







首先感谢以下作者的著作:https://blog.youkuaiyun.com/qq_36039236/article/details/108219895
https://zhuanlan.zhihu.com/p/99139680
https://zhuanlan.zhihu.com/p/373033198
排版可能是不太好,因为我先记在我的语雀笔记里的,但想到也是优快云教我这么多,回馈优快云,因此二次发在这里。
我这边对语句进行了更新,话不多说,开始吧。
1.建表语句
• 源数据,文件中是以,号隔开的
• 这里数据重复了,但不要去重哈
id,date
A,2018-09-04
B,2018-09-04
C,2018-09-04
A,2018-09-05
A,2018-09-05
C,2018-09-05
A,2018-09-06
B,2018-09-06
C,2018-09-06
A,2018-09-04
B,2018-09-04
C,2018-09-04
A,2018-09-05
A,2018-09-05
C,2018-09-05
A,2018-09-06
B,2018-09-06
C,2018-09-06
• 插入语句
insert into table tb_use values
("A","2018-09-04")
,("B","2018-09-04")
,("C","2018-09-04")
,("A","2018-09-05")
,("A","2018-09-05")
,("C","2018-09-05")
,("A","2018-09-06")
,("B","2018-09-06")
,("C","2018-09-06")
,("A","2018-09-04")
,("B","2018-09-04")
,("C","2018-09-04")
,("A","2018-09-05")
,("A","2018-09-05")
,("C","2018-09-05")
,("A","2018-09-06")
,("B","2018-09-06")
,("C","2018-09-06");
• 设置本地模式
set hive.exec.mode.local.auto=true;
• 在hive中创建表
drop table tb_use;
create table tb_use(
id string,
date string
)
-- partitioned by (daystr string) -- 指定分区,必须在最前面(先指定存入的分区才能指定其他)
row format delimited fields terminated by ',' -- 指定行的分隔符
lines terminated by '\n' -- 指定列的分隔符,默认为'\n'
stored as textfile -- 指定存储文件的类型,hive中默认类型为textfile,SequenceFile,RCFile,ORCFile
-- location 'hdfs_path'; -- 存储到HDFS路径
-- 【我使用的】
create table tb_use(
id string,
datee string
)row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile ;
;
• 从本地加载数据到表中
load data local inpath '/export/data/test.txt' overwrite into table tb_use;
2.基础知识
• 将日期格式的字符串转为日期格式
select cast('2018-09-05' as date) ;
-- 结果:
2018-09-05
• 日期增加函数:date_add(string startdate, int days)
select date_add('2016-12-08',10);
-- 结果:
2016-12-18
• 日期减少函数:date_sub (string startdate, int days)
select date_sub('2016-12-08',10);
-- 结果:
2016-11-28
• lead函数(第三个参数是当查不到记录的时候显示-1,默认是null)
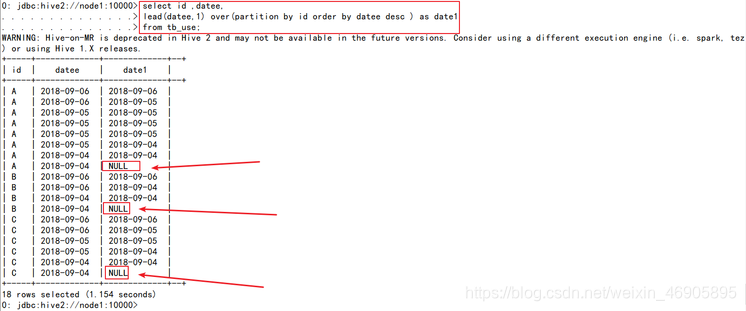
select id ,datee,
lead(datee,1) over(partition by id order by datee desc ) as date1
from tb_use ;
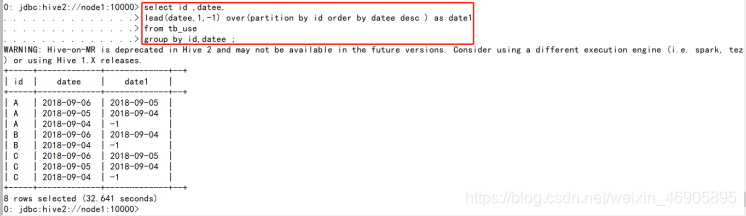
select id ,datee,
lead(datee,1,-1) over(partition by id order by datee desc ) as date1
from tb_use
group by id,datee ;
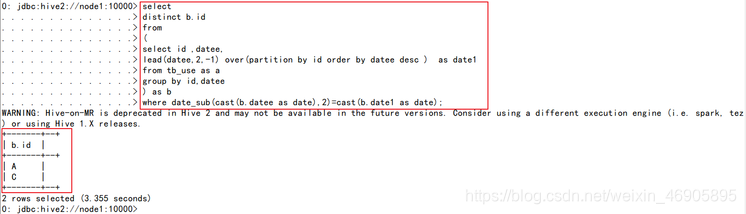
3.解法1:lead搭配date_sub函数
• 展现连续登陆两天的用户信息(用窗口函数分析方法)
select
distinct b.id as c1
from
(
select id ,datee,
lead(datee,1,-1) over(partition by id order by datee desc ) as date1
from tb_use as a
group by id,datee
) as b
where date_sub(cast(b.datee as date),1)=cast(b.date1 as date);

• 展现连续登陆两天的用户id(用窗口函数分析方法)
-- hive版
select
count(distinct b.id) as c1
from
(
select id ,datee,
lead(datee,1,-1) over(partition by id order by datee desc ) as date1
from tb_use as a
group by id,datee -- 1.这里去重是为了防止重复登录的
) as b
where date_sub(cast(b.datee as date),1)=cast(b.date1 as date);
-- mysql版
select
b.id as c1
from
(
select id ,datee,
lead(datee,1,-1) over(partition by id order by datee desc ) as date1
from tb_use as a
group by id,datee
) as b
where date_sub(cast(b.datee as date),1)=cast(b.date1 as date);
4.解法2:row_number搭配date_sub函数
解法网址:https://www.zhihu.com/people/chen-zhi-13-51
感谢这位作者,拖他的福我才会的
SELECT id
FROM (
-- step3:用date_sub函数,发现如果连续登录的话,ds是一样的
SELECT *
,DATE_SUB(datee,INTERVAL rn DAY) AS ds
FROM (
-- step2:加个开窗函数,为第三步做准备
SELECT *
,row_number() over(PARTITION BY id ORDER BY datee) AS rn
FROM (
-- step1:首先对id、日期进行分组去重,因为一个用户每天会多次登录,生成tmp1表
SELECT *
FROM tb_use
GROUP BY id
,datee
) tmp1
) tmp2
) tmp3
GROUP BY id
,ds
HAVING count( *) >2;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









