







Unet 发表于 2015 年,属于 FCN 的一种变体。Unet 的初衷是为了解决生物医学图像的问题,由于效果确实很好后来也被广泛的应用在语义分割的各个方向,如卫星图像分割,工业瑕疵检测等。
Unet 跟 FCN 都是 Encoder-Decoder 结构,结构简单但很有效。
- Encoder 负责特征提取,可以将各种特征提取网络放在这个位置。
- Decoder 恢复原始分辨率,该过程比较关键的步骤就是 upsampling 与 skip-connection。
Unet主要可分为三部分来看分别为左(特征提取),中(拼接),右(上采样)
- 特征提取部分:它是一个收缩网络,通过四个下采样,使图片尺寸减小,在这不断下采样的过程中,特征提取到的是浅层信息。具体过程是,输入图片然后经过两个卷积核(3x3后面紧跟着一个Relu)以论文原图为例:输入572x572,经过两个卷积核(大小为3x3)大小从572-570-568,然后经过一个Maxpool(2x2)图片尺寸变为284这即为一个完整的下采样,接下来三个也是如此。在下采样的过程中,通道数翻倍,例如图上的从64-128。
- copy and crop拼接:在UNet有四个拼接操作。有人也叫Skip connect,目的是融合特征信息,使深层和浅层的信息融合起来,在拼接的时候要注意,不仅图片大小要一致,特征的维度(channels)也要一样,才可以拼接。
- 上采样部分 up-conv,也叫扩张网络,图片尺寸变大,提取的是深层信息,使用了四个上采样,在上采样的过程中,图片的通道数是减半的,与左部分的特征提取通道数的变化相反。在上采样的过程融合了左边的浅层的信息即拼接了左边的特征。
Upsampling 上采样常用的方式有两种:1.FCN 中介绍的反卷积;2. 插值。
1、反卷积:

①卷积后,结果图像比原图小:称之为valid卷积
②卷积后,结果图像与原图大小相同:称之为same卷积
③卷积后,结果图像比原图大:称之为full卷积
其中,full卷积其实就是反卷积的过程。到这里应该可以意识到,反卷积实际上也是一种特殊的卷积方式,它可以通过full卷积将原图扩大,增大原图的分辨率,所以对图像进行反卷积也称为对图像进行“上采样”。因此,也可以很直接地理解到,图像的卷积和反卷积并不是一个简单的变换、还原过程,也就是先把图片进行卷积,再用同样的卷积核进行反卷积,是不能还原成原图的,因为反卷积后只是单纯地对图片进行扩大处理,并不能还原成原图像。图4所展示的例子可以很好地说明这一现象:
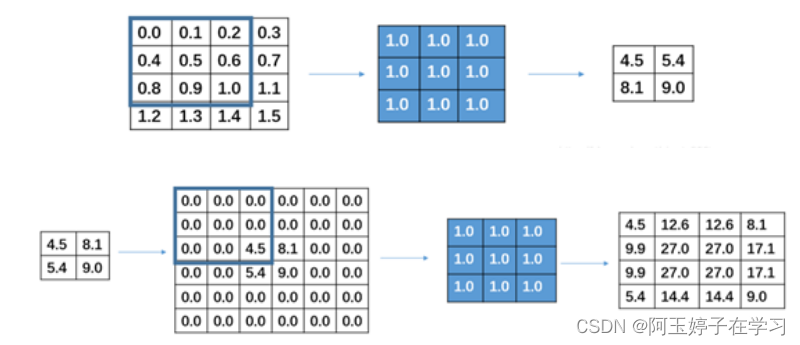
图 卷积(上)与反卷积(下)
由图可见,蓝色是3×3的卷积核,在原图进行卷积和反卷积后,最后得到的图像跟原图是不一致的。因此,通过反卷积并不能还原卷积之前的矩阵,只能从大小上进行还原,因为反卷积的本质还是卷积。如果想要还原成原图像,只能通过专门设计不同的卷积核来实现。
2、插值:bilinear 双线性插值的综合表现较好也较为常见 。双线性插值的计算过程没有需要学习的参数,实际就是套公式。
[补充]
1、U-Net数据输入
由于在不断valid卷积过程中,会使得图片越来越小,为了避免数据丢失,在图像输入前都需要进行镜像扩大,如图所示:
- 可以看到图像在输入前,四个边都进行了镜像扩大操作,以保证在通过一系列的valid卷积操作之后的结果能够与原图大小相一致。
- 由于有些计算机的内存较小,无法直接对整张图片进行处理(医学图像通常都很大),会采取把大图进行分块输入的训练方式,最后将结果一块块拼起来。
- 为了避免在拼接过程中边缘部分出现不连接等问题,在训练前,每一小块都会选择镜像扩大而不是直接补0扩大,以保留更多边缘附近的信息。
2、卷积核中的数值如何确定?
权值的确定一般都是经过“初始化→根据训练结果逐步调整→训练精度达到目标后停止调整→确定权值”这样一个过程,因此U-net卷积核中数值的确定过程也是类似的,一开始也是先用随机数(服从高斯分布)进行初始化,后面则根据前面提到的损失函数逐步对数值进行调整,当训练精度符合要求后停止,即能确定每个卷积核中的数值(即权值)。
而调整卷积核数值的过程,实际上就是U-net的训练过程,当卷积核结束训练确定数值后,则U-net训练完成。
3、U-net训练深度如何确定?
这跟全连接神经网络中“神经网络层数如何确定”这样一个问题是类似的,目前也没有一个专门的标准,一般根据经验选取,或设置多种不同的深度,通过训练效果来选择最优的层数。U-net原文中也没有提到为什么要选择4层,可能是在该训练项目中,4层的分割效果最好。
4、如何解决U-net训练样本少的问题?
医学影像数据存在一个共同的特点,就是样本量一般较少,当训练样本过少时,容易使得训练效果不佳。解决该问题的方法是数据增强,数据增强可以在训练样本较少时,也能够让神经网络学习到更多的数据特征,不同的训练任务,数据增强的方法也不尽相同。由于U-net文章中的任务是分割Hela细胞,作者选择了弹性变换的方式进行数据增强,如图所示:
弹性变换其实就是把原图进行不同的弹性扭曲,形成新的图片,扩大样本量,由于这种弹性变化在细胞中是十分常见的,人为增加这种数据量能够让U-net学习到这种形变的不变性,当遇到新的图像时候可以进行更好地分割。
5、U-net可以如何改进?
①可以对U-net中的损失函数进行改进。损失函数有很多种,U-net原文中采用的是有权重的交叉熵损失函数,主要为了更好地分离粘连在一起的同类细胞设计的,如果分割的任务不同,也可以往损失函数中添加权重或进行其他的改进,以增强分割的准确性和鲁棒性。
②可以对U-net结构进行改进,如采用U-net++网络,如图所示:

U-net++是在深度为4层的U-net基础上,把1~3层的U-net也全部组合到一起(图中左上角最小的三角形为深度为1层的U-net,第二个三角形为深度为2层的U-net,以此类推,把4个深度的U-net组合在一起),这个U-net++能够把每个深度的训练效果相互融合相互补充,可以对图像进行更为精确的分割。
 https://blog.youkuaiyun.com/qq_33924470/article/details/106891015
https://blog.youkuaiyun.com/qq_33924470/article/details/106891015
















 7049
7049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









