




最近在清洗调查数据时候,发现了几个之前未曾应用的数据清理小技巧,在此一一和小伙伴们分享一下经验,也算是做一下记录,留备后期回顾学习。
一、矩阵处理
iris[c(1,2),2]->t
print(t)
[1] 3.5 3.0
iris[c(1,2),2,drop=F]->t##加上drop参数,保持提取的数据仍然是一个矩阵##
print(t)
Sepal.Width
1 3.5
2 3.0二、正则表达式
常用正则表达式如下:
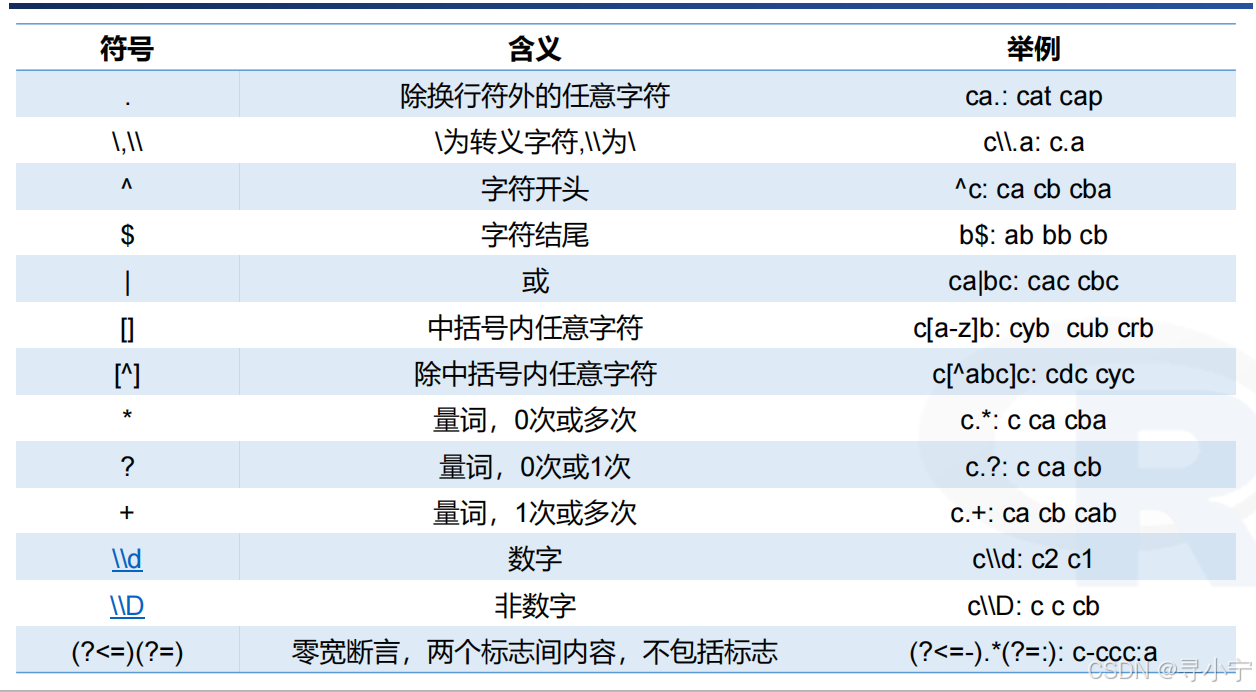
此处主讲【零宽断言】
正则表达式【零宽断言】——提前字符中两个标志间内容,不包括标志(?<=)(?=)
str_extract("姓名+小爱同学",".*(?=\\+)")##【.*】在前提取标注前文字
print("姓名")
str_extract("姓名:小爱同学","(?<=\\:).*")##【<加.*】在后提取标注后文字
print("小爱同学")
三、泛函数的应用
泛函:函数作为参数,作用于每一个元素;purrr式泛函:~.x,function(x),~(.x)*(.y),重要的是.x代表了数据框中待处理的内容。
1、map族函数

map函数应用示例:
map(mtcars,mean)##输出列表型##
$mpg
[1] 20.09062
$cyl
[1] 6.1875
$disp
[1] 230.7219
map_dbl(mtcars,mean)##输出字符型##
mpg cyl disp
20.090625 6.187500 230.721875
map_dfc(mtcars,mean)##输出矩阵型##
# A tibble: 1 × 11
mpg cyl disp hp drat wt qsec vs am gear carb
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 20.1 6.19 231. 147. 3.60 3.22 17.8 0.438 0.406 3.69 2.812、map族函数与lapply函数应用对比
##map函数同lapply函数的区别应用##
cat("map函数用来对数据框中的列变量进行处理----同lapply函数")
map(iris[,1:4],mean)##等同于lapply函数##
$Sepal.Length
[1] 5.843333
$Sepal.Width
[1] 3.057333
lapply(iris[,1:4],mean)
$Sepal.Length
[1] 5.843333
$Sepal.Width
[1] 3.057333
#不同之处————map函数可以对数据库传递自定义函数,参数格式不同,结果一致##
map(iris[,1:4],~(.x)*2)##括号内.x代表对map函数进行传递自定义函数
$Sepal.Length
[1] 10.2 9.8 9.4 9.2 10.0 10.8 9.2 10.0 8.8 9.8 10.8 9.6 9.6 8.6 11.6 11.4
[145] 13.4 13.4 12.6 13.0 12.4 11.8
$Sepal.Length
lapply(iris[,1:4],function(x)(x*2))##等同于在使用lapply函数时重新定义了一个自定义函数
[1] 10.2 9.8 9.4 9.2 10.0 10.8 9.2 10.0 8.8 9.8 10.8 9.6 9.6 8.6 11.6 11.4
[145] 13.4 13.4 12.6 13.0 12.4 11.8
map2(iris$Sepal.Length,iris$Sepal.Width,~(.x)/(.y))##map2函数对数据框中的多个列处理,传递自定义函数
[[1]]
[1] 1.457143
[[2]]
[1] 1.633333
pmap(list(iris$Sepal.Length,iris$Sepal.Width),~(.x)*2)##pmap函数能够传递自定义函数,进而对整个数据集中的行进行操作
[[1]]
[1] 10.2
[[2]]
[1] 9.83、map族函数与正则表达式联合使用
(ps:pmap_lgl函数特别适用于筛选多列数据)
###map&str_$gep等正则表达结合应用——二者等同###
filter(mpp,!if_any(grep("^A\\d$",names(mpp)),~is.na(.x)))##提取出以A开头^,数字d结束$的数据列并清除数据列中的缺失值##
filter(mpp,if_any(which(str_detect(names(mpp),"^A\\d$")==T),~!is.na(.x)))##.x用来表示数据集中的所有变量##
##pmap_lgl函数用来筛选多个列数据
iris%>%filter(pmap_lgl(.[1:3],~any(c(...)>7.0)==1)) #any等同于|,筛选出数据集1-3列中任意大于7.0的数据
iris%>%filter(pmap_lgl(.[1:3],~sum(c(...)>7.0)==3)) #sum等同于&,筛选出数据集中1-3列所有大于7.0的数据4、map函数读取多个excel或sheet
##map vs for循环##
tt<-list()
for(i in 1:3){
tt[[i]]<-read_excel("testclean.xlsx",sheet = i)
}
names(tt)<-c("s1","s2","s3")
##同上##
file.path("testclean.xlsx")->fp##读取文件所在位置##
excel_sheets(fp)->es##读取文件中多个sheet##
map(es,~read_excel("testclean.xlsx",sheet = .x))->tt
##利用map泛函数批量读取sheet文件,map泛函数与lapply函数使用类似————主要是对数据框传递并应用相对的函数进而对数据进行操作##
5、reduce函数
对数据库进行批量连接(按照列进行合并,左连接)====等同于left_join函数
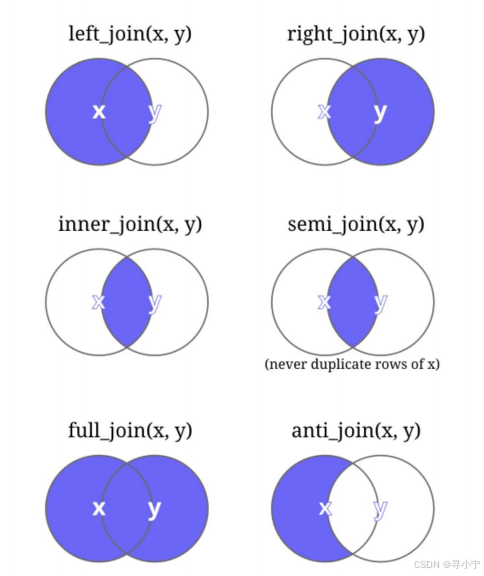
批量连接操作实例:
##test##
seq(1:10)->id
paste0("x",1:10)->nn
paste0("T",1:10)->tt
paste0("y",1:10)->yy
data.frame(id,nn)->a1
data.frame(id,tt)->a2
data.frame(id,yy)->a3
##left_join连接##
left_join(a1,a2,by="id")%>%left_join(a3,by="id")##需要使用多个left_join函数
id nn tt yy
1 1 x1 T1 y1
2 2 x2 T2 y2
3 3 x3 T3 y3
4 4 x4 T4 y4
5 5 x5 T5 y5
6 6 x6 T6 y6
7 7 x7 T7 y7
8 8 x8 T8 y8
9 9 x9 T9 y9
10 10 x10 T10 y10
##reduce连接##
purrr::reduce(list(a1,a2,a3),left_join)####可将某个函数传递至多个数据框进行操作##
Joining with `by = join_by(id)`
Joining with `by = join_by(id)`
id nn tt yy
1 1 x1 T1 y1
2 2 x2 T2 y2
3 3 x3 T3 y3
4 4 x4 T4 y4
5 5 x5 T5 y5
6 6 x6 T6 y6
7 7 x7 T7 y7
8 8 x8 T8 y8
9 9 x9 T9 y9
10 10 x10 T10 y10
















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









