







机器学习之knn
knn
K最近邻(kNN,k-Nearest Neighbor): k近邻法(k-nearest neighbor, k-NN)是1967年提出的一种基本分类与回归方法。K最近邻分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有
这个类别上样本的特性。
工作原理:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即每一个数据与所属分类的一一对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。

距离度量
1.欧氏距离:
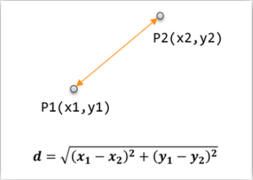
2.曼哈顿距离:
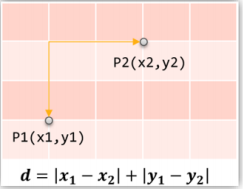
3.马氏距离:
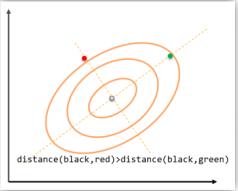
4.家教余弦:
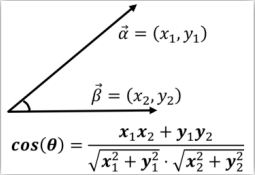
k-近邻算法步骤:
1.计算已知类别数据集中的点与当前点之间的距离;
2.按照距离递增次序排序;
3.选取与当前点距离最小的k个点;
4.确定前k个点所在类别的出现频率;
5.返回前k个点所出现频率最高的类别作为当前点的预测分类。
knn代码实现
knn
import numpy as np
import operator
#数据集
def createDataSet():
group = np.array([[1,100],[5,80],[6,80],[108,5],[115,8],[75,6]])
#六组⼆维特征
labels = ['爱情','爱情','爱情','动作','动作','动作']
#六组特征的标签
return group, labels
dataset, labels = createDataSet()
test_data = [101,20] #测试集
k=3
distances = np.sum((test_data - dataset)**2, axis=1)**0.5
#返回distances中元素从⼩到⼤排序后的索引值
sortedDistIndices = distances.argsort()
#定⼀个记录类别次数的字典
classCount = {}
for i in range(k): #取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]] #dict.get(key,default=None),字典的get()⽅法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#key=operator.itemgetter(1)根据字典的值进行排序
#key=operator.itemgetter(0)根据字典的键进行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) #返回次数最多的类别,即所要分类的类别
print(sortedClassCount[0][0])
k-近邻算法实战:数据归一化
当有几种特征是同等重要的,作为几个等权重的特征之一,不同的特征值之间的数据大小存在这不同,为了能够很好的进行聚类分析,这几个特征需要进行归一化的处理,将任意取值范围的特征值转化为0到1区间内的值:
newValue = (oldValue - min) / (max - min)
学习曲线
KNN中的k是一个超参数,需要人为输入。从KNN原理中可知,k值对算法有极大的影响。
如果选择的k值较小,就相当于较小的邻域中的训练实例进行预测,这时候只有与输入实例较近的(相似的)训练实例才会对预测结果起作用,但缺点是预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰好是噪声,预测就会出错。相反地,如果选择的k值较大,就相当于较大的邻域中的训练实例进行预测。这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。
如何选择最优的k:通过参数学习曲线找到最优的k。
学习曲线
from sklearn.linear_model import LinearRegression, Ridge,Lasso
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 1、加载数据集
ld = load_boston()
x_train,x_test,y_train,y_test = train_test_split(ld.data,ld.target,test_size=0.25)
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.fit_transform(x_test)
# ⽬标值进⾏处理
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1))
y_test = std_y.transform(y_test.reshape(-1,1))
krange = range(1,20)
score=[]
for i in krange:
knn = KNeighborsRegressor(n_neighbors=i)
knn.fit(x_train, y_train)
score.append(knn.score(x_test,y_test))
plt.plot(krange,score)
plt.show()
交叉验证
模型每次使用不同的训练集和测试集,有不同的测试结果。
机器学习追求的是模型在未知数据集上的效果,通过交叉验证进一步提高模型的泛化能力。
sklearn.model_selection 的 cross_val_score 方法来计算模型的得分 。
交叉验证
from sklearn.model_selection import cross_val_score as CVS
knn = KNeighborsRegressor(n_neighbors=2)
cvresult = CVS(knn,x_train, y_train,cv=5)
import matplotlib.pyplot as plt
%matplotlib inline
score=[]
var_ = []
krange = range(1,21)
for i in krange:
knn = KNeighborsRegressor(n_neighbors=i)
cvresult = CVS(knn,x_train, y_train,cv=5)
score.append(cvresult.mean())
var_.append(cvresult.var())
plt.plot(krange,score,color='b')
sklearn中的knn
sklearn的网址
sklearn中的knn
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# 导入鸢尾花数据并查看数据特征
iris = datasets.load_iris()
print('数据量',iris.data.shape)
# 拆分属性数据
iris_X = iris.data
# 拆分类别数据
iris_y = iris.target
iris_train_X , iris_test_X, iris_train_y ,iris_test_y = train_test_split(iris_X, iris_y,test_size=0.2,random_state=0)
knn = KNeighborsClassifier(n_neighbors=6)
knn.fit(iris_train_X, iris_train_y)
predict_result=knn.predict(iris_test_X)
print('预测结果',predict_result)
# 计算预测的准确率
print('预测准确率',knn.score(iris_test_X, iris_test_y))
KNN总结:
一种非参数、惰性学习方法,导致预测时速度慢。
当训练样本集较大时,会导致其计算开销高。
样本不平衡的时候,对稀有类别的预测准确率低。
KNN模型的可解释性不强。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









