






大数据生态圈学习--zookeeper
zookeeper介绍
一个分布式的服务协调框架 主要用于协调辅助其他的框架正常的运行
主要为了解决应用系统一致性问题
zk的本质上是一个分布式小文件存储系统 zk上面的每个文件内容最好不要超过1M
分布式:每台机器看到的数据都是一样
ZK在大数据中的应用(我们为什么要学习ZK):
- hadoop2.x通过ZK来实现namenode的HA方案
- hbase的Master通过ZK来实现HA方案。
- kafka使用 ZK 来实现Broker列表的管理。
架构图:
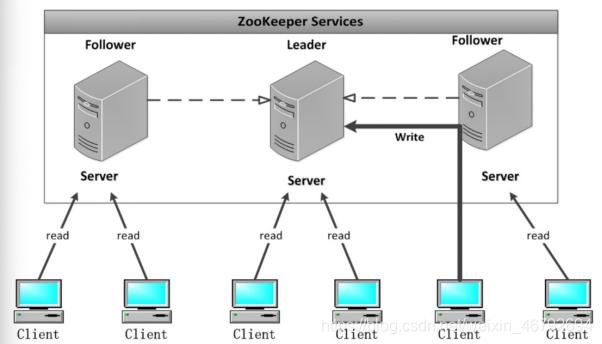
主从架构 :主节点是我们任务分配的节点;从节点,执行任务的节点,主要就是干活的,干主节点分配的活
主备架构:主节点与备份节点,主要用于解决我们主节点挂掉之后,如何选举出来一个新的主节点的问题,保证我们的主节点7*24小时高可用。很多时候,主从与主备没有太明显的分界线,很多时候都是一起出现
ZK Leader节点:ZK 集群工作的核心,事务请求(create, setData, delete) 的唯一调度和处理者,保证集群事务处理的顺序性。
ZK Follower节点:处理客户端非事务( read ) 请求, 转发事务请求给 Leader。参与集群 Leader 选举投票 2n-1台可以做集群投票。
zookeeper的特性:
全局的数据一致性:保证每台机器看到的数据一样
可靠性:如果数据被一台服务器解收,最终会被所有服务器解收
顺序性;如果a消息在b消息之前被处理,那么所有的机器上都是a消息在b消息前
数据更新的原子性:数据更新处理要么成功,要么失败,不存在一半成功,一半失败
实时性:数据的更新在一段时间内最终都会被所有的机器接收成功
三台机器zookeeper的集群环境搭建
ZK集群一般都是奇数台,便于zk内部的投票选举,如下是生产环境的机器个数考虑:
- Zookeeper集群最低是3台。
- 如果协调的服务器在20台以内,ZK的个数是5台。
- 如果是协调服务器是20-50台,ZK的个数是7台。
- 如果是协调服务器是50-100台,ZK的个数是9台。
- 非大型公司,一般不考虑11台以上的ZK集群。
我的集群配置
服务器IP 主机名 myid的值
192.168.1.100 node01 1
192.168.1.110 node02 2
192.168.1.120 node03 3
注意:
Zookeeper 运行需要 java 环境, 所以需要提前安装 jdk,并且设置三台机的时间同步
可以参考另一篇文章
大数据基础环境搭建
第一步:下载zookeeeper的压缩包
http://archive.apache.org/dist/zookeeper/
我使用的zk版本为3.4.9
下载完成之后,上传到我们的linux的/export/softwares路径下准备进行安装
第二步:解压
解压zookeeper的压缩包到/export/servers路径下去,然后准备进行安装
cd /export/softwares
tar -zxvf zookeeper-3.4.9.tar.gz -C ../servers/
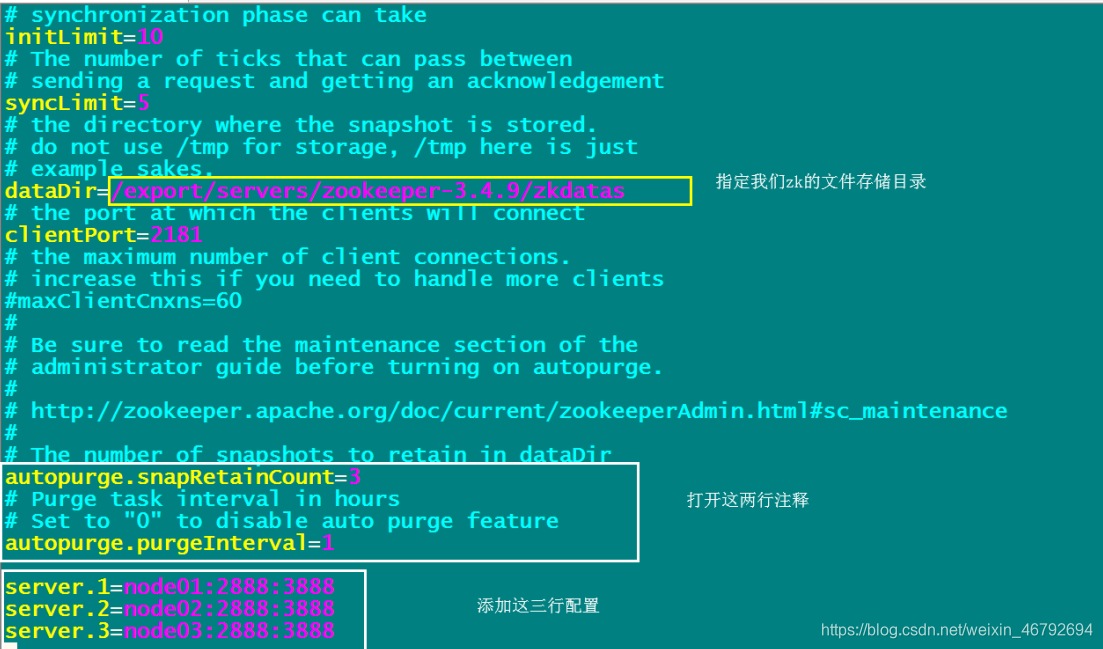
第三步:修改配置文件
第一台机器修改配置文件
cd /export/servers/zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
mkdir -p /export/servers/zookeeper-3.4.9/zkdatas/
vim zoo.cfg
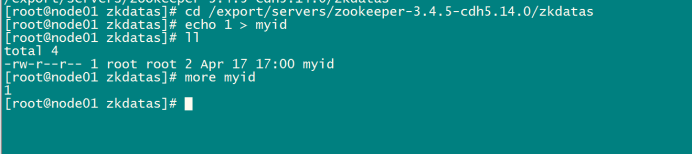
第四步:添加myid配置
在第一台机器的
/export/servers/zookeeper-3.4.9/zkdatas/这个路径下创建一个文件,文件名为myid ,文件内容为1
echo 1 > /export/servers/zookeeper-3.4.9/zkdatas/myid
第五步:安装包分发并修改myid的值
安装包分发到其他机器
第一台机器上面执行以下两个命令
scp -r /export/servers/zookeeper-3.4.9/ node02:/export/servers/
scp -r /export/servers/zookeeper-3.4.9/ node03:/export/servers/
第二台机器上修改myid的值为2
echo 2 > /export/servers/zookeeper-3.4.9/zkdatas/myid
第三台机器上修改myid的值为3
echo 3 > /export/servers/zookeeper-3.4.9/zkdatas/myid
第六步:三台机器启动zookeeper服务
三台机器启动zookeeper服务
这个命令三台机器都要执行
/export/servers/zookeeper-3.4.9/bin/zkServer.sh start
查看启动状态
/export/servers/zookeeper-3.4.9/bin/zkServer.sh status
zookeeper的shell操作
客户端连接:
运行 zkCli.sh –server ip 进入命令行工具。
export/servers/zookeeper-3.4.9/bin/zkServer.sh -server node01
创建节点
create /abc hello # 创建永久的普通节点
create -s /test 123 # 创建永久序列化节点 /test0000000001
create -e /tempnode hello # 创建临时节点【客户端一旦断开连接,临时节点消失】
create -s -e /tempnode hello # 创建序列化的临时节点
读取节点
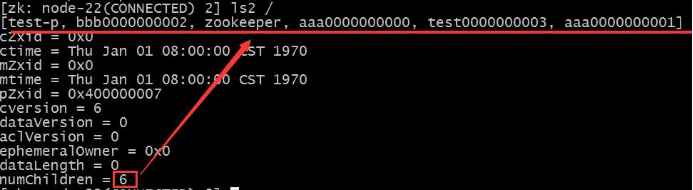
ls path [watch] # 显示该节点下的子节点
ls2 path [watch] # 迭代显示该节点下的子节点
get path [watch] # 获取节点内容
更新节点
set path data [version]
删除节点
delete path [version]
若删除节点存在子节点,那么无法删除该节点,必须先删除子节点,再删除
父节点。
Rmr path
可以递归删除节点。
zookeeper数据类型:
- ZK内部维护一个目录树,树上的每个分支都是一个节点Znode,每个节点下都可以再细分节点(文件夹的特性),并且每个节点还可以存储一定的内容(文件的特性)。
- Znode 具有原子性,对于一个Znode的操作要么成功的要么失败。
- 每个 Znode 都包含了一系列的属性(stat data children),可以通过命令 get 获取。每个Znode存储数据的大小是有限制的,一般KB,最大的可以存储1M左右的数据。
- Znode 有两种,分别为临时节点和永久节点。临时Znode下面不能有子节点,永久Znode下面才可以有子节点。
zookeeper的watch机制:
先订阅再触发,每次触发后,就无法监听了,只能重新注册。
# 客户端A
get /test watch
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/test
get /test watch
hello2
# 客户端B
set /test hello2
zookeeper的javaAPI
ZK还提供了Java的API供用户使用,只是这层原生API 用起来比较麻烦,所以介绍已封装好的curator框架来操作zookeeper。
创建maven java工程,导入jar包
<!-- <repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories> -->
<dependencies>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>com.google.collections</groupId>
<artifactId>google-collections</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- java编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
节点的操作
创建永久节点
、
/**
* 创建永久节点
* @throws Exception
*/
@Test
public void createNode() throws Exception {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 1);
//获取客户端对象
CuratorFramework client = CuratorFrameworkFactory.newClient("node01:2181,node02:2181,node03:2181", 1000, 1000, retryPolicy);
//调用start开启客户端操作
client.start();
//通过create来进行创建节点,并且需要指定节点类型
client.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath("/hello3/world");
client.close();
}
创建临时节点
/**
* 创建临时节点
* @throws Exception
*/
@Test
public void createNode2() throws Exception {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 1);
CuratorFramework client = CuratorFrameworkFactory.newClient("node01:2181,node02:2181,node03:2181", 3000, 3000, retryPolicy);
client.start();
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/hello5/world");
Thread.sleep(5000);
client.close();
}
修改节点数据
/**
* 节点下面添加数据与修改是类似的,一个节点下面会有一个数据,新的数据会覆盖旧的数据
* @throws Exception
*/
@Test
public void nodeData() throws Exception {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 1);
CuratorFramework client = CuratorFrameworkFactory.newClient("node01:2181,node02:2181,node03:2181", 3000, 3000, retryPolicy);
client.start();
client.setData().forPath("/hello5", "hello7".getBytes());
client.close();
}
节点数据查询
/**
* 数据查询
*/
@Test
public void updateNode() throws Exception {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 1);
CuratorFramework client = CuratorFrameworkFactory.newClient("node01:2181,node02:2181,node03:2181", 3000, 3000, retryPolicy);
client.start();
byte[] forPath = client.getData().forPath("/hello5");
System.out.println(new String(forPath));
client.close();
}
节点watch机制
/**
* zookeeper的watch机制
* @throws Exception
*/
@Test
public void watchNode() throws Exception {
RetryPolicy policy = new ExponentialBackoffRetry(3000, 3);
CuratorFramework client = CuratorFrameworkFactory.newClient("node01:2181,node02:2181,node03:2181", policy);
client.start();
// ExecutorService pool = Executors.newCachedThreadPool();
//设置节点的cache
TreeCache treeCache = new TreeCache(client, "/hello5");
//设置监听器和处理过程
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
ChildData data = event.getData();
if(data !=null){
switch (event.getType()) {
case NODE_ADDED:
System.out.println("NODE_ADDED : "+ data.getPath() +" 数据:"+ new String(data.getData()));
break;
case NODE_REMOVED:
System.out.println("NODE_REMOVED : "+ data.getPath() +" 数据:"+ new String(data.getData()));
break;
case NODE_UPDATED:
System.out.println("NODE_UPDATED : "+ data.getPath() +" 数据:"+ new String(data.getData()));
break;
default:
break;
}
}else{
System.out.println( "data is null : "+ event.getType());
}
}
});
//开始监听
treeCache.start();
Thread.sleep(50000000);
}
网络编程的概念
网络互连的不同计算机上运行的程序间可以进行数据交换,网络通信其实就是Socket 间的通信;数据在两个Socket间通过IO传输。
网络通信中的三要素:
1 IP地址
网络中设备的标识
2端口号
用于标识进程的逻辑地址,不同进程的标识
3传输协议
通讯的规则,常见协议:UDP,TCP
UDP:无连接,不可靠,速度快,
应用场景:电视,直播,视频会议
TCP:有连接,可靠,速度慢
应用场景:上传,下载,发邮件

















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









