







 本文介绍了Python中正则表达式的基本概念和使用方法,包括编译、常用操作符、re库的函数如search、match、findall、split、finditer和sub,以及贪婪匹配和最小匹配的原理。通过实例解析了如何匹配IP地址,并提供了正则表达式测试网站的推荐。
本文介绍了Python中正则表达式的基本概念和使用方法,包括编译、常用操作符、re库的函数如search、match、findall、split、finditer和sub,以及贪婪匹配和最小匹配的原理。通过实例解析了如何匹配IP地址,并提供了正则表达式测试网站的推荐。
-
概念
正则表达式(regular expression,regex,RE),是用来简洁表达一组字符串的表达式,例如,将一一列举的字符串用RE表示就很简洁

下面举例子
无穷字符串组


是一种通用的字符串表达框架
正则表达式的使用:
编译:符合正则表达式语法的字符串转换成正则表达式特征 -
正则表达式的语法
例子

正则表达式是由字符和操作符组成的
常用操作符
这里推荐一个网站正则表达式测试网站,下面举几个例子

经典正则表达式

匹配IP地址的正则表达式,IP地址分4段,每段0-255


-
re库的基本使用
re库是python的标准库,主要用于字符串匹配,调用方法:import re
表示类型
raw string 类型
raw string用于表达正则表达式,表示为:r’text
e.g r’[1-9]\d{5}’
原生字符串(raw string)不包含转义符()
string类型
更繁琐,是因为如果出现\d这种的话前面需要再添加\,避免转义符冲突
re库主要功能函数

例子
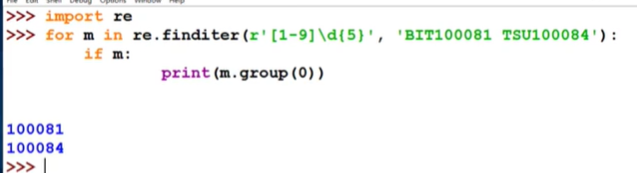
search:
#re.search(pattern,string,flags=0)
#pattern:正则表达式字符串或者原生字符串表示;string:待匹配字符串;flags:正则表达式使用时的控制标记
import re
exam = '\d+'
str1= "abc1233AAPYTNACM"
ret = re.search(exam,str1)
print(ret)
注释:
match:
#re.search(pattern,string,flags=0)
#pattern:正则表达式字符串或者原生字符串表示;string:待匹配字符串;flags:正则表达式使用时的控制标记
import re
exam = '\d+'
str1= "253abc1233AAPYTNACM"
ret = re.match(exam,str1)
print(ret)
findall:
#re.search(pattern,string,flags=0)
#pattern:正则表达式字符串或者原生字符串表示;string:待匹配字符串;flags:正则表达式使用时的控制标记
import re
exam = '\d+'
str1= "abc1233AAPYTNACM456"
ret = re.findall(exam,str1)
print(ret)
split:
#re.search(pattern,string,maxsplit=0,flags=0)
#pattern:正则表达式字符串或者原生字符串表示;string:待匹配字符串;maxsplit:最大分割术,剩余部分做最后一个元素输出;flags:正则表达式使用时的控制标记
import re
exam = '\d+'
str1= "abc1233AAPYTNACM456"
ret = re.split(exam,str1)
print(ret)
这个split的结果得分析一下,最后结果是不符合’\d+'的,如下图

加上maxsplit=1

只分割了第一个不符合的
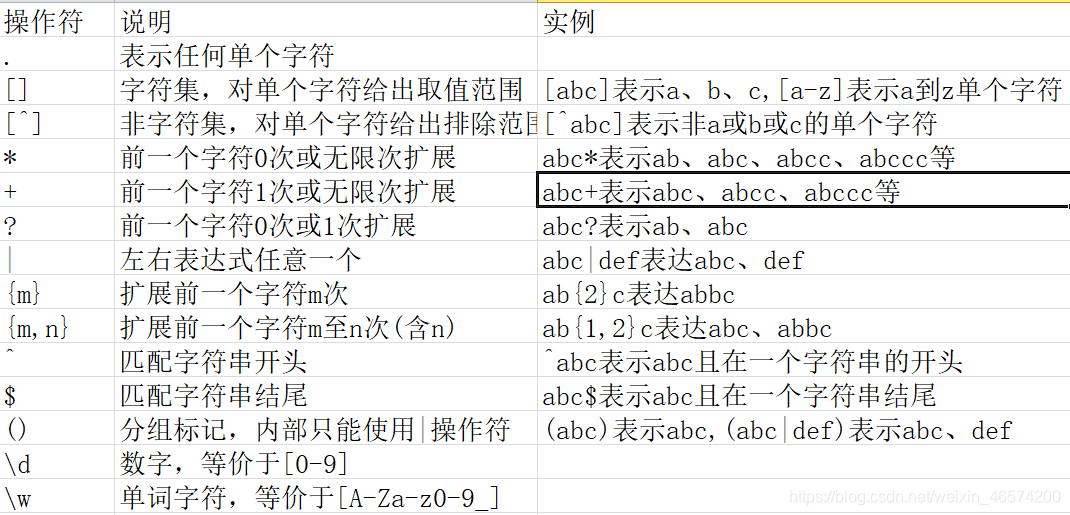
finditer:
我懒,不想打了
sub:

import re
exam = '\d+'
str1= "abc1233AAPYTNACM"
ret = re.sub(exam,'dwj',str1)
print(ret)
re库的另一种等价用法

这里再介绍一下compile
regex=re.compile(pattern,flags=0),将正则表达式字符串形式编译成表达式对象,同时也有上面六种函数,不过是regex.function()
-
re库的match对象

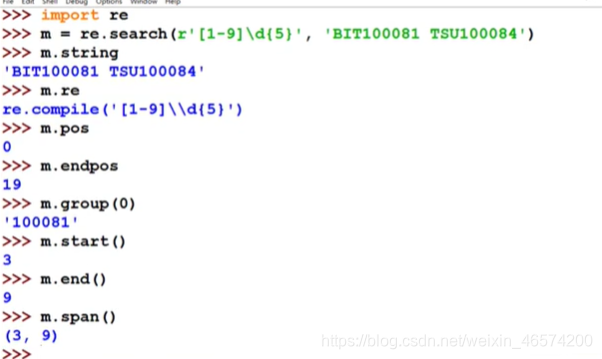
更多属性应用时自行查找 -
re库贪婪匹配和最小匹配
贪婪匹配:re库默认贪婪匹配,输出匹配最长的字符串
import re
exam = r'PY.*N' #r.text,原生字符串类型,.指任意单个字符,*前一个字符0次或无限次扩展
str1= 'PYANBNCNDN'
ret = re.search(exam,str1)
print(ret)
结果是PYANBNCNDN,最长
最小匹配:最短字符串

例子
import re
exam = r'PY.*?N'
str1= 'PYANBNCNDN'
ret = re.search(exam,str1)
print(ret)

这是正则基础知识,后面会继续更出一个大例子。
Enjoy!!!

















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









