







目录
你可以声明一个数组变量,如 numbers[100] 来代替直接声明 100 个独立变量 number0,number1,....,number99。
数组对于每一门编程语言来说都是重要的数据结构之一
1、数组是相同类型数据的有序集合;
2、其中,每一个数据称作一个数组元素,每个数组元素可以通过一个下标来访问它们。
声明数组变量
首先必须声明数组变量,才能在程序中使用数组。下面是声明数组变量的语法:
dataType[] arrayRefVar; // 首选的方法
或
dataType arrayRefVar[]; // 效果相同,但不是首选方法创建数组
Java语言使用new操作符来创建数组,语法如下:
arrayRefVar = new dataType[arraySize];数据类型可以是8种基本的数据类型,也可以是引用数据类型。
上面的语法语句做了两件事:
-
1、使用 dataType[arraySize] 创建了一个数组。
-
2、把新创建的数组的引用赋值给变量 arrayRefVar。
数组的初始化
1、动态初始化
创建了一个dataType类型,大小为arraySize的数组。数组元素并未被赋值,此时有默认值
dataType[] arrayRefVar = new dataType[arraySize];
数据类型 数组名 = new 数据类型[数组大小]注意:
1.数组的元素是通过索引访问的。数组索引从 0 开始,索引值从 0 到 arrayRefVar.length-1。
2.数组边界:下标的合法区间: [0, length-1],如果越界就会报错; ArrayIndexOutOfBoundsException :数组下标越界异常!
3.数组名称.length:取得数组长度(数组长度可以由属性length获得)。
4.数组属于引用数据类型,在使用之前一定要开辟空间(实例化),否则就会产生"NullPoninterException"。Java使用new操作符来创建数组
当数组采用动态初始化开辟空间之后,数组之中的每个元素都是该数据类型的默认值。
| 数据类型 | 默认初始化 |
|---|---|
| byte、short、int、long | 0 |
| foat、double | 0.0 |
| char | 一个空字符,即 ‘\u0000’ |
| boolean | false |
| 引用数据类型 | null,表示变量不引用任何对象 |
实例:
下面的语句首先声明了一个数组变量 nums,接着创建了一个包含 10 个 int 类型元素的数组,并且把它的引用赋值给 nums 变量。
public class ArrayDemo01 {
public static void main(String[] args) {
//变量的类型 变量的名称 = 变量的值
//声明数组
int[] nums;
//创建数组:给数组分配空间
nums = new int[10];
//int[] nums = new int[10];声明创建数组
//给数组元素赋值:数组元素通过下标(索引)访问,索引从0开始,
//没有赋值的元素有默认值 int类型默认值是0,String类型默认是null
nums[0] = 1;
nums[1] = 2;
nums[2] = 3;
nums[3] = 4;
nums[4] = 5;
nums[5] = 6;
nums[6] = 7;
nums[7] = 8;
nums[8] = 9;
nums[9] = 10;
//计算所有元素的和:for循环遍历数组
int sum = 0;
//数组长度:array.length length是数组的属性
for (int i = 0; i < nums.length; i++) {
sum = sum + nums[i];
}
System.out.println("数组元素的和为:" + sum);
//System.out.println(nums[10]); 数组下标越界
//java.lang.ArrayIndexOutOfBoundsException
}
}2、静态初始化
创建了一个dataType类型的数组,数组元素被赋值。
dataType[] arrayRefVar = {value0, value1, ..., valuek};
数据类型 [] 数组名 ={数组元素值};例如:int[] arrays = {1,2,3,4,5};
数组的初始化实例:
/*数组三种初始化
1.静态初始化
2.动态初始化
3.数组的默认初始化:数组是引用类型,它的元素相当于类的实例变量,因此数组一经分配空间,其中的每个元素也被按照实例变量同样的方式被隐式初始化。
*/
public class ArrayDemo02 {
public static void main(String[] args) {
//基本类型 静态初始化:创建数组并赋值
int[] a = {1, 2, 3};
System.out.println(a[0]);
//引用类型 静态初始化
Man[] mans = {new Man(), new Man()};
//动态初始化:包含默认初始化
int[] b = new int[5];
b[0] = 1;
b[1] = 2;
b[2] = 3;
b[3] = 4;
b[4] = 5;
System.out.println(b[0]);
}
}数组的四个基本特点:
1.长度是确定的。数组一旦被创建,它的大小就是不可以改变的。
2.元素必须是相同类型,不允许出现混合类型。
3.数组变量属引用类型,数组也可以看成是对象,数组中的每个元素相当于该对象的成员变量。
4.数组本身就是对象,Java中对象是在堆中的,因此数组无论保存原始类型还是其他对象类型,数组对象本身是在堆中的。
数组小结
1.数组是相同数据类型(数据类型可以为任意类型)的有序集合
2.数组也是对象。数组元素相当于对象的成员变量
3.数组长度的确定的,不可变的。如果越界,则报: ArrayIndexOutOfBounds
数组内存分析
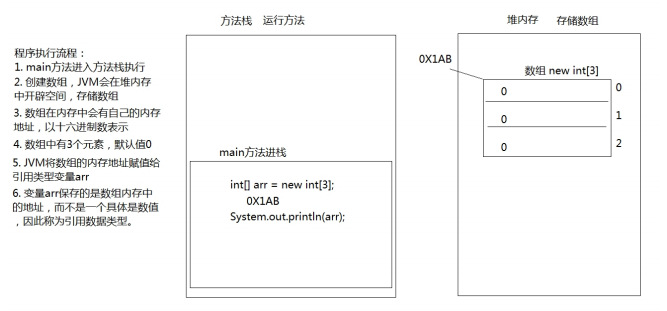
数组是一种引用数据类型,数组引用变量只是一个引用,数组元素和数组变量在内存里是分开存放的。下面将深入介绍数组在内存中的运行机制。
数组在内存中的运行机制
-
数组引用变量只是一个引用,这个引用变量可以指向任何有效的内存,只有当该引用指向有效内存后,才可通过该数组变量来访问数组元素。
-
与所有引用变量相同的是,引用变量是访问真实对象的根本方式。也就是说,如果我们希望在程序中访问数组,则只能通过这个数组的引用变量来访问它。
-
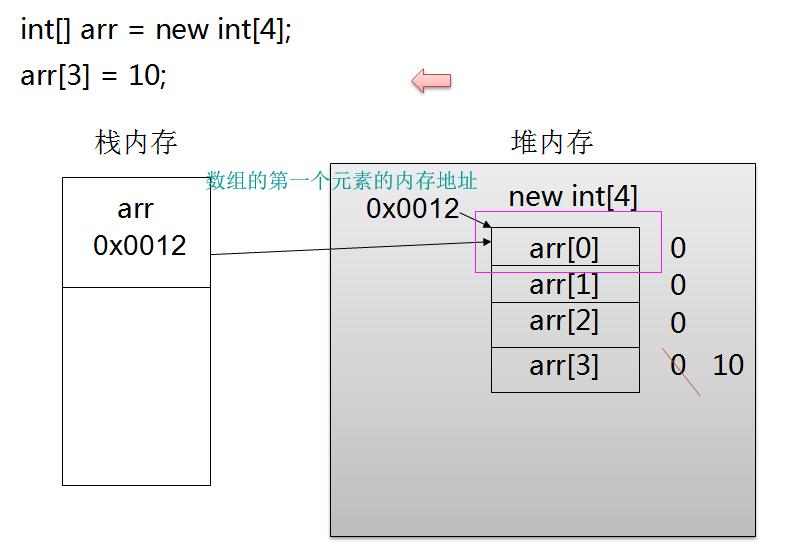
实际的数组元素被存储在堆(heap)内存中;数组引用变量是一个引用类型的变量,被存储在栈(stack)内存中。数组在内存中的存储示意图如图所示:
为什么有栈内存和堆内存之分?
-
当一个方法执行时,每个方法都会建立自己的内存栈,在这个方法内定义的变量将会逐个放入这块栈内存里,随着方法的执行结束,这个方法的内存栈也将自然销毁了。因此,所有在方法中定义的变量都是放在栈内存中的;
-
当我们在程序中创建一个对象时,这个对象将被保存到运行时数据区中,以便反复利用(因为对象的创建成本通常较大),这个运行时数据区就是堆内存。堆内存中的对象不会随方法的结束而销毁,即使方法结束后,这个对象还可能被另一个引用变量所引用(方法的参数传递时很常见),则这个对象依然不会被销毁。只有当一个对象没有任何引用变量引用它时,系统的垃圾回收机制才会在合适的时候回收它。
-
如果堆内存中数组不再有任何引用变量指向自己,则这个数组将成为垃圾,该数组所占的内存将会被系统的垃圾回收机制回收。因此,为了让垃圾回收机制回收一个数组所占的内存空间,则可以将该数组变量赋为null,也就切断了数组引用变量和实际数组之间的引用关系,实际数组也就成了垃圾。
把数组a的值赋给数组b
只要类型相互兼容,可以让一个数组变量指向另一个实际的数组,这种操作会产生数组的长度可变的错觉。如下代码所示:
public class ArrayInRam
{
public static void main(String[] args){
//定义并初始化数组,使用静态初始化
int[] a = {5, 7 , 20};
//定义并初始化数组,使用动态初始化
int[] b = new int[4];
//输出b数组的长度
System.out.println("b数组的长度为:" + b.length);
//循环输出a数组的元素
for (int i = 0 ; i < a.length ; i++ ){
System.out.println(a[i]);
}
//循环输出b数组的元素
for (int i = 0 ; i < b.length ; i++ ){
System.out.println(b[i]);
}
//因为a是int[]类型,b也是int[]类型,所以可以将a的值赋给b。
//也就是让b引用指向a引用指向的数组
b = a;
//再次输出b数组的长度
System.out.println("b数组的长度为:" + b.length);
}
}运行上面代码后,将可以看到先输出b数组的长度为4,然后依次输出a数组和b数组的每个数组元素,接着会输出b数组的长度为3。看起来似乎数组的长度是可变的,但这只是一个假象。必须牢记:定义并初始化一个数组后,在内存里分配了两个空间,一个用于存放数组的引用变量,一个用于存放数组本身。下面将结合示意图来说明上面程序的运行过程。
当程序定义并初始化了a、b两个数组后,系统内存中实际上产生了4块内存区,其中栈内存中有两个引用变量:a和b;堆内存中也有两块内存区,分别用于存储a和b引用所指向的数组本身。a引用和b引用所指向数组里数组元素的值
当执行上面粗体字标识代码:b = a代码时,系统将会把a的值赋给b,a和b都是引用类型变量,存储的是地址。因此把a的值赋给b后,就是让b指向a所指向的地址。此时计算机内存的存储示意如图所示:
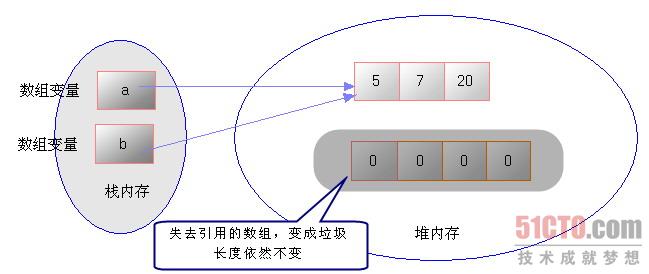
从图4.4中可以看出,当执行了b = a之后,堆内存中第一个数组具有了两个引用:a变量和b变量都指向了第一个数组。此时第二个数组失去了引用,变成垃圾,只有等待垃圾回收来回收它——但它的长度依然不会改变,直到它彻底消失。
程序员进行程序开发时,不要仅仅停留在代码表面,而要深入底层的运行机制,才可以对程序的运行机制有更准确的把握。当我们看一个数组时,一样要把数组看成两个部分:一个是数组引用,也就是在代码中定义的数组引用变量;还有一个是实际数组本身,这个部分是运行在系统内存里的,通常无法直接访问它,只能通过数组引用变量来访问它。
处理数组
数组的元素类型和数组的大小都是确定的,所以当处理数组元素时候,我们通常使用基本循环或者 For-Each 循环。
基本循环
示例
该实例完整地展示了如何创建、初始化和操纵数组:
public class TestArray {
public static void main(String[] args) {
double[] myList = {1.9, 2.9, 3.4, 3.5};
// 打印所有数组元素
for (int i = 0; i < myList.length; i++) {
System.out.println(myList[i] + " ");
}
// 计算所有元素的总和
double total = 0;
for (int i = 0; i < myList.length; i++) {
total += myList[i];
}
System.out.println("Total is " + total);
// 查找最大元素
double max = myList[0];
for (int i = 1; i < myList.length; i++) {
if (myList[i] > max) max = myList[i];
}
System.out.println("Max is " + max);
}
}以上实例编译运行结果如下:
1.9
2.9
3.4
3.5
Total is 11.7
Max is 3.5For-Each 循环
JDK 1.5 引进了一种新的循环类型,被称为 For-Each 循环或者加强型循环,它能在不使用下标的情况下遍历数组。
语法格式如下:
for(type element: array)
{
System.out.println(element);
}实例
该实例用来显示数组 myList 中的所有元素:
public class TestArray {
public static void main(String[] args) {
double[] myList = {1.9, 2.9, 3.4, 3.5};
// 打印所有数组元素
for (double element: myList) {
System.out.println(element);
}
}
}以上实例编译运行结果如下:
1.9
2.9
3.4
3.5数组作为函数的参数
数组可以作为参数传递给方法。
例如,下面的例子就是一个打印 int 数组中元素的方法:
public static void printArray(int[] array) {
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + " ");
}
}下面例子调用 printArray 方法打印出 3,1,2,6,4 和 2:
printArray(new int[]{3, 1, 2, 6, 4, 2});数组作为函数的返回值
public static int[] reverse(int[] list) {
int[] result = new int[list.length];
for (int i = 0, j = result.length - 1; i < list.length; i++, j--) {
result[j] = list[i];
}
return result;
}以上实例中 result 数组作为函数的返回值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









