






DeepSeek-R1 是AI公司深度求索(DeepSeek)于2025年1月发布的一款开源高性能推理模型。该模型采用强化学习策略进行训练,在逻辑推理、数学和编程方面性能表现媲美OpenAI o1,在性价比和开放性方面具有显著优势,为人工智能领域的发展带来了新的可能性。
移动云的云主机产品已对该模型进行了全面支持:搭载自研COCA-Infer推理引擎+CMCCL高性能集合通信库,深度优化显著提升推理性能,为DeepSeek模型的规模化应用提供高效算力支持,助力国产AI技术突破性能瓶颈,且移动云平台可快速部署和更新模型,方便将最新版本的DeepSeek-R1模型应用于您的业务,下边将为您介绍部署和使用的完整流程,助您轻松获得自己专属的DeepSeek。
首先根据您想使用的模型信息订购一台移动云云主机:移动云官网-云擎未来,智信天下

DeepSeek模型与推荐规格信息:
| 模型名称 | 模型权重大小(bfloat16 ) | ollama量化后模型权重大小 | 硬件配置 | 推荐配置 |
| DeepSeek-R1-Distill-Qwen-1.5B | 3.55GB | 1.1GB | 可配置1张T4或V100或A100或A800 GPU卡 | g4t.2xlarge.8、g4v.2xlarge.8、g4a.2xlarge.8、g3t.xlarge.8、g3v.xlarge.8 |
| DeepSeek-R1-Distill-Qwen-7B | 15.23GB | 4.7GB | GPU加速需至少2张T4,或者1张V100或A100或A800 GPU卡 | g4t.4xlarge.8、g4v.2xlarge.8、g4a.2xlarge.8、g3t.4xlarge.8、g3v.xlarge.8 |
| DeepSeek-R1-Distill-Llama-8B | 16.06GB | 4.9GB | GPU加速需至少2张T4或V100或A100或A800 GPU卡 | g4t.4xlarge.8、g4v.2xlarge.8、g4a.2xlarge.8、g3t.4xlarge.8、g3v.xlarge.8 |
| DeepSeek-R1-Distill-Qwen-14B | 29.54GB | 9.0GB | GPU加速需至少4张T4 GPU卡,或者2张V100或A100或A800 GPU卡 | g4t.8xlarge.8、g4v.4xlarge.8、g4a.4xlarge.8、g3t.8xlarge.8、g3v.4xlarge.8 |
| DeepSeek-R1-Distill-Qwen-32B | 65.54GB | 20GB | GPU加速需至少4张V100 GPU卡或A100或A800 GPU卡 | g4v.8xlarge.8、g4a.8xlarge.8、g3v.8xlarge.8 |
注:1、ollama运行的是量化的模型,使用的是GGUF格式的模型文件,而COCA-Infer运行的是bfloat16格式的模型,ollama运行模型占用的显存相对更少。
2、以下示例在启用英伟达显卡的Ubuntu 22.04 64位操作系统下进行,默认相关驱动、CUDA Toolkit已安装。
下面通过两种方式来实现本地的DeepSeek R1模型部署。
- Ollama部署DeepSeek大模型
Ollama是一个快速、轻量且易于使用的开源AI代理框架,可以用来托管和运行各种语言模型。
执行如下命令
- curl -fsSL https://ollama.com/install.sh | sh
注意:默认Ollama会使用您的CPU来运行模型,而并非GPU,对于那种比较小的模型用CPU+集成显卡也能较好的进行工作,如果想运行更大的模型或更快的响应速度,您需要安装CUDA Toolkit以更好地利用独立显卡。
提供两种模型运行方案,一种为原版方案,访问github资源;另一种为国内加速方案,使用国内modelscope的资源。
(1)原版模型运行
下面是DeepSeek R1模型的运行方式,整理如下:
| 模型名称 | 运行命令 |
| DeepSeek-R1-Distill-Qwen-1.5B | ollama run deepseek-r1:1.5b |
| DeepSeek-R1-Distill-Qwen-7B | ollama run deepseek-r1:7b |
| DeepSeek-R1-Distill-Llama-8B | ollama run deepseek-r1:8b |
| DeepSeek-R1-Distill-Qwen-14B | ollama run deepseek-r1:14b |
| DeepSeek-R1-Distill-Qwen-32B | ollama run deepseek-r1:32b |
根据上述表格的提示,仅需遵循相应步骤运行模型。例如,若配置使用2张A100显卡运行7B规模的模型,启动该模型,可执行命令“ollama run deepseek-r1:7b”。
运行示例:

(2) 模型下载国内加速(可选)
如遇原版模型下载速度过慢的情况,可使用由Unsloth AI提供的位于ModelScope的DeepSeek R1蒸馏模型在国内加速下载,运行方式如下:
| 模型名称 | 运行命令 |
| DeepSeek-R1-Distill-Qwen-1.5B | ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF |
| DeepSeek-R1-Distill-Qwen-7B | ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF |
| DeepSeek-R1-Distill-Llama-8B | ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Llama-8B-GGUF |
| DeepSeek-R1-Distill-Qwen-14B | ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF |
| DeepSeek-R1-Distill-Qwen-32B | ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF |
根据上述表格的提示,仅需遵循相应步骤运行模型。例如,若配置使用2张A100显卡运行7B规模的模型,可执行命令“ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF”。
运行示例:
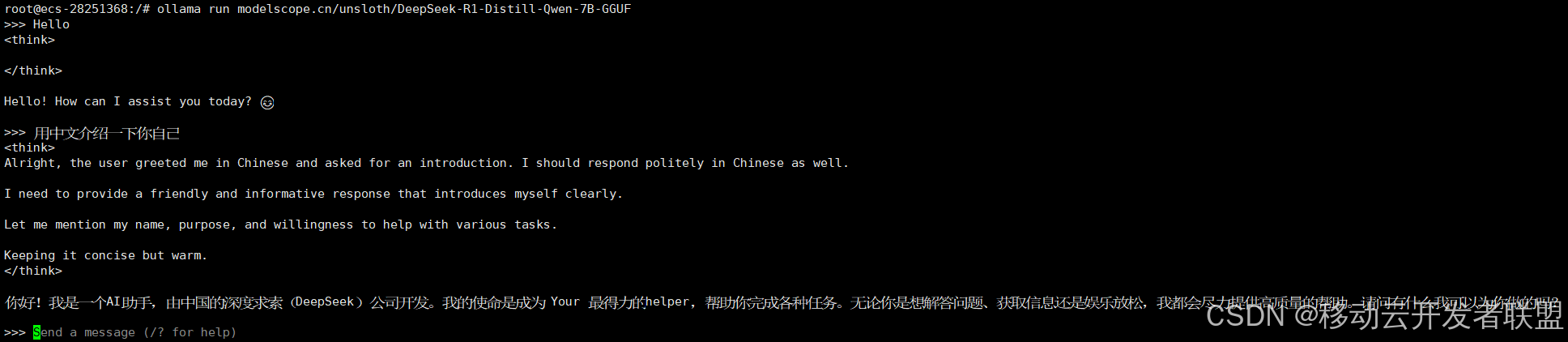
- curl http://localhost:11434/api/generate -d '{"model":"deepseek-r1:7b", "prompt":"用中文介绍下自己"}'
会返回如下结果:
Open-WebUI是一个开源项目,提供了一个类似于ChatGPT的可视化页面,可与Ollama无缝集成。
- 由于Open-WebUI的安装依赖Containerd,以下是Containerd安装步骤:
安装必要的一些系统工具
- apt install apt-transport-https ca-certificates curl gnupg2 software-properties-common
添加证书和仓库地址
- curl -fsSL http://mirrors.cmecloud.cn/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
- echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] http://mirrors.cmecloud.cn/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | tee /etc/apt/sources.list.d/docker.list > /dev/null
安装containerd
- apt install containerd.io
配置 containerd
- mkdir -p /etc/containerd
- containerd config default | tee /etc/containerd/config.toml
安装完成后,使用以下 systemctl 命令启动并启用“containerd”服务
- systemctl start containerd
- systemctl enable containerd
然后,使用以下命令检查并验证containerd 服务。您应该看到containerd服务处于活动状态并正在运行。
- systemctl status containerd

(2)还需要通过nerdctl与Containerd通信,以下是nerdctl的安装步骤:
从Github上下载nerdctl的预编译二进制文件:nerdctl-${VERSION}-linux-amd64.tar.gz
- tar xzvf nerdctl-${VERSION}-linux-amd64.tar.gz -C /usr/local/bin
安装完成后,可以通过以下命令验证nerdctl是否正常工作:
- nerdctl --version
如果安装成功,将显示版本信息:

(3)如果您安装了Ollama,可以使用以下命令:
- ollama serve
- nerdctl run -d --net=host -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -e PORT=8000 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
注意:使用Containerd安装Open-WebUI时,请确保在命令中包含-v open-webui:/app/backend/data。这一步至关重要,因为它确保您的数据库正确挂载,避免任何数据丢失。
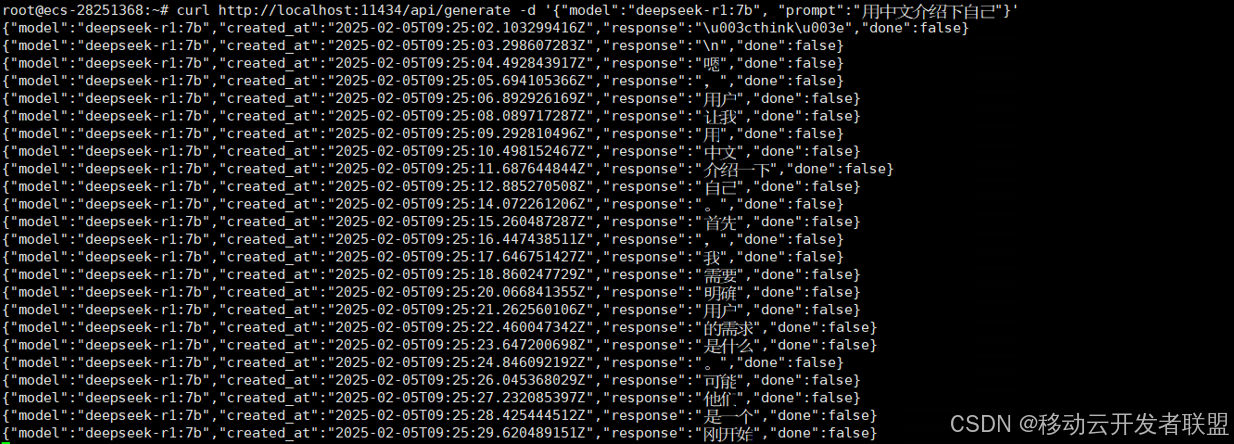
查看容器日志:
- nerdctl logs open-webui
出现以下信息即启动成功:
访问链接:http://<服务器IP或公网IP地址>:8000,出现以下界面,需要注册登录

左上角选择模型后开始对话,示例如下:

ModelScope魔搭社区是一个国内开源的模型即服务共享平台,,Deepseek模型已在其上开源,可通过ModelScope下载。
1.请先通过如下命令安装ModelScope
- pip install modelscope
2.下载完整模型repo到指定目录,如/workspace/models/hf_models,以DeepSeek-R1-Distill-Qwen-7B模型为例,其他模型类似:
- modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir /workspace/models/hf_models/DeepSeek-R1-Distill-Qwen-7B
算力原生平台推理引擎(COCA-Infer)是针对AI全场景推出的推理解决方案,已支持deepseek模型的推理,此示例以英伟达环境为基础,在线下载COCA-Infer镜像文件,支持一键部署。
- 使用镜像前需要安装containerd和nerdctl,可参考1.4节中的安装步骤进行安装
- 加载镜像并创建容器
①加载镜像
- nerdctl load -i <COCA-Infer镜像文件名>
②创建容器
- nerdctl run --privileged --name cocainfer --shm-size=4g --gpus all -it --net=host <COCA-Infer镜像文件名>
③进入容器
- nerdctl exec -it cocainfer /bin/bash
1.注意事项
- 服务器或容器环境上已经安装好必要的驱动、CUDA Toolkit包、lib64-dev等基础库。
- 若开启HTTPS双向认证,需要提前准备好服务证书、服务器私钥和验签证书等。
- COCA Infer目前仅支持Python3.10.x,如果环境中的Python3.10.x不是默认版本,参考如下方法添加环境变量(Python路径根据实际路径进行修改)。
- vim ~/.bashrc
添加如下内容:
- export LD_LIBRARY_PATH=/usr/local/python3.10.12/lib:$LD_LIBRARY_PATH
- export PATH=/usr/local/python3.10.12/bin:$PATH
使更改立即生效
- source ~/.bashrc
1.根据用户需要配置模型仓库
① model-repository文件夹及文件结构示例
/model_repository_ds7b -> 模型仓库路径
├──ds_7b -> 模型名称
│ ├── 1 -> 版本号
│ │ └── model.json -> 模型文件
│ └── config.pbtxt -> 模型配置文件
② config.pbtxt配置示例:
backend: "cocainfer"
# The usage of device is deferred to the coca_vllm engine
instance_group [
{
count: 1
kind: KIND_MODEL
}
]
③model.json配置示例:
{
"model":"/workspace/models/hf_models/DeepSeek-R1-Distill-Qwen-7B",
"disable_log_requests": "true",
"trust_remote_code":"true",
"max_model_len": 4096,
"tensor_parallel_size":1
}
注:参数根据实际情况进行调整,如14B以上模型可启用两张GPU卡,则tensor_parallel_size的值改为2。
2.启动服务,加载DeepSeek模型
- /opt/cocaserver/bin/cocaserver --model-repository=/model_repository_ds7b
回显如下则说明启动成功

3.发送推理请求
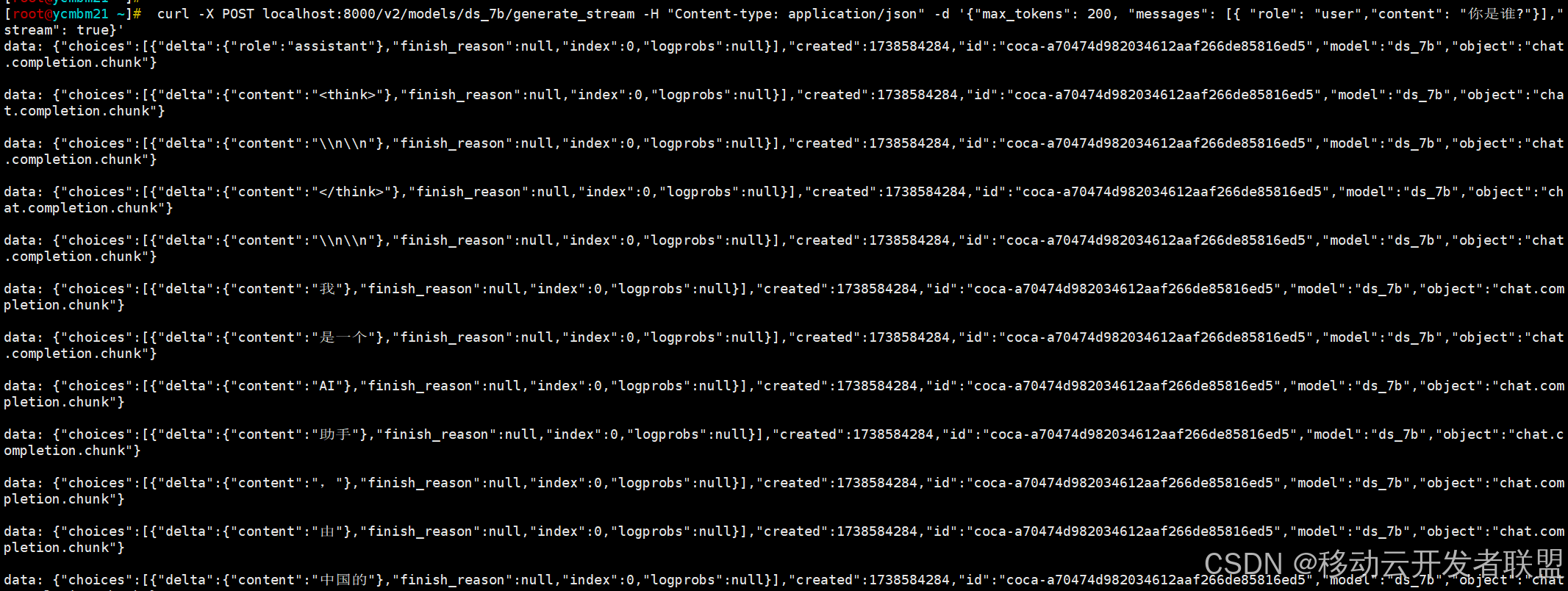
服务器启动成功后,我们可以在shell中发送一个请求进行测试
curl -X POST localhost:8000/v2/models/ds_7b/generate_stream -H "Content-type: application/json" -d '{
"max_tokens": 200,
"messages": [
{
"role": "user",
"content": "你是谁?"
}
],
"stream": true
}'
可以看到返回了如下结果:
如此,便可轻松玩转DeepSeek。


















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









