







 本文详细介绍了SQL查询的基础知识,包括排序查询、聚合函数、分组查询和分页查询等核心概念及其应用实例。
本文详细介绍了SQL查询的基础知识,包括排序查询、聚合函数、分组查询和分页查询等核心概念及其应用实例。
#博学谷IT学习技术支持
前言
个人学习笔记,欢迎指出任何错误,留言意见。
我的文章都将随着个人学习深入而定期更新。
以最简洁的风格,记录概念和方法
上篇文章 https://blog.youkuaiyun.com/weixin_46784189/article/details/126804557?spm=1001.2014.3001.5501
https://blog.youkuaiyun.com/weixin_46784189/article/details/126804557?spm=1001.2014.3001.5501
目录
为了给大家演示查询的语句,我们需要先准备表及一些数据:
本次测试操作的对象表:

建表语句
-- 删除stu表
drop table if exists stu;
-- 创建stu表
CREATE TABLE stu (
id int, -- 编号
name varchar(20), -- 姓名
age int, -- 年龄
sex varchar(5), -- 性别
address varchar(100), -- 地址
math double(5,2), -- 数学成绩
english double(5,2), -- 英语成绩
hire_date date -- 入学时间
);
-- 添加数据
INSERT INTO stu(id,NAME,age,sex,address,math,english,hire_date)
VALUES
(1,'马运',55,'男','杭州',66,78,'1995-09-01'),
(2,'马花疼',45,'女','深圳',98,87,'1998-09-01'),
(3,'马斯克',55,'男','香港',56,77,'1999-09-02'),
(4,'柳白',20,'女','湖南',76,65,'1997-09-05'),
(5,'柳青',20,'男','湖南',86,NULL,'1998-09-01'),
(6,'刘德花',57,'男','香港',99,99,'1998-09-01'),
(7,'张学右',22,'女','香港',99,99,'1998-09-01'),
(8,'德玛西亚',18,'男','南京',56,65,'1994-09-02');
排序查询
语法
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …;上述语句中的排序方式有两种,分别是:
-
ASC : 升序排列 (默认值)
-
DESC : 降序排列
注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
实战
-
查询学生信息,按照年龄升序排列
select * from stu order by age ;
-
查询学生信息,按照数学成绩降序排列
select * from stu order by math desc ;
-
查询学生信息,按照数学成绩降序排列,如果数学成绩一样,再按照英语成绩升序排列
select * from stu order by math desc , english asc ;
聚合函数
概念
==将一列数据作为一个整体,进行纵向计算。==
如何理解呢?假设有如下表
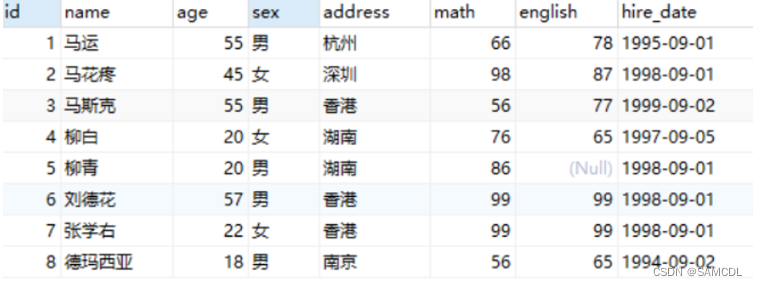
现有一需求让我们求表中所有数据的数学成绩的总和。这就是对math字段进行纵向求和。
聚合函数分类
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
聚合函数语法
SELECT 聚合函数名(列名) FROM 表;注意:null 值不参与所有聚合函数运算
实战
-
统计班级一共有多少个学生
select count(id) from stu; select count(english) from stu;
上面语句根据某个字段进行统计,如果该字段某一行的值为null的话,将不会被统计。所以可以在count(*) 来实现。* 表示所有字段数据,一行中也不可能所有的数据都为null,所以建议使用 count(*)
select count(*) from stu;
-
查询数学成绩的最高分
select max(math) from stu;
-
查询数学成绩的最低分
select min(math) from stu;
-
查询数学成绩的总分
select sum(math) from stu;
-
查询数学成绩的平均分
select avg(math) from stu;
-
查询英语成绩的最低分
select min(english) from stu;
分组查询
语法
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤];注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
实战
-
查询男同学和女同学各自的数学平均分
select sex, avg(math) from stu group by sex;
注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
select name, sex, avg(math) from stu group by sex; -- 这里查询name字段就没有任何意义
-
查询男同学和女同学各自的数学平均分,以及各自人数
select sex, avg(math),count(*) from stu group by sex;
-
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组
select sex, avg(math),count(*) from stu where math > 70 group by sex;
-
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组,分组之后人数大于2个的
select sex, avg(math),count(*) from stu where math > 70 group by sex having count(*) > 2;
where 和 having 区别:
-
执行时机不一样:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
-
可判断的条件不一样:where 不能对聚合函数进行判断,having 可以。
分页查询
如下图所示,大家在很多网站都见过类似的效果,如京东、百度、淘宝等。分页查询是将数据一页一页的展示给用户看,用户也可以通过点击查看下一页的数据。

接下来我们先说分页查询的语法。
语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查询条目数;
注意: 上述语句中的起始索引是从0开始
实战:
-
从0开始查询,查询3条数据
select * from stu limit 0 , 3;
-
每页显示3条数据,查询第1页数据
select * from stu limit 0 , 3;
-
每页显示3条数据,查询第2页数据
select * from stu limit 3 , 3;
-
每页显示3条数据,查询第3页数据
select * from stu limit 6 , 3;
从上面的练习推导出起始索引计算公式:
起始索引 = (当前页码 - 1) * 每页显示的条数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









