





 本文介绍了如何使用Sqoop工具将MySQL数据库表'blog'的数据导入HDFS,并创建了一个自动化脚本,用于按日期导入前一天的数据。重点讲解了命令参数和脚本结构,包括连接信息、表选择、查询条件、文件组织和参数优化。
本文介绍了如何使用Sqoop工具将MySQL数据库表'blog'的数据导入HDFS,并创建了一个自动化脚本,用于按日期导入前一天的数据。重点讲解了命令参数和脚本结构,包括连接信息、表选择、查询条件、文件组织和参数优化。
Sqoop
sqoop是把关系型数据库数据和HDFS互导的工具,以HDFS为中心,导入到HDFS用import,从HDFS导出用export
实例分析
Sqoop数据导入到HDFS
- 查看所有库的命令
sqoop list-databases --connect jdbc:mysql://dt100:3306 -username root -password 123123
- 查看某个库的表的命令
sqoop list-tables --connect jdbc:mysql://dt100:3306/bysj -username root -password 123123
- 导入表到HDFS的脚本及分析
#!/bin/bash
/opt/module/sqoop/bin/sqoop import \
--connect jdbc:mysql://dt100:3306/bysj \
--username root \
--password 123123 \
--table blog \
--columns id,title \
--where "id>=2 and id<=8" \
--target-dir=/test \
--delete-target-dir \
--num-mappers 2\
--split-by id \
--fields-terminated-by '\t'
sql查询形式 (注意必须要加上$CONDITIONS)
#!/bin/bash
/opt/module/sqoop/bin/sqoop import \
--connect jdbc:mysql://dt100:3306/bysj \
--username root \
--password 123123 \
--query "select id,title from blog where id>=2 and id<=10 and \$CONDITIONS" \
--target-dir=/test \
--delete-target-dir \
--num-mappers 2\
--split-by id \
--fields-terminated-by '\t'
- 分析
#连接到目标表并选择条件
–connect jdbc:mysql://dt100:3306/bysj
–username root
–password 123123
–table blog
–columns id,title
#出现空格需要加引号,如果有变量则一定是双引号
–where “id>=2 and id<=8”
#目标文件夹
–target-dir=/test
#如果目标文件夹存在则删除
–delete-target-dir
#优化语句(设置mapper个数)和切分规则,因为sqoop实质上就是一个只有map过程的MR
–num-mappers 2
–split-by id
#设置字段分隔符
–fields-terminated-by ‘\t’
- 结果
blog表
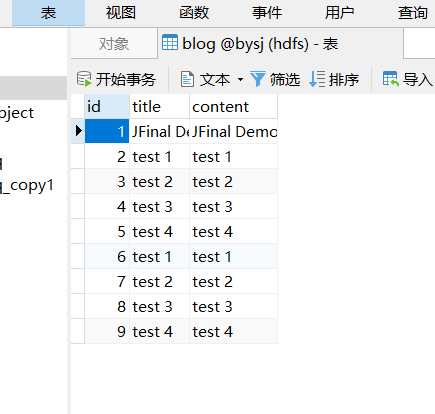
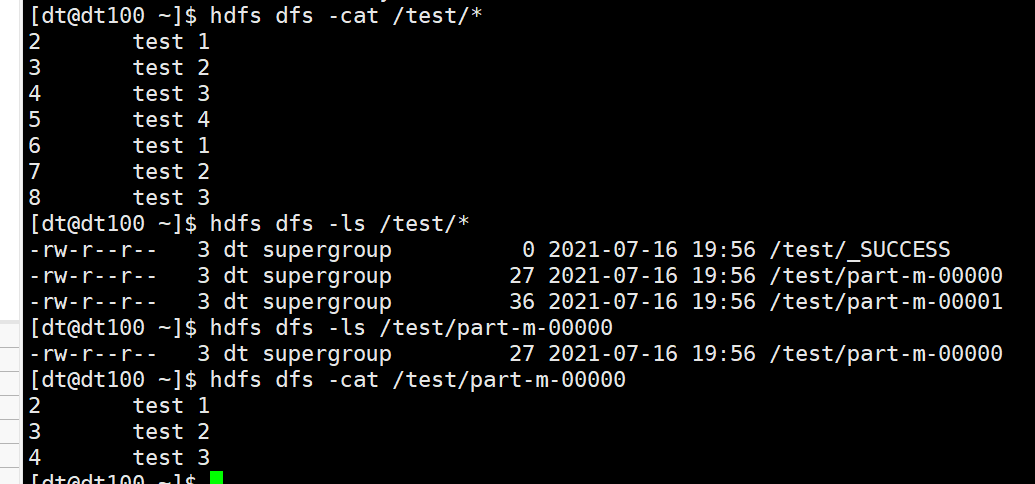
hdfs文件 导入成功
通常情况下,我们每天导入数据,就需要写一个脚本,以下是sqoop导入的一个基础脚本
#!/bin/bash
if [-n "$2"]; then
do_date=$2
else
do_date=$(date -d '-1 day'+%F)
fi
import_data(){
/opt/module/sqoop/bin/sqoop import \
--connect jdbc:mysql://dt100:3306/bysj \
--username root \
--password 123123 \
--query "$2 and \$CONDITIONS" \
--target-dir=/test/$1/$do_date \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-not-string '\\N'
}
import_blog(){
import_data blog "select id,title from blog where 1=1"
}
case $1 in "yes")
import_blog
;;
"no")
;;
esac
解析部分
shell if中的-n 代表不为空
\\N 第一个\代表转义,\N代表NULL

















 2416
2416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









