







 博客介绍了如何使用Python爬虫解决猿人学比赛中的一个挑战,涉及抓取接口数据,解密CSS中的动态字体,通过转换WOFF文件到XML,解析出对应字符并找出最高胜点的召唤师。
博客介绍了如何使用Python爬虫解决猿人学比赛中的一个挑战,涉及抓取接口数据,解密CSS中的动态字体,通过转换WOFF文件到XML,解析出对应字符并找出最高胜点的召唤师。
题目地址:http://match.yuanrenxue.com/match/7
这里可以直接抓取接口的数据,请求的时候没有存在反爬

可以看到返回的值都已以空格分隔的字符串,还有一个base64编码的woff文件
我们将这个woff文件保存下来,并将其转换为xml文件
from fontTools.ttLib import TTFont
url = 'http://match.yuanrenxue.com/api/match/7?page=1'
response = requests.get(url).json()
woffb64 = response['woff']
with open('07.woff', 'wb') as f:
f.write(base64.b64decode(woffb64.encode()))
TTFont('07.woff').saveXML('07.xml')```
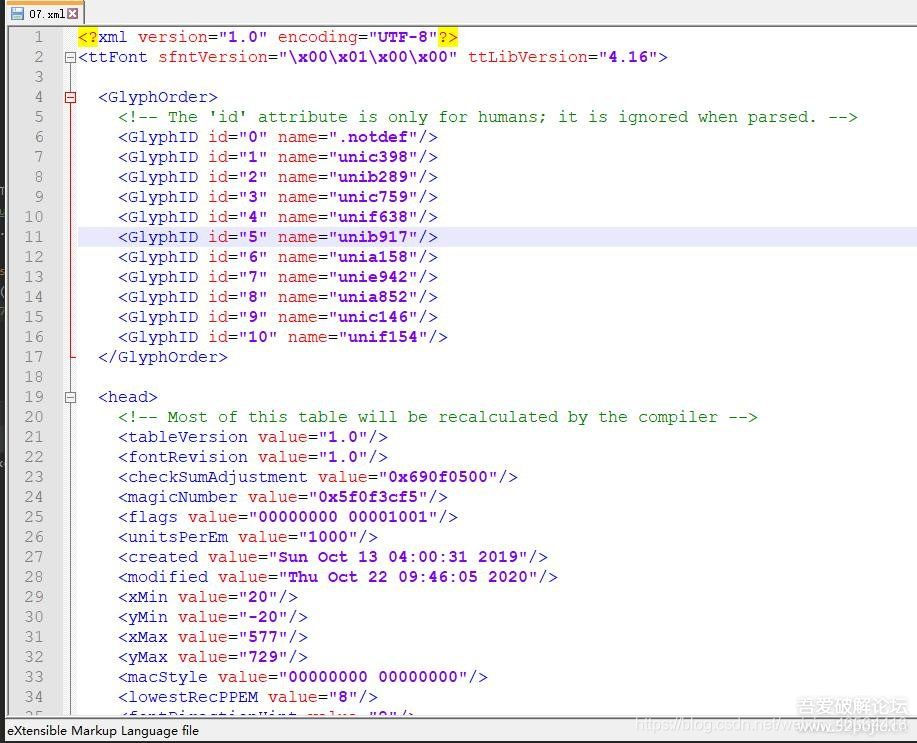
此时可以查看到字体文件的内容,其中最主要的是两个部分【cmap】和【glyf】
【cmap】表示的是我们响应的内容(源码内容)与name的映射关系
【glyf】表示name对应字体的轮廓信息
(备注:信息参考来源https://blog.youkuaiyun.com/dream_dt/article/details/82725398)
因为每个数字的轮廓是固定的,那么可以通过轮廓信息的前几个点来确定是哪一个数字
所以对于字体文 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









