






 本文详细介绍了Redis的哨兵机制和集群搭建,以解决分片机制的高可用性问题。哨兵系统通过监控、故障检测和自动故障转移确保服务不中断。在SpringBoot中整合哨兵和集群配置,实现数据一致性与服务的高可用。Redis集群通过槽算法保证数据分散存储,并在节点宕机时保持服务持续性。
本文详细介绍了Redis的哨兵机制和集群搭建,以解决分片机制的高可用性问题。哨兵系统通过监控、故障检测和自动故障转移确保服务不中断。在SpringBoot中整合哨兵和集群配置,实现数据一致性与服务的高可用。Redis集群通过槽算法保证数据分散存储,并在节点宕机时保持服务持续性。
1.Redis哨兵机制
1.1 分片机制存在问题
如果redis分片机制其中有一台redis分片宕机,则整个redis分片都不能正常使用,分片机制没有高可用性

1.2 哨兵机制说明
1.2.1 配置哨兵前提
实现redis数据同步,是实现哨兵配置的前提条件。
1.2.2 实现Redis数据同步
复制shards目录到sentinel目录中

删除多余持久化文件

启动三台redis

1.2.3 实现主从挂载
主机:6379
从机:6380
从机:6381
命令:
1.检查节点状态信息 info replication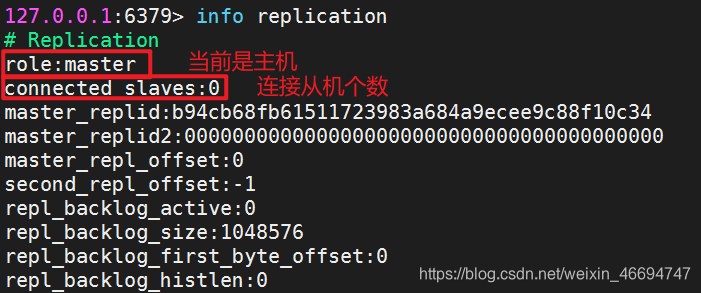
2.主从挂载命令 slaveof 192.168.126.129(内网地址) 6379(端口号)
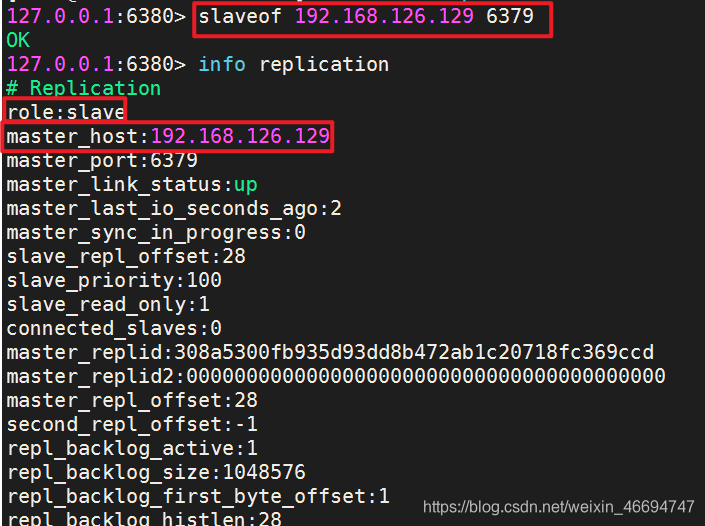
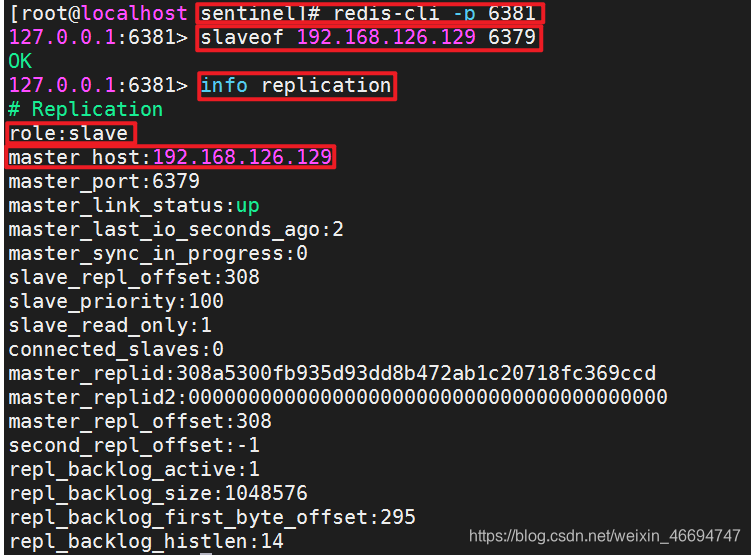
注意:从机不允许写入数据

1.3 实现哨兵高可用性
1.3.1 基本原理
1.当哨兵启动时,动态监控主机,之后利用ping-pong心跳检测机制检查主机是否正常

2.哨兵连接主机之后获取相关主从服务信息,方便以后选举切换
3.当哨兵发现主机宕机,采用随机算法,选择新的主机,并且动态修改原有配置文件,将其他节点当新主机的从机。
1.3.2 复制sentinel.conf文件

1.3.3 修改sentinel.conf文件
1.关闭保护模式
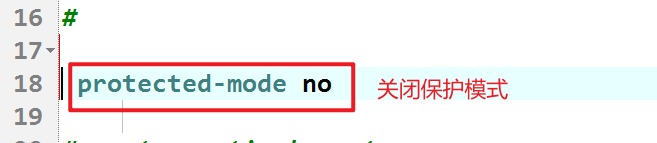
2.开启后端运行

3.设定监控主机

4.哨兵发现主机宕机后的选举时间

1.3.4 哨兵启动测试
1.启动哨兵
redis-sentinel sentinel.conf

检查哨兵启动状态

2.哨兵高可用测试
– 检查redis主机状态
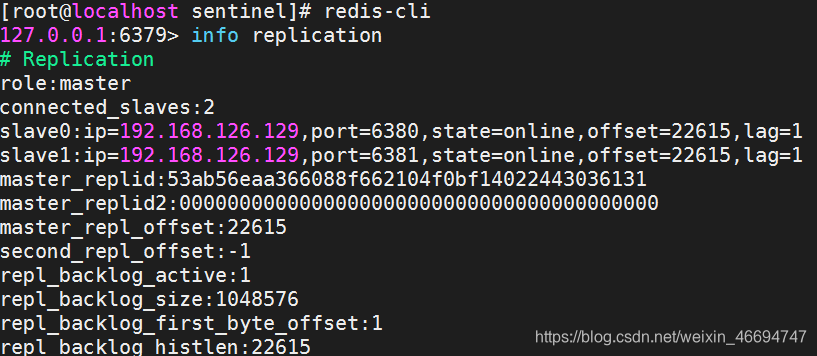
– 关闭redis主机
redis-cli -p 6379 shutdown
– 等待10s 检查从机是否切换为主机
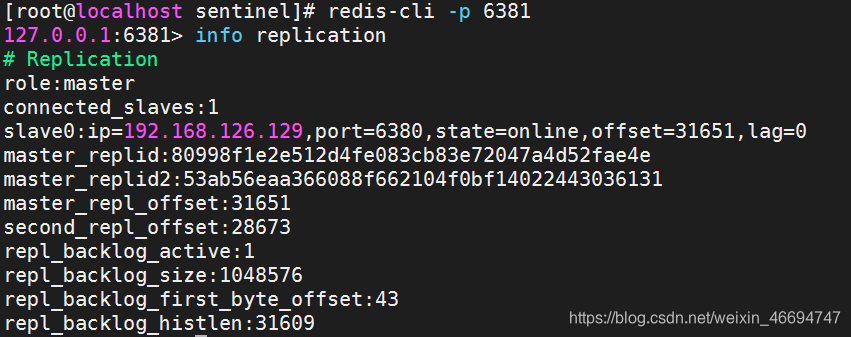
-- 重启主机,检查是否为我们新主机的从

1.3.5 哨兵入门案例
public class RedisTest {
/**
* 实现redis哨兵(sentinel)测试
*/
@Test
public void testSentinel(){
// 1.连接哨兵的集合
Set<String> sentinels = new HashSet<>();
sentinels.add("192.168.126.129:26379");
JedisSentinelPool pool = new JedisSentinelPool("mymaster",sentinels);
Jedis jedis = pool.getResource();//获取资源
jedis.set("aaa", "aaa");
System.out.println(jedis.get("aaa"));
jedis.close();//关闭资源
}
}
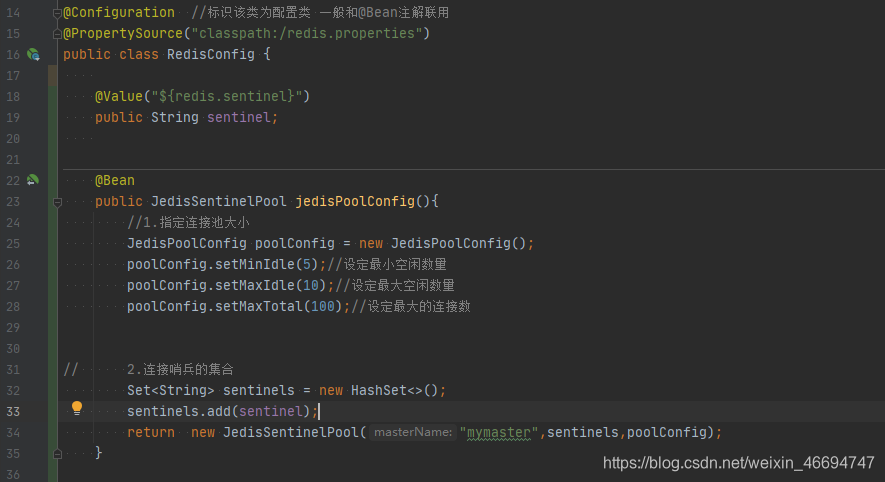
1.4 SpringBoot整合哨兵
1.4.1 编辑pro配置文件
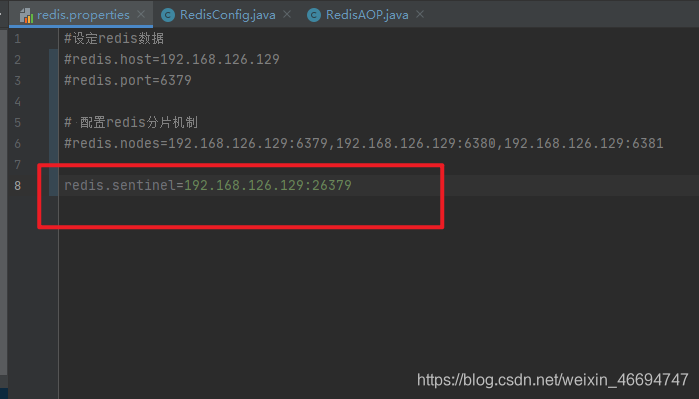
1.4.1 编辑配置类
@Value("${redis.sentinel}")
public String sentinel;
@Bean
public JedisSentinelPool jedisPoolConfig(){
//1.指定连接池大小
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMinIdle(5);//设定最小空闲数量
poolConfig.setMaxIdle(10);//设定最大空闲数量
poolConfig.setMaxTotal(100);//设定最大的连接数
// 2.连接哨兵的集合
Set<String> sentinels = new HashSet<>();
sentinels.add(sentinel);
return new JedisSentinelPool("mymaster",sentinels,poolConfig);
}
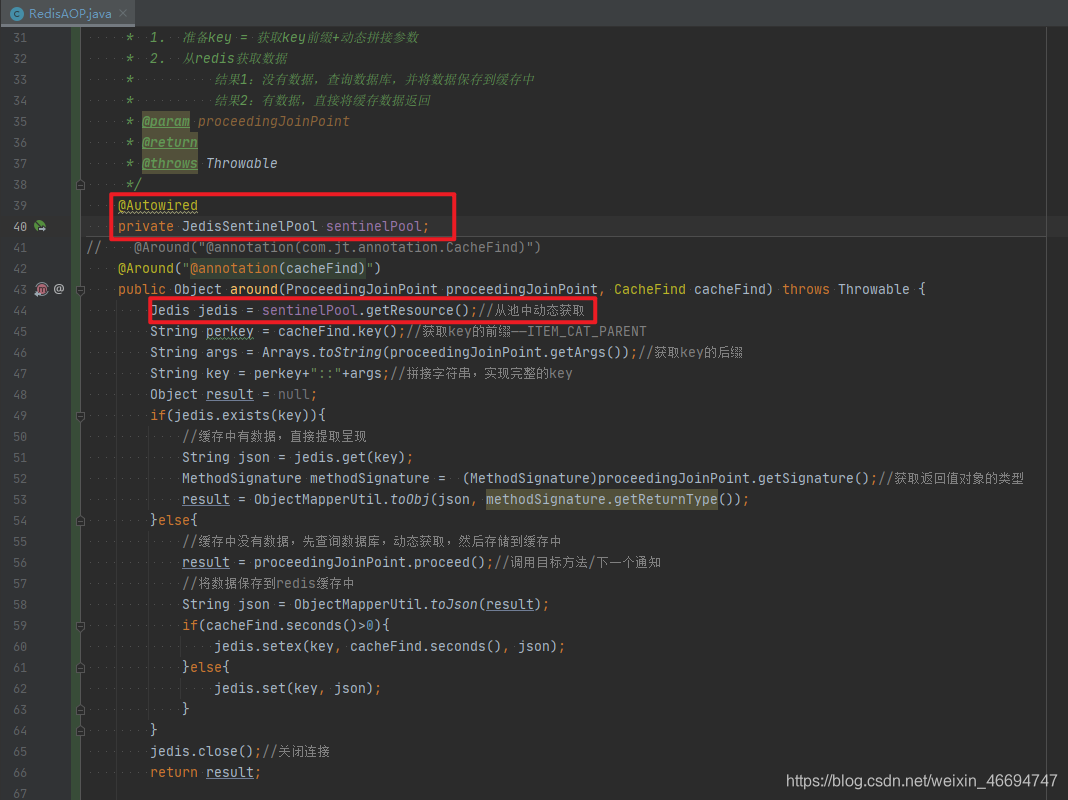
1.4.1 编辑redisAOP配置类
@Component //交给spring管理
@Aspect //标识AOP切面类
public class RedisAOP {
@Autowired
private JedisSentinelPool sentinelPool;
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint proceedingJoinPoint, CacheFind cacheFind) throws Throwable {
Jedis jedis = sentinelPool.getResource();//从池中动态获取
String perkey = cacheFind.key();//获取key的前缀——ITEM_CAT_PARENT
String args = Arrays.toString(proceedingJoinPoint.getArgs());//获取key的后缀
String key = perkey+"::"+args;//拼接字符串,实现完整的key
Object result = null;
if(jedis.exists(key)){
//缓存中有数据,直接提取呈现
String json = jedis.get(key);
MethodSignature methodSignature = (MethodSignature)proceedingJoinPoint.getSignature();//获取返回值对象的类型
result = ObjectMapperUtil.toObj(json, methodSignature.getReturnType());
}else{
//缓存中没有数据,先查询数据库,动态获取,然后存储到缓存中
result = proceedingJoinPoint.proceed();//调用目标方法/下一个通知
//将数据保存到redis缓存中
String json = ObjectMapperUtil.toJson(result);
if(cacheFind.seconds()>0){
jedis.setex(key, cacheFind.seconds(), json);
}else{
jedis.set(key, json);
}
}
jedis.close();//关闭连接
return result;
}
1.5 Redis分片哨兵机制总结
1.分片主要实现了内存扩容, 没有高可用的效果.
2.哨兵主要实现了高可用效果, 没有实现内存数据的扩容. 哨兵本身没有高可用的效果.
如何优化: 实现内存扩容,节点实现高可用 用redis集群来实现
2. Redis集群搭建
2.1 为什么使用Redis集群
通常,为了提高网站响应速度,总是把热点数据保存在内存中而不是直接从后端数据库中读取。
Redis是一个很好的Cache工具。大型网站应用,热点数据量往往巨大,几十G上百G是很正常的事儿。
由于内存大小的限制,使用一台 Redis 实例显然无法满足需求,这时就需要使用多台 Redis作为缓存数据库。但是如何保证数据存储的一致性呢,这时就需要搭建redis集群.采用合理的机制,保证用户的正常的访问需求.
采用redis集群,可以保证数据分散存储,同时保证数据存储的一致性.并且在内部实现高可用的机制.实现了服务故障的自动迁移.
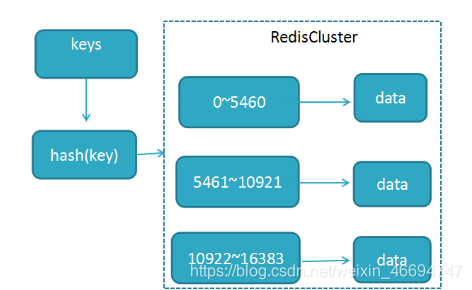
2.2 Redis分区算法(槽算法)
RedisCluster采用分区算法,所有的键根据哈希函数(CRC16[key]%16384)映射到0-16383槽内,共16384个槽位,每个节点维护部分槽及槽所映射的键值数据.根据主节点的个数,均衡划分区间.
- 算法:哈希函数: Hash()=CRC16[key]%16384
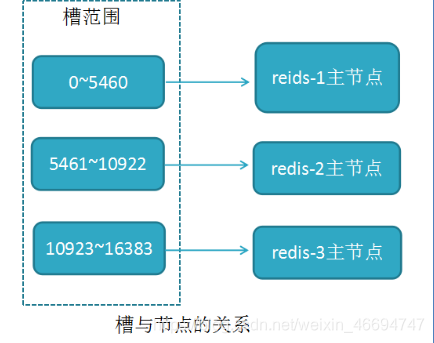
- 当向redis集群中插入数据时,首先将key进行计算.之后将计算结果匹配到具体的某一个槽的区间内,之后再将数据set到管理该槽的节点中.
2.3 Redis集群宕机条件
当集群主机缺失的时候就会发生集群宕机
特点:集群中如果主机宕机,那么从机可以继续提供服务,
当主机中没有从机时,则向其它主机借用多余的从机.继续提供服务.如果主机宕机时没有从机可用,则集群崩溃
-如果有1主1从3组组成redis集群,那么redis节点至少宕机几台,集群会崩溃? 2台
-如果有1主2从3组组成redis集群,那么redis节点至少宕机几台,集群会崩溃? 5台
2.4 SpringBoot整合Redis集群
2.4.1 编辑pro配置文件
redis.hostAndPort=192.168.126.129:7000,192.168.126.129:7001,192.168.126.129:7002,192.168.126.129:7003,192.168.126.129:7004,192.168.126.129:7005
2.4.2 修改配置类
@Configuration //标识该类为配置类 一般和@Bean注解联用
@PropertySource("classpath:/redis.properties")
public class RedisConfig {
@Value("${redis.hostAndPort}")
public String hostAndPort;
@Bean
public JedisCluster jedisCluster(){
Set<HostAndPort> nodes = new HashSet<>();
String[] hostPorts = hostAndPort.split(",");
for(String hostPort : hostPorts){
String host = hostPort.split(":")[0];
int port = Integer.parseInt(hostPort.split(":")[1]);
nodes.add(new HostAndPort(host,port));
}
return new JedisCluster(nodes);
}
}
2.4.3 修改redisAOP类
@Component //交给spring管理
@Aspect //标识AOP切面类
public class RedisAOP {
@Autowired
private JedisCluster jedis;
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint proceedingJoinPoint, CacheFind cacheFind) throws Throwable {
String perkey = cacheFind.key();//获取key的前缀——ITEM_CAT_PARENT
String args = Arrays.toString(proceedingJoinPoint.getArgs());//获取key的后缀
String key = perkey+"::"+args;//拼接字符串,实现完整的key
Object result = null;
if(jedis.exists(key)){
//缓存中有数据,直接提取呈现
String json = jedis.get(key);
MethodSignature methodSignature = (MethodSignature)proceedingJoinPoint.getSignature();//获取返回值对象的类型
result = ObjectMapperUtil.toObj(json, methodSignature.getReturnType());
}else{
//缓存中没有数据,先查询数据库,动态获取,然后存储到缓存中
result = proceedingJoinPoint.proceed();//调用目标方法/下一个通知
//将数据保存到redis缓存中
String json = ObjectMapperUtil.toJson(result);
if(cacheFind.seconds()>0){
jedis.setex(key, cacheFind.seconds(), json);
}else{
jedis.set(key, json);
}
}
return result;
}
2.5 有关redis的FAQ
2.5.1 集群FAQ
- Redis集群中由于有16384个槽位,所有redis集群中只能存储16384个key?
不是,分区只是区分数据归谁管理 到底能存储多少由Redis内存大小决定 - 过redis-cli -p 端口号 链接任意的节点都可以执行set操作?
不可以,从库不可以能写入数据 - 通过redis-cli -p 端口号 连接任意的主机都可以执行set操作?
不可以,数据的存储严格按照分区算法完成 - .redis集群一旦搭建,如果redis节点全部关机再次重启时,需要重新搭建集群?
不用,在文件nodes.conf中包含集群状态的配置文件信息,重启之后会自动恢复


















 242
242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











