。
ADASYN 与 SMOTE 的区别在于:ADASYN可以检测出在多数类占主导地位的空间中发现的少数类样本,以便在少数类的低密度区域中生成样本。ADASYN 专注于那些由于位于低密度区域而难以分类的少数类样本。
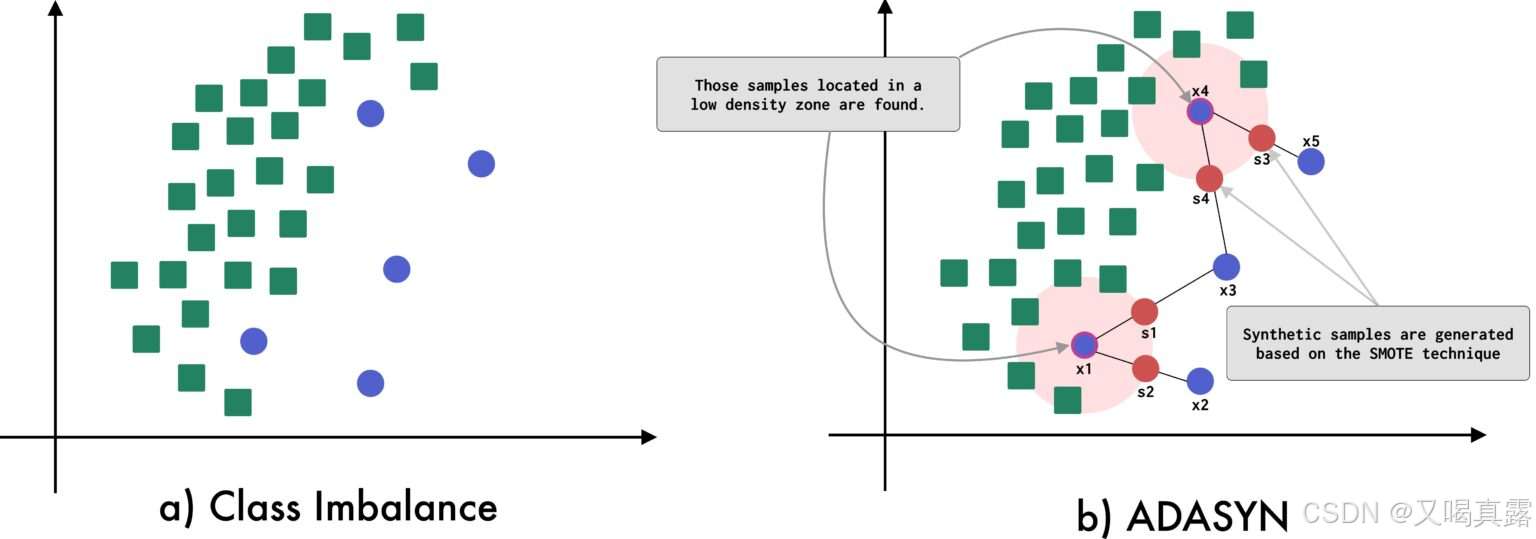
从上图可以看出,用于生成合成样本的原样本是位于低密度区域的样本。
代码示例如下:
from imblearn.over_sampling import ADASYN
adasyn = ADASYN(random_state=42)
X_resampled, y_resampled = adasyn.fit_resample(X, y)
注意
在使用过采样方法时,需要注意以下几点:
- 过采样可能会导致过拟合,特别是在合成新样本时。
- 应该只在训练集上进行过采样,以避免信息泄露到测试集。
- 在应用过采样之前,最好先进行数据预处理,如标准化或归一化。
References
[1] SMOTE: Synthetic Data Augmentation for Tabular Data
[2] imbalanced-learn


















 1280
1280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









