






01.启动hdfs
(base) [root@192 ~]# cd $HADOOP_HOME
(base) [root@192 hadoop-2.7.7]# ls
bin etc include lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share
(base) [root@192 hadoop-2.7.7]# cd sbin/
(base) [root@192 sbin]# ls
distribute-exclude.sh hdfs-config.sh refresh-namenodes.sh start-balancer.sh start-yarn.cmd stop-balancer.sh stop-yarn.cmd
hadoop-daemon.sh httpfs.sh slaves.sh start-dfs.cmd start-yarn.sh stop-dfs.cmd stop-yarn.sh
hadoop-daemons.sh kms.sh start-all.cmd start-dfs.sh stop-all.cmd stop-dfs.sh yarn-daemon.sh
hdfs-config.cmd mr-jobhistory-daemon.sh start-all.sh start-secure-dns.sh stop-all.sh stop-secure-dns.sh yarn-daemons.sh
(base) [root@192 sbin]# ./start-dfs.sh
Starting namenodes on [192.168.1.10]
192.168.1.10: namenode running as process 18267. Stop it first.
localhost: datanode running as process 18455. Stop it first.
Starting secondary namenodes [0.0.0.0]
0.0.0.0: secondarynamenode running as process 18690. Stop it first.
(base) [root@192 sbin]#
02.查看节点状态
(base) [root@192 sbin]# jps
18690 SecondaryNameNode
18455 DataNode
114377 Jps
18267 NameNode
03.可以使用Linux命令操作hdfs文件,这里就简单的看一下hdfs,目录下的文件
(base) [root@192 sbin]# hdfs dfs -ls -R /
drwxr-xr-x - root supergroup 0 2022-01-27 01:21 /HadoopFileS
drwxr-xr-x - root supergroup 0 2022-01-26 04:44 /HadoopFileS/DataSet
drwxr-xr-x - root supergroup 0 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn
drwxr-xr-x - root supergroup 0 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D02
-rw-r--r-- 1 root supergroup 65 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D02/wc.txt
drwxr-xr-x - root supergroup 0 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D04
-rw-r--r-- 1 root supergroup 11 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D04/RowMatrix.txt
-rw-r--r-- 1 root supergroup 56 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D04/loadLibSVMFile.txt
-rw-r--r-- 1 root supergroup 9 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D04/testCorrectX.txt
-rw-r--r-- 1 root supergroup 10 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D04/testCorrectY.txt
-rw-r--r-- 1 root supergroup 20 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D04/testSingleCorrect.txt
-rw-r--r-- 1 root supergroup 34 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D04/testStratifiedSampling.txt
-rw-r--r-- 1 root supergroup 9 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D04/testSummary.txt
drwxr-xr-x - root supergroup 0 2022-01-26 04:44 /HadoopFileS/DataSet/DataSet_sparklearn/D05
04.可以从配置xml中打开hdfs的web网页
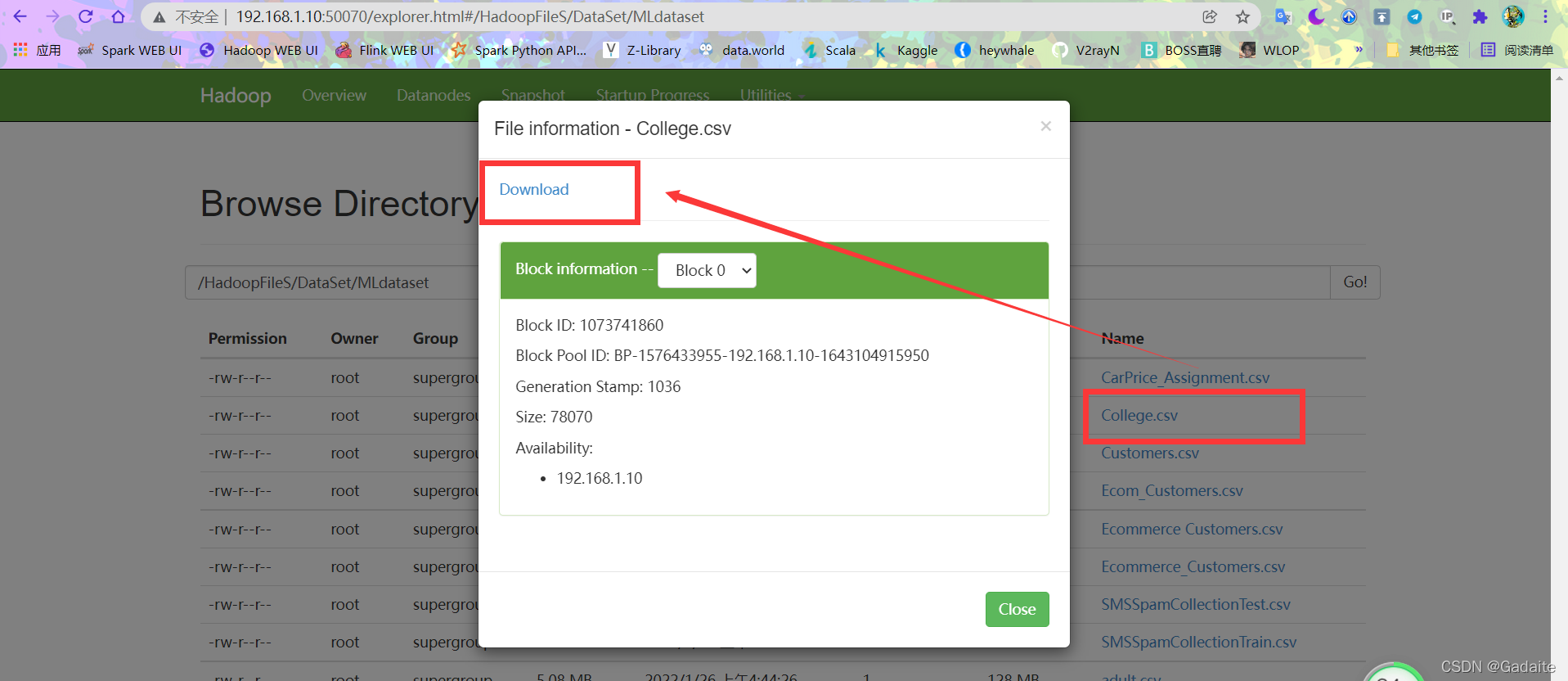
hdfs文件系统可以直接从与hdfs交互的该网页上进行下载
05.这里不介绍Linux终端上的操作,以java代码的方式实现操作hdfs
maven就自行加载,这个有手就行
06.使用java和junit测试hdfs操作代码:
06.01.查看信息
package GadaiteGroupID.Hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.*;
import java.io.IOException;
import java.net.URI;
public class CatINFO {
FileSystem fileSystem = null;
@Before
public void init() throws Exception{
Configuration configuration = new Configuration();
fileSystem = FileSystem.get(new URI("hdfs://192.168.1.10:9000"),
configuration,"root");
}
@Test
public void catinfo() throws Exception{
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(new Path("/"),true);
while (iterator.hasNext()){
LocatedFileStatus fileStatus = iterator.next();
System.out.println("文件路径是:"+fileStatus.getLen());
System.out.println("副本数为:"+fileStatus.getBlockLocations());
System.out.println("bloc为:"+fileStatus.getReplication());
}
}
@After
public void close(){
try {
fileSystem.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
部分输出输出信息如下:
文件路径是:65
副本数为:[Lorg.apache.hadoop.fs.BlockLocation;@32c8e539
bloc为:1
文件路径是:11
副本数为:[Lorg.apache.hadoop.fs.BlockLocation;@73dce0e6
bloc为:1
文件路径是:56
副本数为:[Lorg.apache.hadoop.fs.BlockLocation;@5a85c92
bloc为:1
文件路径是:9
副本数为:[Lorg.apache.hadoop.fs.BlockLocation;@32811494
bloc为:106.02.连接hdfs并读取文件
package GadaiteGroupID.Hadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
public class ConnectHdfs {
public static void main(String[] args) {
try {
// 配置连接地址
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.10:9000");
FileSystem fs = FileSystem.get(conf);
// 打开文件并读取输出
Path test = new Path("/HadoopFileS/DataSet/Others/bank_train.csv");
FSDataInputStream ins = fs.open(test);
int ch = ins.read();
System.out.println(ch);
while (ch != -1) {
System.out.print((char)ch);
ch = ins.read();
}
System.out.println();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
输出结果:
06.03.从hdfs下载文件:
package GadaiteGroupID.Hadoop;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.conf.Configuration;
import org.junit.*;
import java.io.*;
import java.net.URI;
public class Download_File {
FileSystem fileSystem = null;
@Before
public void init() throws Exception{
Configuration configuration = new Configuration();
fileSystem = FileSystem.get(new URI("hdfs://192.168.1.5:9000"),configuration,"root");
}
@Test
public void download(){
try{
fileSystem.copyToLocalFile(new Path("/Hadoopfiles/bank_train.csv"),
new Path("F:\\CodeG50\\sparkAll\\src\\main\\scala\\GadaiteGroupID\\TestData\\bank_train.csv"));
}catch (IOException e){
e.printStackTrace();
}
}
@After
public void close(){
try{
fileSystem.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
06.04.创建hdfs文件
package GadaiteGroupID.Hadoop;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.conf.Configuration;
import org.junit.*;
import java.io.*;
import java.net.URI;
public class Mkdir {
FileSystem fileSystem = null;
@Before
public void init() throws Exception{
Configuration configuration = new Configuration();
fileSystem= FileSystem.get(new URI("hdfs://192.168.1.5:9000"),configuration,"root");
}
@Test
public void mkdir(){
try{
fileSystem.mkdirs(new Path("/Ideatest"));
}catch (IOException e){
e.printStackTrace();
}
}
@After
public void close(){
try{
fileSystem.close();
}catch (IOException e){
e.printStackTrace();
}
}
}
06.05.删除文件
package GadaiteGroupID.Hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.*;
import java.net.URI;
import java.io.*;
public class Mvdir {
FileSystem fileSystem = null;
@Before
public void init() throws Exception{
Configuration configuration = new Configuration();
fileSystem = FileSystem.get(new URI("hdfs://192.168.1.5:9000"),configuration,"root");
}
@Test
public void mvdir(){
try{
fileSystem.delete(new Path("/Ideatest"));
}catch (IOException e){
e.printStackTrace();
}
}
@After
public void close(){
try{
fileSystem.close();
}catch (IOException e){
e.printStackTrace();
}
}
}
06.06.上传文件
package GadaiteGroupID.Hadoop;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.conf.Configuration;
import org.junit.*;
import java.io.*;
import java.net.URI;
public class Upload_File {
FileSystem fileSystem = null;
@Before
public void init() throws Exception {
Configuration configuration =new Configuration();
fileSystem =FileSystem.get(new URI("hdfs://192.168.1.5:9000"),configuration,"root");
}
//上传一个文件
@Test
public void upload(){
try {
fileSystem.copyFromLocalFile(new Path("F:\\CodeG50\\sparkAll\\src\\main\\scala\\GadaiteGroupID\\DataSets\\bank_train.csv"),new Path("/Hadoopfiles"));
} catch (IOException e) {
e.printStackTrace();
}
}
@After
public void close(){
try {
fileSystem.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









