






 博客指出爬虫爬取内容可能出现乱码,原因是网页编码方式与requests默认编码方式不同。可在网页head中查看网页编码,通过代码查看requests编码。处理乱码需使二者匹配,对str二次解析可解决编码不一致问题并拿到标签内内容。
博客指出爬虫爬取内容可能出现乱码,原因是网页编码方式与requests默认编码方式不同。可在网页head中查看网页编码,通过代码查看requests编码。处理乱码需使二者匹配,对str二次解析可解决编码不一致问题并拿到标签内内容。
在爬虫使用的过程中,可能会出现爬取的内容是乱码的情况,就像下面这样
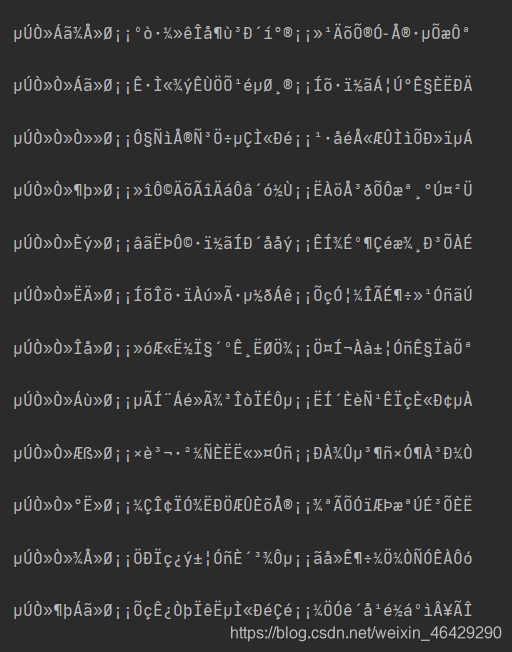
造成上述乱码情况的原因是因为网页的编码方式和requests的默认编码方式 不同造成的,网页的编码方式可以在网页head中查找到

可以看到网页的编码方式采用的是gbk,而requests的编码方式可以通过一下代码块进行查看
import requests
url = 'https://www.baidu.com/s?'
response = requests.get(url)
print(response.encoding)
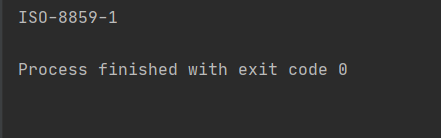
可以看到requests的编码方式是ISO-8859-1
这是处理乱码就需要将网页编码方式和requests编码方式匹配
aa = aa.encode('iso-8859-1').decode('gbk')
处理乱码采用的是以上代码,aa的数据类型是str,如果要使用text方法将标签中的内容拿到,还要对str进行二次解析
for dd in dds:
aa=dd.find('a')
#处理乱码
aa = aa.encode('iso-8859-1').decode('gbk')
aa=BeautifulSoup(aa,'html.parser')
print(aa.text,'\n')
这样就解决了编码不一致的乱码问题并拿到标签内的内容



















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











