






1.3个3*3相较于1个7*7---非线性,参数量
2.3*3和1*1---上下文捕捉很重要
3.分类
- 训练时S=256,S=384
S属于[256,384]
- 测试1.深度
- 2.测试时用固定尺寸,训练时用尺寸抖动的效果优于训练时用固定尺寸
- 3.网络融和效果更佳
4.定位
- SCR,共享回归函数
- PCR,每一类用一个回归函数
- 训练1.损失函数换成欧式距离
- 2.S=256,S=384
- 3.微调所有层还是微调前两个全连接层
- 测试1.PCR,微调所有层效果好
- 2.对整个图像进行密集计算比仅对图像的中心剪裁应用密集计算效果好
- 3.网络融和
0.摘要:
研究:
- 网络深度对识别精度的影响
贡献:
- 对增加深度的网络进行了彻底的评估
- 网络泛化能力好
1.引言
2.网络
所有的网络层用相同的原则进行配置

2.1结构
- 输入尺寸固定为224*224,预处理(per-procession)时计算各通道的均值,然后逐像素减去该均值。
- 用于卷积操作的卷积核尺寸为33,也有11卷积核。
- 卷积步长(stride)固定为1像素,3*3卷积层的填充(padding)为1像素(确保卷积操作后空间分辨率不变)。
- 共计5层max-pooling,跟在某些卷积层之后,最大池化的窗口为2*2,步长为2像素。
- 卷积层之后有3个全连接(FC)层,其中前两层为4096通道,第三个全连接层是1000通道(因为有1000个类别),全连接层的配置相同。
- 最后一层是soft-max层,分类层。
- 除最后一个全连接的分类层以外,所有的权重层用ReLU激活函数。
- 局部响应标准化(LRN)的应用不仅不会有性能的提升,反而会增加内存占用以及计算时间,所以VGG网络中未使用LRN。
2.2配置
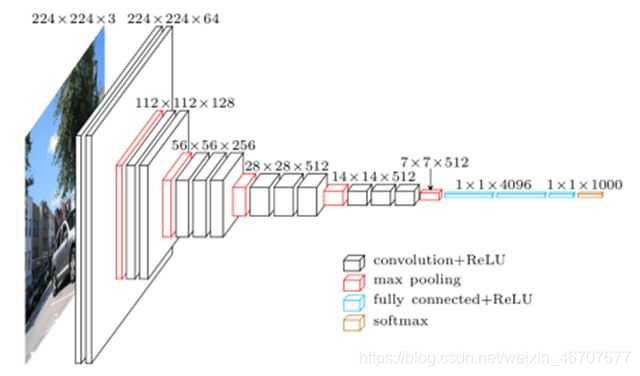
卷积层的通道数64-128-256-512
尽管网络的深度很深,但是网络整体的权重数并不比其他浅层网络的权重数多。
2.3讨论
-
2层33卷积核堆叠后的感受野为55,3层33卷积核堆叠后感受野为77
-
使用1*1卷积的目的是在不改变输入输出维度的情况下,对输入进行线性变换,然后经过relu函数的非线性处理,增加决策函数的非线性。
为什么用33卷积核而不是77的?
- 相较于直接使用77卷积核,使用33卷积核可以带来更多的非线性操作
- 参数量,假设输入输出皆为C层,则3*(33CC)<77CC
- 3*3是最小的可以捕捉相邻像素的尺寸
3分类框架
3.1训练
优化:小批量梯度下降+动量,batch_size=256,momentum=0.9
正则化:权重衰减(weight decay)(L2惩罚系数为5*e-4),前两个全连接层用dropout(p=0.5)
学习率:初始值为0.01,当验证集准确率停止更新时下降10倍
初始化:对A网络进行随机初始化,权重是从N(0 , 0.01)中的采样值,偏差设为0。用A的参数对其余网络的前四个卷积层以及三个全连接层进行初始化,其它中间层随机初始化。
为获得224*224的输入图像,对训练集中的图像进行随机剪裁(crop),然后重新缩放(rescale)使其最小边S>=224。为了对训练集进行数据增强,对剪裁后的数据进行翻转和随机RGB颜色偏移。
多尺度训练。
方案一,用不同的图像尺寸训练两个模型(S=256和S=384),然后在测试时将两个模型的soft-分类分数相结合。首先训练S=256的模型,即,从256N(N>=256)的图像中剪裁出256256的图像。而后,用相似的层配置训练另外一个网络,图像来自于S=384的图像的剪裁。为了加速训练,用S=256的预训练权重进行初始化,学习率e-3.
方案二,[256,512]中随机采样作为调整训练集数据的最小边,即通过尺寸抖动进行数据增强。模型的训练,预训练S=384,然后微调(fine-tuning)该单尺寸模型的所有层。
3.2测试
- 重构测试图像使图像最小边Q>=224 将全连接层用卷积层代替,输出特征图的
输出特征图是分类分数图,分数图的通道数等于分类数,分类分数图的空间分辨率由输入图像的尺寸决定
为了获得固定尺寸的分类分数向量,对分类分数图取平均
3.3细节
4分类实验
Top-1:分类错误的图像的比例
Top-5:真实分类不在top-5分类中的图像的比例
4.1单尺度
固定的S:Q=S
抖动的S:Q=0.5(S min + S max)
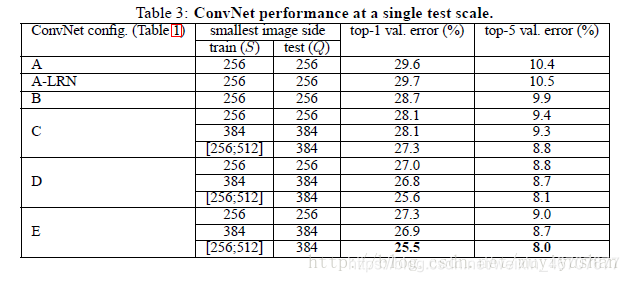
- LRN无明显效果
- 深度增加时分类错误会减少。增加非线性是有帮助(C,B),使用卷积核捕捉空间上下文同样很重要(D,C)
- 即使在测试时使用单尺寸的数据,但是在训练时使用尺度抖动的效果优于在训练时使用固定图像最小边的效果。对训练集进行尺度抖动有利于学习多尺度图像的统计特征
4.2多尺度
多尺度在测试时是影响。即将测试图片缩放成不同的尺寸,在同一网络上运行,然后将分类结果进行取平均。
固定的S:Q={S-32,S,S +32}
抖动的S:Q={S min,0.5(S min+S max),S max}
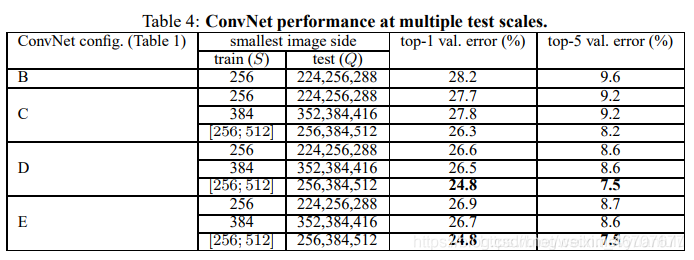
- 测试时使用尺寸抖动会有更好的效果
4.3网络融合
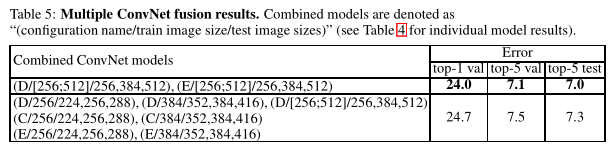 4.4和其他网络的比较
4.4和其他网络的比较
5定位
定位任务可以看做是目标检测的一个特殊例子,为top-5分类中的每一类预测一个边框,不关注该类目标的数目
5.1定位网络
网络的最后一个全连接层用于预测边框的位置,一个边框用一个4D向量表示,存储中心坐标以及宽和高。
边框预测有两种选择:一个回归函数预测所有分类(single-class regression,SCR)(最后一层为4-D),或者每个类有自己的回归函数(per-class regression)(最后一层为4000-D)
训练。S=256和S=384的网络,用对应的分类模型进行初始化,学习率设为e-3。探究微调所有层和仅微调前两个全连接层的效果
测试。考虑两种方案
第一种用于对比不同的网络修改的性能,仅考虑真实分类的边框预测,该边框是把图像的裁剪中心应用于网络获得的
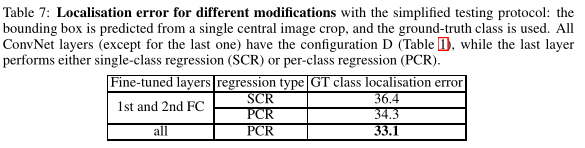
- PCR的性能比SCR好
- 对所有网络层微调的效果优于仅微调前两个全连接层
第二种,在整个图像上密集应用定位网络,与分类任务的不同之处在于,最后一个全连接层用于预测边界框。为了得到最终的预测,运用了OverFeat的greedy merging procedure,即首先合并空间中相近的预测(将坐标平均化),然后基于分类分数进行评估。当有多个定位网络时,首先对预测的边框取并集,然后在并集上运行合并算法。

- 在整个图像上用定位网络性能优于仅在裁剪中心应用
- 多网络融和的性能更好
和其他网络的对比。
6泛化
7总结
- 网络的深度对分类精度很重要
- VGG的泛化能力好

















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









