







简介
【摘要】加速矩阵乘法计算在人工智能时代具重要意义.本文定义了矩阵乘法的基准算法,介绍了降低算法理论复杂度、线程级和数据级并行计算等多种加速方式,并实现利用程序访问内存的局部性、Strassen算法、线程级并行和数据级并行的多种加速计算的程序.实验证明行优先访问矩阵对提高高速缓存命中率的显著作用,多线程和向量指令能有效加速矩阵乘法计算.然后,本文将4线程并行、向量指令、行优先访问几种优化方式结合,实验结果证明这几种方法协同作用在大规模矩阵运算上,加速比可达50以上.最后,本文实现并评估GPU加速矩阵乘法,并拆解分析其主要的性能开销.实验结果表明GPU程序能更显著地加速矩阵乘法计算,其开销主要来源于乘法计算.
【关键词】矩阵乘法;并行计算;POSIX线程;单指令多数据(SIMD);Strassen算法;高速缓存
源代码和论文详见Github仓库,包括所有的实验代码和中文研究论文,欢迎参考.
关键代码
本项目配有Makefile,完成3个程序的构建:
singlethread.cmultithread.ccuda.cu
需要注意,
singlethread.c要运行在支持avx-256的x86硬件;cuda.cu要求机器带有英伟达显卡,使用nvcc编译器编译。
Makefile
all: singlethread multithread cuda
singlethread:singlethread.c
gcc -mavx -fno-tree-vectorize singlethread.c -O0 -o singlethread
multithread:multithread.c
gcc -mavx -fno-tree-vectorize multithread.c -O0 -o multithread
cuda:cuda.cu
nvcc -O0 cuda.cu -o cuda
clean:
rm -rf singlethread multithread cuda
单线程程序(singlethread.c)
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <immintrin.h>
#include <stdbool.h>
void matrix_multiply(float **A, float **B, float **C, int n, int m, int p)
{
for (int i = 0; i < n; i++)
for (int j = 0; j < p; j++)
{
C[i][j] = 0;
for (int k = 0; k < m; k++)
{
C[i][j] += A[i][k] * B[k][j];
}
}
}
void matrix_multiply_line_first(float **A, float **B, float **C, int n, int m, int p)
{
for (int i = 0; i < n; i++)
for (int j = 0; j < p; j++)
{
C[i][j] = 0;
for (int k = 0; k < m; k++)
{
C[i][j] += A[i][k] * B[j][k];
}
}
}
// 传入的第二个矩阵应该先转置
void matrix_multiply_maxv_line_first(float **A, float **B, float **C, int N, int M, int P)
{
__m256 ymm0, ymm1, ymm2, ymm3, ymm4, ymm5, ymm6, ymm7,
ymm8, ymm9, ymm10, ymm11, ymm12, ymm13, ymm14, ymm15;
float scratchpad[8];
int col_reduced = M - M % 64;
int col_reduced_32 = M - M % 32;
for (int i = 0; i < N; i++)
{
for (int j = 0; j < P; j++)
{
float res = 0;
for (int k = 0; k < col_reduced; k += 64)
{
// ymm 8 - 15 装载 B[j] 列
ymm8 = __builtin_ia32_loadups256(&B[j][k]);
ymm9 = __builtin_ia32_loadups256(&B[j][k + 8]);
ymm10 = __builtin_ia32_loadups256(&B[j][k + 16]);
ymm11 = __builtin_ia32_loadups256(&B[j][k + 24]);
ymm12 = __builtin_ia32_loadups256(&B[j][k + 32]);
ymm13 = __builtin_ia32_loadups256(&B[j][k + 40]);
ymm14 = __builtin_ia32_loadups256(&B[j][k + 48]);
ymm15 = __builtin_ia32_loadups256(&B[j][k + 56]);
// ymm 0 - 7 装载 A[i] 行
ymm0 = __builtin_ia32_loadups256(&A[i][k]);
ymm1 = __builtin_ia32_loadups256(&A[i][k + 8]);
ymm2 = __builtin_ia32_loadups256(&A[i][k + 16]);
ymm3 = __builtin_ia32_loadups256(&A[i][k + 24]);
ymm4 = __builtin_ia32_loadups256(&A[i][k + 32]);
ymm5 = __builtin_ia32_loadups256(&A[i][k + 40]);
ymm6 = __builtin_ia32_loadups256(&A[i][k + 48]);
ymm7 = __builtin_ia32_loadups256(&A[i][k + 56]);
// A[i][] * B[][j]
ymm0 = __builtin_ia32_mulps256(ymm0, ymm8);
ymm1 = __builtin_ia32_mulps256(ymm1, ymm9);
ymm2 = __builtin_ia32_mulps256(ymm2, ymm10);
ymm3 = __builtin_ia32_mulps256(ymm3, ymm11);
ymm4 = __builtin_ia32_mulps256(ymm4, ymm12);
ymm5 = __builtin_ia32_mulps256(ymm5, ymm13);
ymm6 = __builtin_ia32_mulps256(ymm6, ymm14);
ymm7 = __builtin_ia32_mulps256(ymm7, ymm15);
// 对 ymm0-ymm7求和得结果
ymm0 = __builtin_ia32_addps256(ymm0, ymm1);
ymm2 = __builtin_ia32_addps256(ymm2, ymm3);
ymm4 = __builtin_ia32_addps256(ymm4, ymm5);
ymm6 = __builtin_ia32_addps256(ymm6, ymm7);
ymm0 = __builtin_ia32_addps256(ymm0, ymm2);
ymm4 = __builtin_ia32_addps256(ymm4, ymm6);
ymm0 = __builtin_ia32_addps256(ymm0, ymm4);
__builtin_ia32_storeups256(scratchpad, ymm0);
for (int k = 0; k < 8; k++)
res += scratchpad[k];
}
// 剩余部分
for (int l = col_reduced; l < col_reduced_32; l += 32)
{
ymm8 = __builtin_ia32_loadups256(&B[j][l]);
ymm9 = __builtin_ia32_loadups256(&B[j][l + 8]);
ymm10 = __builtin_ia32_loadups256(&B[j][l + 16]);
ymm11 = __builtin_ia32_loadups256(&B[j][l + 24]);
ymm0 = __builtin_ia32_loadups256(&A[i][l]);
ymm1 = __builtin_ia32_loadups256(&A[i][l + 8]);
ymm2 = __builtin_ia32_loadups256(&A[i][l + 16]);
ymm3 = __builtin_ia32_loadups256(&A[i][l + 24]);
ymm0 = __builtin_ia32_mulps256(ymm0, ymm8);
ymm1 = __builtin_ia32_mulps256(ymm1, ymm9);
ymm2 = __builtin_ia32_mulps256(ymm2, ymm10);
ymm3 = __builtin_ia32_mulps256(ymm3, ymm11);
ymm0 = __builtin_ia32_addps256(ymm0, ymm1);
ymm2 = __builtin_ia32_addps256(ymm2, ymm3);
ymm0 = __builtin_ia32_addps256(ymm0, ymm2);
__builtin_ia32_storeups256(scratchpad, ymm0);
for (int k = 0; k < 8; k++)
res += scratchpad[k];
}
for (int l = col_reduced_32; l < M; l++)
{
res += A[i][l] * B[j][l];
}
C[i][j] = res;
}
}
}
void matrix_print(float **M, int n, int m)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
printf("%f ", M[i][j]);
}
putchar('\n');
}
}
float **matrix_malloc(int n, int m)
{
float **M;
M = (float **)malloc(sizeof(float *) * n);
for (int i = 0; i < n; ++i)
{
M[i] = (float *)malloc(sizeof(float) * m);
for (int j = 0; j < m; ++j)
M[i][j] = 0;
}
return M;
}
float **matrix_free(float **M, int n)
{
for (int i = 0; i < n; i++)
{
free(M[i]);
}
free(M);
}
void matrix_init(float **M, int n, int m)
{
for (int i = 0; i < n; ++i)
{
for (int j = 0; j < m; ++j)
{
M[i][j] = rand() % 10;
}
}
}
void matrix_zero(float **M, int n, int m)
{
for (int i = 0; i < n; ++i)
{
for (int j = 0; j < m; ++j)
{
M[i][j] = 0;
}
}
}
float **matrix_extend(float **oldM, int old_n, int old_m, int new_size)
{
float **newM = matrix_malloc(new_size, new_size);
for (int i = 0; i < old_n; ++i)
{
for (int j = 0; j < old_m; ++j)
{
newM[i][j] = oldM[i][j];
}
}
return newM;
}
float **matrix_transpose(float **M, int n, int m)
{
float **T = matrix_malloc(m, n);
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
T[j][i] = M[i][j];
return T;
}
void ADD(float **A, float **B, float **C, int size)
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
C[i][j] = A[i][j] + B[i][j];
}
}
}
void SUB(float **A, float **B, float **C, int size)
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
C[i][j] = A[i][j] - B[i][j];
}
}
}
void FillMatrix(float **A, float **B, int size) // 给A、B矩阵赋初值
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
A[i][j] = rand();
B[i][j] = rand();
}
}
}
void StrassenMul(float **A, float **B, float **C, int size)
{
if (size == 1)
{
C[0][0] = A[0][0] * B[0][0];
}
else
{
int half_size = size / 2;
float **A11 = (float **)malloc(sizeof(float *) * half_size);
float **A12 = (float **)malloc(sizeof(float *) * half_size);
float **A21 = (float **)malloc(sizeof(float *) * half_size);
float **A22 = (float **)malloc(sizeof(float *) * half_size);
float **B11 = (float **)malloc(sizeof(float *) * half_size);
float **B12 = (float **)malloc(sizeof(float *) * half_size);
float **B21 = (float **)malloc(sizeof(float *) * half_size);
float **B22 = (float **)malloc(sizeof(float *) * half_size);
float **C11 = (float **)malloc(sizeof(float *) * half_size);
float **C12 = (float **)malloc(sizeof(float *) * half_size);
float **C21 = (float **)malloc(sizeof(float *) * half_size);
float **C22 = (float **)malloc(sizeof(float *) * half_size);
float **M1 = (float **)malloc(sizeof(float *) * half_size);
float **M2 = (float **)malloc(sizeof(float *) * half_size);
float **M3 = (float **)malloc(sizeof(float *) * half_size);
float **M4 = (float **)malloc(sizeof(float *) * half_size);
float **M5 = (float **)malloc(sizeof(float *) * half_size);
float **M6 = (float **)malloc(sizeof(float *) * half_size);
float **M7 = (float **)malloc(sizeof(float *) * half_size);
float **MatrixTemp1 = (float **)malloc(sizeof(float *) * half_size);
float **MatrixTemp2 = (float **)malloc(sizeof(float *) * half_size);
for (int i = 0; i < half_size; i++)
{
A11[i] = (float *)malloc(sizeof(float) * half_size);
A12[i] = (float *)malloc(sizeof(float) * half_size);
A21[i] = (float *)malloc(sizeof(float) * half_size);
A22[i] = (float *)malloc(sizeof(float) * half_size);
B11[i] = (float *)malloc(sizeof(float) * half_size);
B12[i] = (float *)malloc(sizeof(float) * half_size);
B21[i] = (float *)malloc(sizeof(float) * half_size);
B22[i] = (float *)malloc(sizeof(float) * half_size);
C11[i] = (float *)malloc(sizeof(float) * half_size);
C12[i] = (float *)malloc(sizeof(float) * half_size);
C21[i] = (float *)malloc(sizeof(float) * half_size);
C22[i] = (float *)malloc(sizeof(float) * half_size);
M1[i] = (float *)malloc(sizeof(float) * half_size);
M2[i] = (float *)malloc(sizeof(float) * half_size);
M3[i] = (float *)malloc(sizeof(float) * half_size);
M4[i] = (float *)malloc(sizeof(float) * half_size);
M5[i] = (float *)malloc(sizeof(float) * half_size);
M6[i] = (float *)malloc(sizeof(float) * half_size);
M7[i] = (float *)malloc(sizeof(float) * half_size);
MatrixTemp1[i] = (float *)malloc(sizeof(float) * half_size);
MatrixTemp2[i] = (float *)malloc(sizeof(float) * half_size);
}
for (int i = 0; i < half_size; i++)
{
for (int j = 0; j < half_size; j++)
{
A11[i][j] = A[i][j];
A12[i][j] = A[i][j + half_size];
A21[i][j] = A[i + half_size][j];
A22[i][j] = A[i + half_size][j + half_size];
B11[i][j] = B[i][j];
B12[i][j] = B[i][j + half_size];
B21[i][j] = B[i + half_size][j];
B22[i][j] = B[i + half_size][j + half_size];
}
}
// calculate M1
ADD(A11, A22, MatrixTemp1, half_size);
ADD(B11, B22, MatrixTemp2, half_size);
StrassenMul(MatrixTemp1, MatrixTemp2, M1, half_size);
// calculate M2
ADD(A21, A22, MatrixTemp1, half_size);
StrassenMul(MatrixTemp1, B11, M2, half_size);
// calculate M3
SUB(B12, B22, MatrixTemp1, half_size);
StrassenMul(A11, MatrixTemp1, M3, half_size);
// calculate M4
SUB(B21, B11, MatrixTemp1, half_size);
StrassenMul(A22, MatrixTemp1, M4, half_size);
// calculate M5
ADD(A11, A12, MatrixTemp1, half_size);
StrassenMul(MatrixTemp1, B22, M5, half_size);
// calculate M6
SUB(A21, A11, MatrixTemp1, half_size);
ADD(B11, B12, MatrixTemp2, half_size);
StrassenMul(MatrixTemp1, MatrixTemp2, M6, half_size);
// calculate M7
SUB(A12, A22, MatrixTemp1, half_size);
ADD(B21, B22, MatrixTemp2, half_size);
StrassenMul(MatrixTemp1, MatrixTemp2, M7, half_size);
// C11
ADD(M1, M4, C11, half_size);
SUB(C11, M5, C11, half_size);
ADD(C11, M7, C11, half_size);
// C12
ADD(M3, M5, C12, half_size);
// C21
ADD(M2, M4, C21, half_size);
// C22
SUB(M1, M2, C22, half_size);
ADD(C22, M3, C22, half_size);
ADD(C22, M6, C22, half_size);
for (int i = 0; i < half_size; i++)
{
for (int j = 0; j < half_size; j++)
{
C[i][j] = C11[i][j];
C[i][j + half_size] = C12[i][j];
C[i + half_size][j] = C21[i][j];
C[i + half_size][j + half_size] = C22[i][j];
}
}
for (int i = 0; i < half_size; i++)
{
free(A11[i]);
free(A12[i]);
free(A21[i]);
free(A22[i]);
free(B11[i]);
free(B12[i]);
free(B21[i]);
free(B22[i]);
free(C11[i]);
free(C12[i]);
free(C21[i]);
free(C22[i]);
free(M1[i]);
free(M2[i]);
free(M3[i]);
free(M4[i]);
free(M5[i]);
free(M6[i]);
free(M7[i]);
free(MatrixTemp1[i]);
free(MatrixTemp2[i]);
}
free(A11);
free(A12);
free(A21);
free(A22);
free(B11);
free(B12);
free(B21);
free(B22);
free(C11);
free(C12);
free(C21);
free(C22);
free(M1);
free(M2);
free(M3);
free(M4);
free(M5);
free(M6);
free(M7);
free(MatrixTemp1);
free(MatrixTemp2);
}
}
int get_extended_size(int n)
{
int power = 1;
while (power < n) {
power *= 2;
}
return power;
}
int main(int argc, char *argv[])
{
int n, m, p;
if (argc == 2)
{
n = m = p = atoi(argv[1]);
}
else if (argc == 4)
{
n = atoi(argv[1]);
m = atoi(argv[2]);
p = atoi(argv[3]);
}
else
{
printf("Help:\n");
printf("./singlethread n\n");
printf("./singlethread n m p\n");
return 0;
}
float **A = matrix_malloc(n, m);
if (!A)
{
perror("matrix_malloc()");
}
float **B = matrix_malloc(m, p);
if (!B)
{
perror("matrix_malloc()");
}
float **C = matrix_malloc(n, p);
if (!C)
{
perror("matrix_malloc()");
}
matrix_init(A, n, m);
matrix_init(B, m, p);
printf("串行程序运行结果:\n");
clock_t t1 = clock();
matrix_multiply(A, B, C, n, m, p);
clock_t t2 = clock();
printf("基准算法用时:%lf\n", 1.0 * (t2 - t1) / CLOCKS_PER_SEC);
matrix_print(C, n, p);
clock_t t3 = clock();
float **T = matrix_transpose(B, m, p);
if (!T)
{
perror("matrix_transpose()");
}
matrix_multiply_line_first(A, T, C, n, m, p);
clock_t t4 = clock();
printf("行优先乘法用时:%lf\n", 1.0 * (t4 - t3) / CLOCKS_PER_SEC);
matrix_print(C, n, p);
// clock_t t5 = clock();
// matrix_multiply_maxv(A, B, C, n, m, p);
// clock_t t6 = clock();
// printf("向量化乘法用时:%lf\n", 1.0 * (t6 - t5) / CLOCKS_PER_SEC);
// matrix_print(C, n, p);
clock_t t7 = clock();
T = matrix_transpose(B, m, p);
if (!T)
{
perror("matrix_transpose()");
}
matrix_multiply_maxv_line_first(A, T, C, n, m, p);
clock_t t8 = clock();
printf("向量化乘法+行优先用时:%lf\n", 1.0 * (t8 - t7) / CLOCKS_PER_SEC);
matrix_print(C, n, p);
int n1 = get_extended_size(n);
int m1 = get_extended_size(m);
int p1 = get_extended_size(p);
int size = n1 > m1 ? n1 : m1;
size = size > p1 ? size : p1;
float **AE = matrix_extend(A, n, m, size);
float **BE = matrix_extend(B, m, p, size);
float **CE = matrix_malloc(size, size);
clock_t t9 = clock();
StrassenMul(AE, BE, CE, size);
clock_t t10 = clock();
printf("Strassen算法用时:%lf\n", 1.0 * (t10 - t9) / CLOCKS_PER_SEC);
matrix_print(CE, n, p);
return 0;
}
多线程程序(multithread.c)
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <pthread.h>
#include <immintrin.h>
const int TIMES = 2;
const int THREAD_NUM = TIMES * TIMES;
struct sub_task
{
float **A;
float **B;
float **C;
int n;
int m;
int p;
int r_id; // 0, 1, 2,..., TIMES
int l_id; // 0, 1, 2,..., TIMES
};
void *thread(void *arg)
{
struct sub_task *task = (struct sub_task *)arg;
float **A = task->A;
float **B = task->B;
float **C = task->C;
int n = task->n;
int m = task->m;
int p = task->p;
int r_id = task->r_id;
int l_id = task->l_id;
int i_right = (r_id + 1) * n / TIMES, j_right = (l_id + 1) * p / TIMES;
for (int i = r_id * n / TIMES; i < i_right; i++)
for (int j = l_id * p / TIMES; j < j_right; j++)
{
C[i][j] = 0;
for (int k = 0; k < m; k++)
{
C[i][j] += A[i][k] * B[k][j];
}
}
return NULL;
}
void *thread_maxv_line_first(void *arg)
{
struct sub_task *task = (struct sub_task *)arg;
float **A = task->A;
float **B = task->B;
float **C = task->C;
int N = task->n;
int M = task->m;
int P = task->p;
int r_id = task->r_id;
// int l_id = task->l_id;
int i_right = (r_id + 1) * N / THREAD_NUM;
__m256 ymm0, ymm1, ymm2, ymm3, ymm4, ymm5, ymm6, ymm7,
ymm8, ymm9, ymm10, ymm11, ymm12, ymm13, ymm14, ymm15;
float scratchpad[8];
int col_reduced = M - M % 64;
int col_reduced_32 = M - M % 32;
for (int i = r_id * N / THREAD_NUM; i < i_right; i++)
{
for (int p = 0; p < P; p++)
{
float res = 0;
for (int j = 0; j < col_reduced; j += 64)
{
// ymm 8 - 15 装载 B[p] 列
ymm8 = __builtin_ia32_loadups256(&B[p][j]);
ymm9 = __builtin_ia32_loadups256(&B[p][j + 8]);
ymm10 = __builtin_ia32_loadups256(&B[p][j + 16]);
ymm11 = __builtin_ia32_loadups256(&B[p][j + 24]);
ymm12 = __builtin_ia32_loadups256(&B[p][j + 32]);
ymm13 = __builtin_ia32_loadups256(&B[p][j + 40]);
ymm14 = __builtin_ia32_loadups256(&B[p][j + 48]);
ymm15 = __builtin_ia32_loadups256(&B[p][j + 56]);
// ymm 0 - 7 装载 A[i] 行
ymm0 = __builtin_ia32_loadups256(&A[i][j]);
ymm1 = __builtin_ia32_loadups256(&A[i][j + 8]);
ymm2 = __builtin_ia32_loadups256(&A[i][j + 16]);
ymm3 = __builtin_ia32_loadups256(&A[i][j + 24]);
ymm4 = __builtin_ia32_loadups256(&A[i][j + 32]);
ymm5 = __builtin_ia32_loadups256(&A[i][j + 40]);
ymm6 = __builtin_ia32_loadups256(&A[i][j + 48]);
ymm7 = __builtin_ia32_loadups256(&A[i][j + 56]);
// A[i][] * B[][p]
ymm0 = __builtin_ia32_mulps256(ymm0, ymm8);
ymm1 = __builtin_ia32_mulps256(ymm1, ymm9);
ymm2 = __builtin_ia32_mulps256(ymm2, ymm10);
ymm3 = __builtin_ia32_mulps256(ymm3, ymm11);
ymm4 = __builtin_ia32_mulps256(ymm4, ymm12);
ymm5 = __builtin_ia32_mulps256(ymm5, ymm13);
ymm6 = __builtin_ia32_mulps256(ymm6, ymm14);
ymm7 = __builtin_ia32_mulps256(ymm7, ymm15);
// 对 ymm0-ymm7求和得结果
ymm0 = __builtin_ia32_addps256(ymm0, ymm1);
ymm2 = __builtin_ia32_addps256(ymm2, ymm3);
ymm4 = __builtin_ia32_addps256(ymm4, ymm5);
ymm6 = __builtin_ia32_addps256(ymm6, ymm7);
ymm0 = __builtin_ia32_addps256(ymm0, ymm2);
ymm4 = __builtin_ia32_addps256(ymm4, ymm6);
ymm0 = __builtin_ia32_addps256(ymm0, ymm4);
__builtin_ia32_storeups256(scratchpad, ymm0);
for (int k = 0; k < 8; k++)
res += scratchpad[k];
}
for (int j = col_reduced; j < col_reduced_32; j += 32)
{
ymm8 = __builtin_ia32_loadups256(&B[p][j]);
ymm9 = __builtin_ia32_loadups256(&B[p][j + 8]);
ymm10 = __builtin_ia32_loadups256(&B[p][j + 16]);
ymm11 = __builtin_ia32_loadups256(&B[p][j + 24]);
ymm0 = __builtin_ia32_loadups256(&A[i][j]);
ymm1 = __builtin_ia32_loadups256(&A[i][j + 8]);
ymm2 = __builtin_ia32_loadups256(&A[i][j + 16]);
ymm3 = __builtin_ia32_loadups256(&A[i][j + 24]);
ymm0 = __builtin_ia32_mulps256(ymm0, ymm8);
ymm1 = __builtin_ia32_mulps256(ymm1, ymm9);
ymm2 = __builtin_ia32_mulps256(ymm2, ymm10);
ymm3 = __builtin_ia32_mulps256(ymm3, ymm11);
ymm0 = __builtin_ia32_addps256(ymm0, ymm1);
ymm2 = __builtin_ia32_addps256(ymm2, ymm3);
ymm0 = __builtin_ia32_addps256(ymm0, ymm2);
__builtin_ia32_storeups256(scratchpad, ymm0);
for (int k = 0; k < 8; k++)
res += scratchpad[k];
}
for (int l = col_reduced_32; l < M; l++)
{
res += A[i][l] * B[p][l];
}
C[i][p] = res;
}
}
return NULL;
}
// 传入的第二个矩阵应该先转置
void matrix_multiply_maxv_line_first(float **A, float **B, float **C, int N, int M, int P)
{
pthread_t threads[THREAD_NUM];
struct sub_task tasks[THREAD_NUM];
for (int i = 0; i < THREAD_NUM; i++)
{
tasks[i].r_id = i;
// tasks[i][j].l_id = j;
tasks[i].A = A;
tasks[i].B = B;
tasks[i].C = C;
tasks[i].n = N;
tasks[i].m = M;
tasks[i].p = P;
pthread_create(&threads[i], NULL, thread_maxv_line_first, &tasks[i]);
}
for (int i = 0; i < THREAD_NUM; i++)
pthread_join(threads[i], NULL);
}
void *thread_line_first(void *arg)
{
struct sub_task *task = (struct sub_task *)arg;
float **A = task->A;
float **B = task->B;
float **C = task->C;
int n = task->n;
int m = task->m;
int p = task->p;
int r_id = task->r_id;
int l_id = task->l_id;
int i_right = (r_id + 1) * n / TIMES, j_right = (l_id + 1) * p / TIMES;
for (int i = r_id * n / TIMES; i < i_right; i++)
for (int j = l_id * p / TIMES; j < j_right; j++)
{
C[i][j] = 0;
for (int k = 0; k < m; k++)
{
C[i][j] += A[i][k] * B[j][k];
}
}
return NULL;
}
void matrix_multiply(float **A, float **B, float **C, int n, int m, int p)
{
pthread_t threads[TIMES][TIMES];
struct sub_task tasks[TIMES][TIMES];
for (int i = 0; i < TIMES; i++)
{
for (int j = 0; j < TIMES; ++j)
{
tasks[i][j].r_id = i;
tasks[i][j].l_id = j;
tasks[i][j].A = A;
tasks[i][j].B = B;
tasks[i][j].C = C;
tasks[i][j].n = n;
tasks[i][j].m = m;
tasks[i][j].p = p;
pthread_create(&threads[i][j], NULL, thread, &tasks[i][j]);
}
}
for (int i = 0; i < TIMES; i++)
for (int j = 0; j < TIMES; ++j)
{
pthread_join(threads[i][j], NULL);
}
}
void matrix_multiply_line_first(float **A, float **B, float **C, int n, int m, int p)
{
pthread_t threads[TIMES][TIMES];
struct sub_task tasks[TIMES][TIMES];
for (int i = 0; i < TIMES; i++)
{
for (int j = 0; j < TIMES; ++j)
{
tasks[i][j].r_id = i;
tasks[i][j].l_id = j;
tasks[i][j].A = A;
tasks[i][j].B = B;
tasks[i][j].C = C;
tasks[i][j].n = n;
tasks[i][j].m = m;
tasks[i][j].p = p;
pthread_create(&threads[i][j], NULL, thread_line_first, &tasks[i][j]);
}
}
for (int i = 0; i < TIMES; i++)
for (int j = 0; j < TIMES; ++j)
{
pthread_join(threads[i][j], NULL);
}
}
void matrix_print(float **M, int n, int m)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
printf("%f ", M[i][j]);
}
putchar('\n');
}
}
float **matrix_malloc(int n, int m)
{
float **M;
M = (float **)malloc(sizeof(float *) * n);
for (int i = 0; i < n; ++i)
{
M[i] = (float *)malloc(sizeof(float) * m);
}
return M;
}
void matrix_init(float **M, int n, int m)
{
for (int i = 0; i < n; ++i)
{
for (int j = 0; j < m; ++j)
{
M[i][j] = rand() % 10;
}
}
}
float **matrix_transpose(float **M, int n, int m)
{
float **T = matrix_malloc(m, n);
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
T[j][i] = M[i][j];
return T;
}
int main(int argc, char *argv[])
{
int n, m, p;
if (argc == 2)
{
n = m = p = atoi(argv[1]);
}
else if (argc == 4)
{
n = atoi(argv[1]);
m = atoi(argv[2]);
p = atoi(argv[3]);
}
else
{
printf("Help:\n");
printf("./multithread n\n");
printf("./multithread n m p\n");
return 0;
}
float **A = matrix_malloc(n, m);
if (!A)
{
perror("matrix_malloc()");
}
float **B = matrix_malloc(m, p);
if (!B)
{
perror("matrix_malloc()");
}
float **C = matrix_malloc(n, p);
if (!C)
{
perror("matrix_malloc()");
}
matrix_init(A, n, m);
matrix_init(B, m, p);
// matrix_print(A, n, m);
// matrix_print(B, m, p);
// matrix_print(T, p, m);
struct timespec t1, t2, t3, t4, t5, t6;
clock_gettime(CLOCK_MONOTONIC, &t1);
matrix_multiply(A, B, C, n, m, p);
clock_gettime(CLOCK_MONOTONIC, &t2);
printf("4线程算法用时:%lf\n", t2.tv_sec - t1.tv_sec + (t2.tv_nsec - t1.tv_nsec) / 1000000000.0);
matrix_print(C, n, p);
clock_gettime(CLOCK_MONOTONIC, &t3);
float **T = matrix_transpose(B, m, p);
if (!T)
{
perror("matrix_transpose()");
}
matrix_multiply_line_first(A, T, C, n, m, p);
clock_gettime(CLOCK_MONOTONIC, &t4);
printf("4线程+行优先用时:%lf\n", t4.tv_sec - t3.tv_sec + (t4.tv_nsec - t3.tv_nsec) / 1000000000.0);
matrix_print(C, n, p);
clock_gettime(CLOCK_MONOTONIC, &t5);
T = matrix_transpose(B, m, p);
if (!T)
{
perror("matrix_transpose()");
}
matrix_multiply_maxv_line_first(A, T, C, n, m, p);
clock_gettime(CLOCK_MONOTONIC, &t6);
printf("行优先+向量指令+多线程用时:%lf\n", t6.tv_sec - t5.tv_sec + (t6.tv_nsec - t5.tv_nsec) / 1000000000.0);
matrix_print(C, n, p);
}
CUDA程序(cuda.cu)
#include <stdio.h>
#include <stdio.h>
#include <time.h>
#define N 5
#define BLOCK 64
float a[N * N], b[N * N], c[N * N];
__device__ float sum(float *cache, int id)
{
int i = blockDim.x / 2;
while (i != 0)
{
if (id < i)
{
cache[id] += cache[id + i];
}
__syncthreads();
i /= 2;
}
return cache[0];
}
__global__ void matrix_dot(float *a, float *b, float *c)
{
int i = blockIdx.x;
int j = blockIdx.y;
__shared__ float cache[BLOCK];
int t = threadIdx.x;
if (t < N)
cache[t] = a[i * N + t] * b[t * N + j];
else
cache[t] = 0;
__syncthreads();
sum(cache, t);
__syncthreads();
c[i * N + j] = cache[0];
}
__host__ void dot(float *a, float *b, float *c)
{
float *a_cuda, *b_cuda, *c_cuda;
cudaMalloc((void **)&a_cuda, N * N * sizeof(float));
cudaMalloc((void **)&b_cuda, N * N * sizeof(float));
cudaMalloc((void **)&c_cuda, N * N * sizeof(float));
cudaMemcpy(a_cuda, a, N * N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(b_cuda, b, N * N * sizeof(float), cudaMemcpyHostToDevice);
dim3 matrix(N, N);
matrix_dot<<<matrix, BLOCK>>>(a_cuda, b_cuda, c_cuda);
cudaMemcpy(c, c_cuda, N * N * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(a_cuda);
cudaFree(b_cuda);
cudaFree(c_cuda);
}
int main()
{
clock_t startTime, endTime;
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N; j++)
{
a[i * N + j] = rand() % 10;
}
}
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N; j++)
{
b[i * N + j] = rand() % 10;
}
}
startTime = clock();
dot(a, b, c);
endTime = clock();
printf("GPU加速矩阵乘法用时: %lf\n", 1.0 * (endTime - startTime) / CLOCKS_PER_SEC);
// printf("A:\n");
// for (int i = 0; i < N; i++) {
// for (int j = 0; j < N; j++) {
// printf("%f ", a[i*N + j]);
// }
// printf("\n");
// }
// printf("B:\n");
// for (int i = 0; i < N; i++) {
// for (int j = 0; j < N; j++) {
// printf("%f ", b[i*N + j]);
// }
// printf("\n");
// }
printf("C:\n");
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
printf("%f ", c[i*N + j]);
}
printf("\n");
}
return 0;
}
关键实验结果
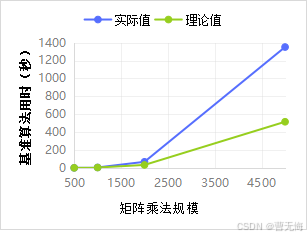
- 基准算法用时的理论用时和实际用时
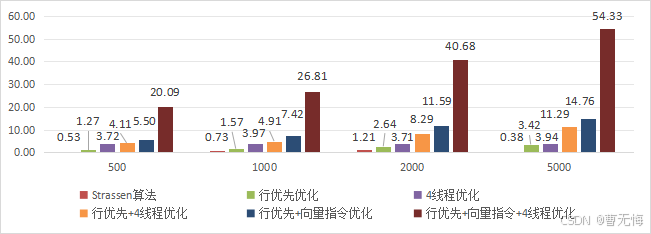
- 优化矩阵乘法计算的各个策略组合的加速比(基准算法为1)
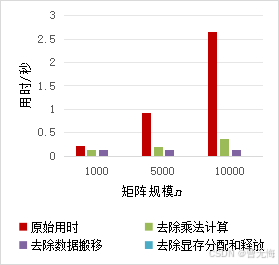
- 使用GPU加速矩阵乘法计算的用时对比和消融分析




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











