







提示:本文仅学习交流使用,以下案例仅供参考。
本文以
面向对象的形式进行编码,利用xpath与正则表达式进行数据解析,将最终结果存入MongoDB数据库中。
一、页面分析
- 首先进入豆瓣《星际穿越》评论页面。https://movie.douban.com/subject/1889243/reviews
- 页面最下方,获取评论的总页数。
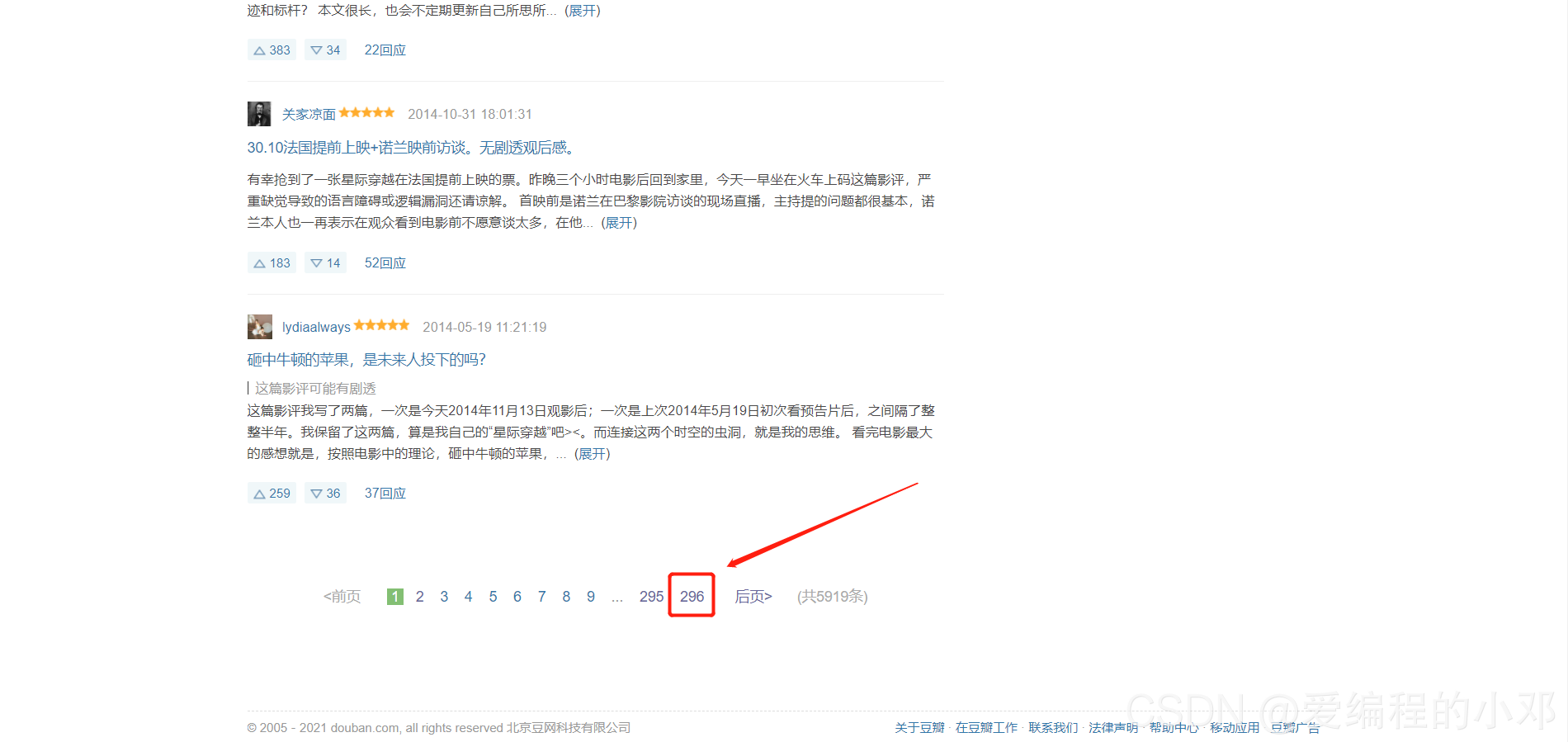
- 通过翻页可以找到以下规律:参数start从0开始,页数+1,start+20。
| 页数 | URL | start |
|---|---|---|
| 1 | https://movie.douban.com/subject/1889243/reviews?start=0 | 0 |
| 2 | https://movie.douban.com/subject/1889243/reviews?start=20 | 20 |
| 3 | https://movie.douban.com/subject/1889243/reviews?start=40 | 40 |
| 4 | https://movie.douban.com/subject/1889243/reviews?start=60 | 60 |
- 通过以上分析可以构造出评论页面的URL,每页页面结构一致,据此可以写出代码。
二、代码实现
注意:请求头的Cookie设置,适当的sleep,MongoDB库表名填写。
# 需要影评具体内容可以将详情页的URL一同爬取,再二次编写爬虫程序。
from pymongo import MongoClient
import random
import requests
from lxml import html
import re
import time
class Spider():
def __init__(self, dbName, collectName, dbHost="localhost", dbPort=27017):
# 评论首页
self.indexUrl = 'https://movie.douban.com/subject/1889243/reviews'
# 评论页模板
self.tempUrl = 'https://movie.douban.com/subject/1889243/reviews?start={}'
# UA池
self.UApool = [
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:68.0) Gecko/20100101 Firefox/68.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:83.0) Gecko/20100101 Firefox/83.0',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)',
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









