




一、系统设计的基本原理
(一) 抽象
抽象是一种设计技术,重点说明一个实体的本质方面,而忽略或者掩盖不很重要或非本质的方面。
软件工程中从软件定义到软件开发要经历多个阶段,在这个过程中每前进一步都可看作是对软件解法的抽象层次的一次细化。
抽象的最低层就是实现该软件的源程序代码。
①最高抽象层次的模块用概括的方式叙述问题的解法,
②较低抽象层次的模块是对较高抽象层次模块对问题解法描述的细化。
(二) 模块化
模块在程序中是数据说明、可执行语句等程序对象的集合,或者是单独命名和编址的元素,如高级语言中的过程、函数和子程序等。
在软件的体系结构中,模块是可组合、分解和更换的单元。
模块化是指将一个待开发的软件分解成若干个小的简单部分一模块,每个模块可独立地开发、测试,最后组装成完整的程序。这是一种复杂问题“分而治之”的原则。
模块化的目的是使程序的结构清晰,容易阅读、理解、测试和修改。
(三) 信息隐蔽
信息隐蔽是开发整体程序结构时使用的法则,即将每个程序的成分隐蔽或封装在一个单一的设计模块中,定义每一个模块时尽可能少地显露其内部的处理。
在设计时首先列出一些可能发生变化的因素,在划分模块时将一个可能发生变化的因素隐蔽在某个模块的内部,使其他模块与这个因素无关。在这个因素发生变化时,只需修改含有这个因素的模块,而与其他模块无关。
信息隐蔽原则对提高软件的可修改性、可测试性和可移植性都有重要的作用。
(四) 模块独立
模块独立是指每个模块完成一个相对独立的特定子功能,并且与其他模块之间的联系简单。
衡量模块独立程度的标准有两个:耦合性和内聚性。
1.耦合性
耦合是模块之间的相对独立性(互相连接的紧密程度) 的度量。
高低取决于模块间接口的复杂性、调用的方式及传递的信息。
耦合性高,指连接性强,则模块独立性弱。
一般模块之间可能的耦合方式有7种类型:
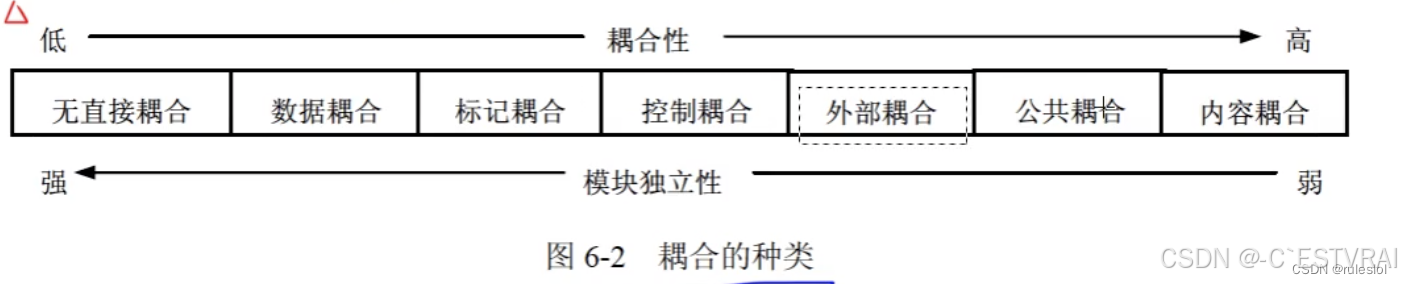
(1)无直接耦合
指两个模块间没有直接的关系,它们分别从属于不同模块的控制与调用,它们之间不传递任何信息。因此,模块间耦合性最弱,模块独立性最高。
(2)数据耦合
指两个模块之间有调用关系,传递的是简单的数据值,相当于高级语言中的值传递。这种耦合程度较低,模块的独立性较高。
(3)标记耦合
指两个模块之间传递的是数据结构,如高级语言中的数据组名、记录名、文件名等这些名字即为标记,其实传递的是这个数据结构的地址。
(4)控制耦合
指一个模块调用另一个模块时,传递的是控制变量,被调模块通过该控制
变量的值有选择地执行块内的某一功能。
(5)公共耦合
指通过一个公共数据环境相互作用的那些模块之间的耦合。
两个模块之间没有直接联系。
比如 模块A和模块B通过外部变量来交换输入、输出信息。
(6)内容耦合
这是程度最高的耦合。当一个模块直接使用另一个模块的内部数据,或通过非正常入口而转入另一个模块内部,这种模块之间的耦合为内容耦合,这种情况往往出现在汇编程序设计中。
(7)外部耦合
模块间通过软件之外的环境联结(如I/O 将模块合到特定的设备、格式通信协议上) 时称为外部耦合。
2.内聚性
内聚是指模块内部各元素之间联系的紧密程度,例如一个完成多个功能的模块的内聚度就比完成单一功能的模块的内聚度低。
内聚度越低,模块的独立性越差。
内聚性有以下几种类型:
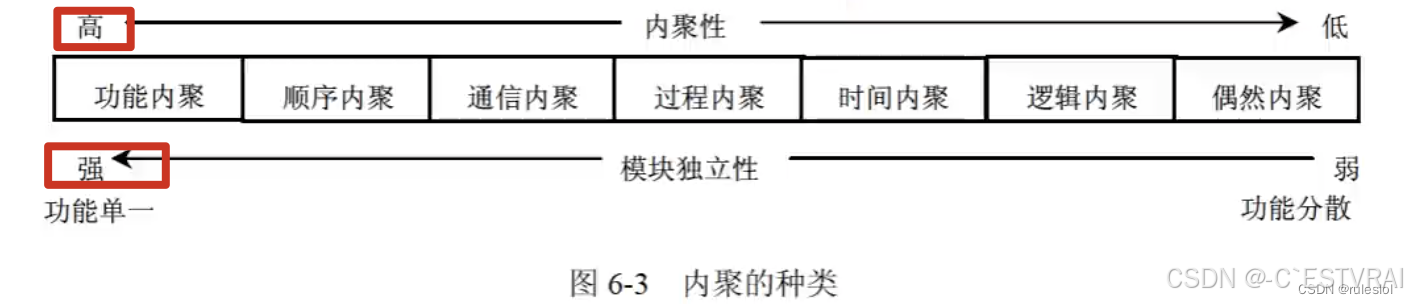
(1)偶然内聚
指一个模块内的各个处理元素之间没有任何联系。
(2)逻辑内聚
指模块内执行几个逻辑上相似的功能,通过参数确定该模块完成哪一个功能。
(3)时间内聚
把需要同时执行的动作组合在一起形成的模块为时间内聚模块。
(4)通信内聚
指模块内所有处理元素都在同一个数据结构上操作,或者指各处理使用相同的输入数据或者产生相同的输出数据。
(5)顺序内聚
指一个模块中各个处理元素都密切相关于同一功能且必须顺序执行,前一
功能元素的输出就是下一功能元素的输入。
(6)功能内聚
这是最强的内聚,指模块内所有元素共同完成一个功能,缺一不可。
耦合性和内聚性是模块独立性的两个定性标准,将软件系统划分模块时,尽量做到高内聚、低耦合,提高模块的独立性
二、系统文档
二.数据流图和数据字典
数据流图也称数据流程图 (Data Flow Diagram,DFD)。
1.数据流图的基本符号

数据源点和终点(外部实体) E External Agent
指系统外部环境中的实体(包括人员、组织或其他系统)

==处理 P Process ==
它对数据流进行某些操作或变换。每个处理有名字,通常是动词短语,简明地描述完成什么加工。在分层的数据流图中,加工还应有编号。

数据存储 D Date store
存储数据和提供数据,存储加工的输出数据和提供加工的输入数据,XXX表,XXX文件居多

数据流 Data Flow
数据流应该用名词或名词短语命名。

2.数据流图层次结构
顶层数据流程图: 只有 数据流和外部实体,描述系统的输入输出。
第0层数据流图:描绘系统的主要功能,给处理和数据存储都加 编号,便于引用和追踪。
第1层数据流图:细化功能

2.1 数据流图的设计原则
1、父图-子图平衡原则
即父图输入输出数据流等于子图输入输出数据流。在对数据流图分层细化时必须保持信息连续性,即当把一个处理分解为一系列处理时,分解前和分解后的输入/输出数据流必须相同。
2、数据守恒原则

3、守恒加工原则
每个加工至少有一个输入数据流和一个输出数据流

3.画数据流图
数据流图有4种成分:源点和终点、处理、数据存储和数据流。
例子:
假设一家工厂的采购部每天需要一张订货报表,报表按零件编号排序,表中列出所有需要再次订货的零件。对于每个需要再次订货的零件应该列出下述数据:零件编号,零件名称,订货数量,目前价格,主要供应者,次要供应者。零件入库或出库称为事务。通过放在仓库中的CRT终端把事务报告给订货系统。当某种零件的库存数量少于库存量临界值时就应该再次订货。
源点和终点
一家工厂的采购部每天需要一张订货报表。零件入库或出库称为事务。通过放在仓库中的CRT终端把事务报告给订货系统。
这个系统最终要给采购部一张订货单。所以 终点 是 采购员;仓库管理员做出库入库等工作货物不够需要提交申请给系统,所以 源点 是 仓库管理员。
处理
需要一张订货报表 = 产生订货报表,入库出库需要改变库存量=事务处理
数据存储
库存清量、订货报表
数据流
订货信息、库存清单、订货报表
顶层数据流图:

第0层数据流图

第1层数据流图




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











