




数据如下:
{“dept”:“技术部”,“name”:“yyf”,“salary”:“23000”,“state”:“1”}
{“dept”:“技术部”,“name”:“cyf”,“salary”:“25000”,“state”:“1”}
{“dept”:“后勤部”,“name”:“hc”,“salary”:“12000”,“state”:“1”}
{“dept”:“技术部”,“name”:“wlk”,“salary”:“23000”,“state”:“0”}
{“dept”:“后勤部”,“name”:“gwd”,“salary”:“13000”,“state”:“1”}
{“dept”:“市场部”,“name”:“ysr”,“salary”:“18000”,“state”:“1”}
{“dept”:“市场部”,“name”:“yjh”,“salary”:“19000”,“state”:“1”}
{“dept”:“市场部”,“name”:“lhr”,“salary”:“19000”,“state”:“0”}
[“dept”:“技术部”,“name”:“zsc”,“salary”:“22000”,“state”:“1”]
{“dept”:“管理部”,“name”:“chl”,“salary”:“23000”,“state”:“1”}
{“dept”:“管理部”,“name”:“zs”,“salary”:“21000”,“state”:“1”}
{“dept”:“技术部”,“name”:“lqf”,“salary”:“23500”,“state”:“0”}
{“dept”:“后勤部”,“name”:“lh”,“salary”:“12000”,“state”:“1”}
{“dept”:“市场部”,“name”:“lyl”,“salary”:“18500”,“state”:“1”}
{“dept”:“后勤部”,“name”:“zy”,“salary”:“12000”,“state”:“1”}
{“dept”:“技术部”,“name”:“zf”,“salary”:“23000”,“state”:“0”}
{“dept”:“后勤部”,“name”:“gy”,“salary”:“13000”,“state”:“1”}
{“dept”:“市场部”,“name”:“cc”,“salary”:“18000”,“state”:“1”}
{“dept”:“市场部”,“name”:“lb”,“salary”:“19000”,“state”:“1”}
{“dept”:“市场部”,“name”:“zgl”,“salary”:“19000”,“state”:“0”}
[“dept”:“技术部”,“name”:“smy”,“salary”:“22000”,“state”:“1”]
{“dept”:“管理部”,“name”:“zy”,“salary”:“23000”,“state”:“1”}
{“dept”:“管理部”,“name”:“gyp”,“salary”:“21000”,“state”:“1”}
{“dept”:“技术部”,“name”:“wtg”,“salary”:“23500”,“state”:“0”}
Kafka生产者进行发送数据
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.spark.{SparkConf, SparkContext}
import java.lang.Thread.sleep
import java.util.Properties
/**
* Kafka生产者
* 发送JSON数据
*/
object Kafka_SendData {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("test1").setMaster("local"))
var props = new Properties();
props.put("bootstrap.servers", "hdp1:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//获取JSON数据
val lineRDD = sc.textFile("src/main/resources/dept.json")
var producer = new KafkaProducer[String, String](props);
//进行Kafka发送数据
lineRDD.collect().foreach(i => {
producer.send(new ProducerRecord[String, String]("test", i));
//每2秒发送一条
sleep(2000)
})
producer.close();
sc.stop()
}
}
SparkStreaming进行接受数据,并利用Alibaba JSON进行解析
import com.alibaba.fastjson.JSON
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import java.util.Properties
object SparkStreaming_JSONAnalysis {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "hdp1:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("test")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
//偏移量
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// some time later, after outputs have completed
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
//获取数据
val dataDS = stream.map(record => (record.value))
//处理部分不符合JSON格式的数据,以及state状态为离职(值为0)的数据(5分)
val deptDS = dataDS.filter(i => {
try {
JSON.parseObject(i, classOf[Dept])
true
} catch {
case ex: Exception => false
}
}).map(i => {
JSON.parseObject(i, classOf[Dept])
}).filter(i => !i.state.equals("0"))
//对每个部门进行平均薪资汇总,实时统计每个部分的平均薪资(5分)
val deptAvg = deptDS.map(i => {
(i.dept, i.salary.toInt)
}).groupByKey().map(i => {
val name = i._1
var sum = 0
for (elem <- i._2) {
sum += elem
}
(name, sum * 1.0 / i._2.size)
})
// deptAvg.print()
//将平均分持久存储,每次接受的新数据都要和历史数据一起求取平均值(5分)
ssc.checkpoint("C:\\Data\\sparkcheckpoint")
val resDS = deptDS.map(i => {
((i.dept, i.salary.toInt), 1)
}).updateStateByKey((s: Seq[Int], o: Option[Int]) => Option(s.sum + o.getOrElse(0))).map(i => {
(i._1._1, (i._1._2, i._2))
}).groupByKey().map(i => {
val name = i._1
var sum = 0
var cnt = 0
for (elem <- i._2) {
sum += elem._1 * elem._2
cnt += elem._2
}
(name, sum * 1.0 / cnt)
})
//将结果数据实时写入到MySQL数据库中(5分)
resDS.foreachRDD(rdd=>{
val spark = SparkSession.builder().config(conf).getOrCreate()
val frame = spark.createDataFrame(rdd).toDF("deptName", "avgSalary")
var prop = new Properties()
prop.put("user","root")
prop.put("password","root")
frame.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/senior5?characterEncoding=utf8","dept",prop)
})
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
}
//{"dept":"后勤部","name":"gy","salary":"13000","state":"1"}
case class Dept(dept: String, name: String, salary: String, state: String)
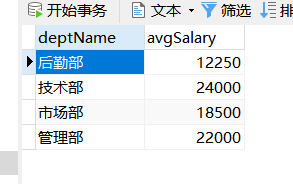
效果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









