







 本文详细阐述了关系数据库设计中的第一、第二和第三范式,通过实例说明如何确保数据的原子性、表结构的一致性和减少数据冗余。通过拆分Address、Message和Student表,展示了如何遵循范式原则以创建高效、结构清晰的数据库。
本文详细阐述了关系数据库设计中的第一、第二和第三范式,通过实例说明如何确保数据的原子性、表结构的一致性和减少数据冗余。通过拆分Address、Message和Student表,展示了如何遵循范式原则以创建高效、结构清晰的数据库。
数据库三范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构清晰的。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
关系型数据库:指采用了关系模型来组织数据的数据库,关系模型可以简单理解为二维表格模型,用户通过查询来检索数据库中的数据。
第一范式:确保每列的原子性
第一范式是最基本的范式,如果数据表中所有字段值都是不可分解的原子值,表名数据库满足了第一范式。第一范式的要求需要根据实际需求来决定。
原子性:指事务的不可分割性,一个事务的所有操作要么不间断地全部被执行,要么一个也没有执行。
假设现在的需求是创建一张表,表中需要存储姓名和对应姓名的详细地址,此表Address如下图:
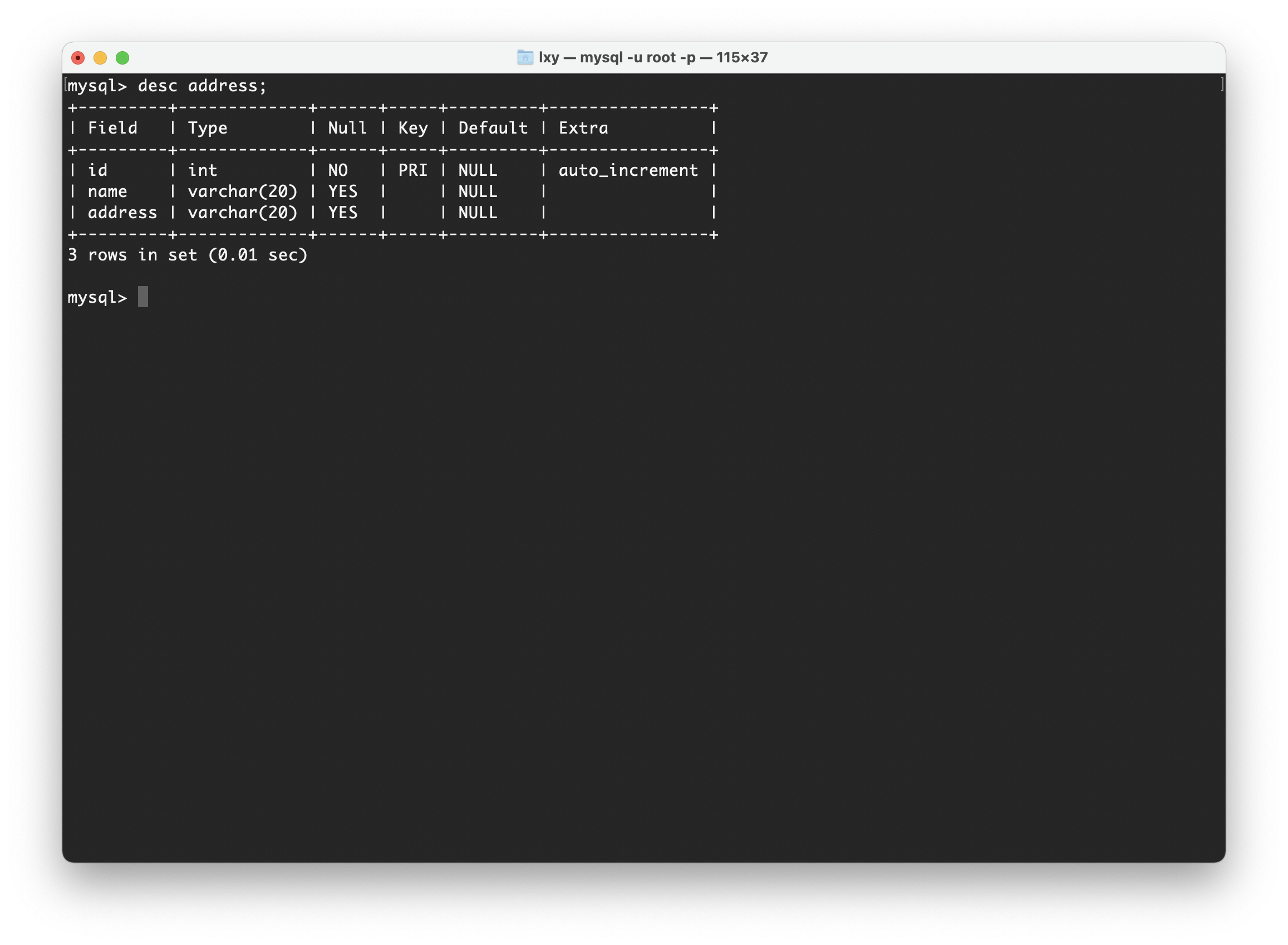
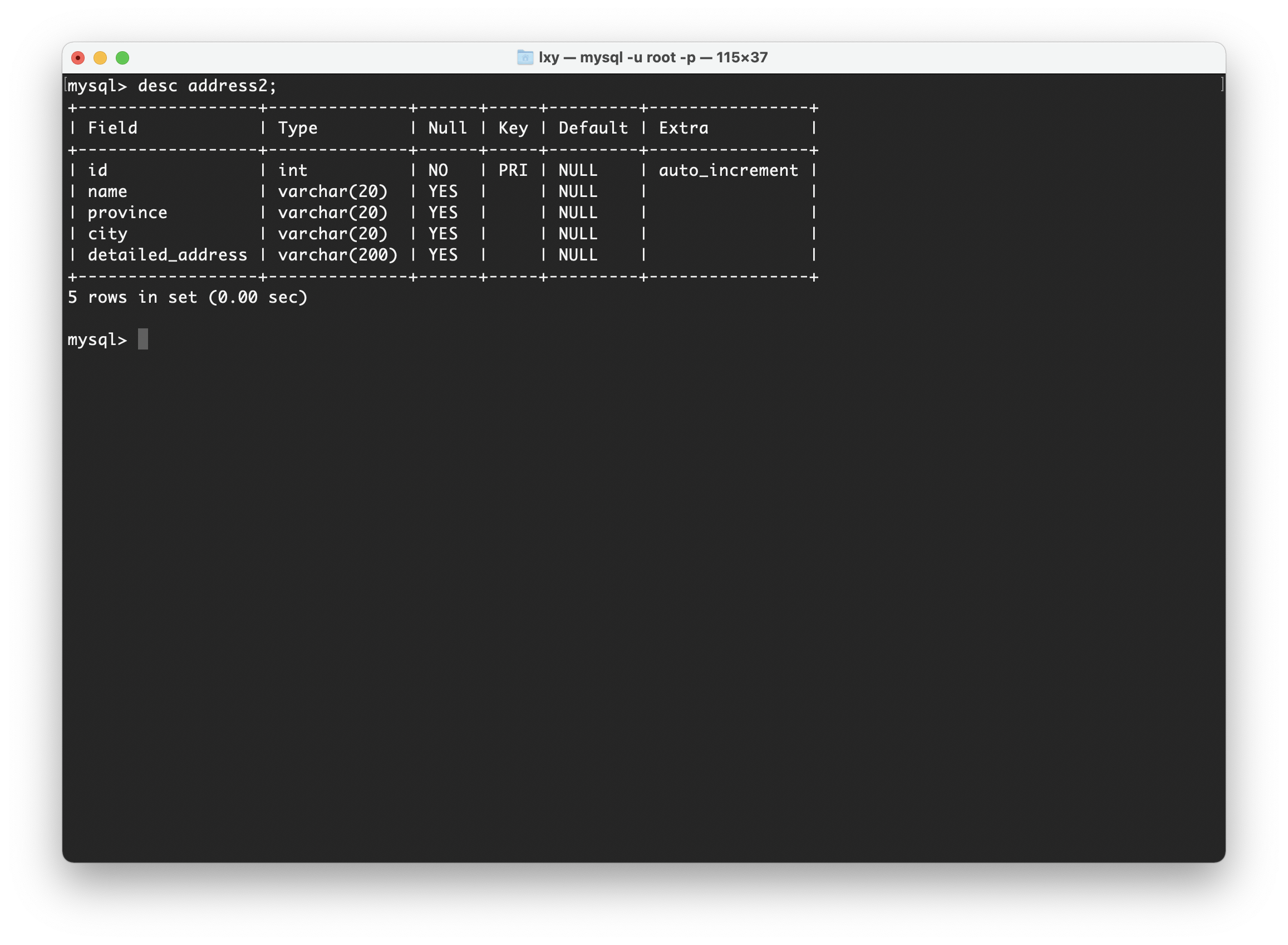
我们知道,第一范式的要求需要根据实际需求来决定,本来直接将“地址”属性设计成一个数据库表的字段就行。但是我们现在要存储的是详细地址,这样就必须要将这个“地址”属性拆分成“省份”、“城市”、“详细地址”等多个部分,保证了所有字段值都是不可分解的原子值(“地址”可以分解为“城市”、“省份”等,但是“城市”、“省份”字段不能继续向下分解),这样设计才满足了数据库的第一范式。
所以正确的表Address2如下图:
第二范式:表中每列都和主键相关
第二范式是在第一范式的基础上建立起来的。第二范式要求满足第一范式的同时确保数据库表中的每一列都和主键相关,而不能与主键的某一个部分相关。也就是说在一个表中只能保存一种数据,不可以把多种数据保存在同一张数据表中。现有一个订单信息表Message,字段分别是“订单编号”,“商品编号”,“商品名称”,“数量”,“单位”,“价格”,“客户”,“联系方式”。
主键:保证记录的唯一性,自动为NOT NULL
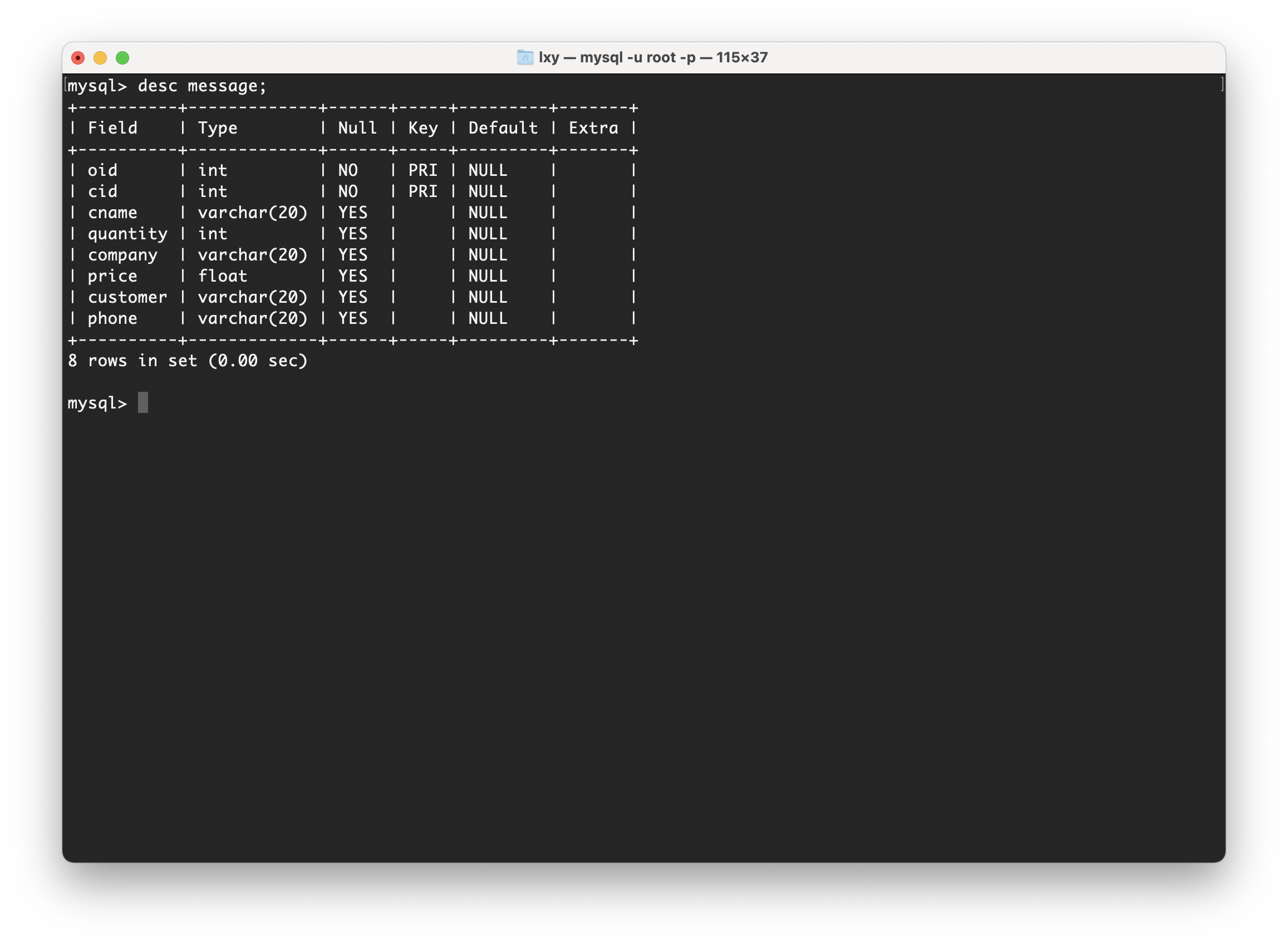
通过这个表,我们可以看出里面包含了两大元素,一个是订单编号作为主键的订单项目表,一个是商品编号作为主键的商品信息表,在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
所以我们可以将这个表进行拆分,让与对应主键不相关的元素分离出对应表。
订单项目表Orders包括“订单编号”,“客户”,“联系方式”,“数量”,如下图:

商品信息表Wares包括“商品编号”,“商品名称”,“单位”,“价格”,如下图:
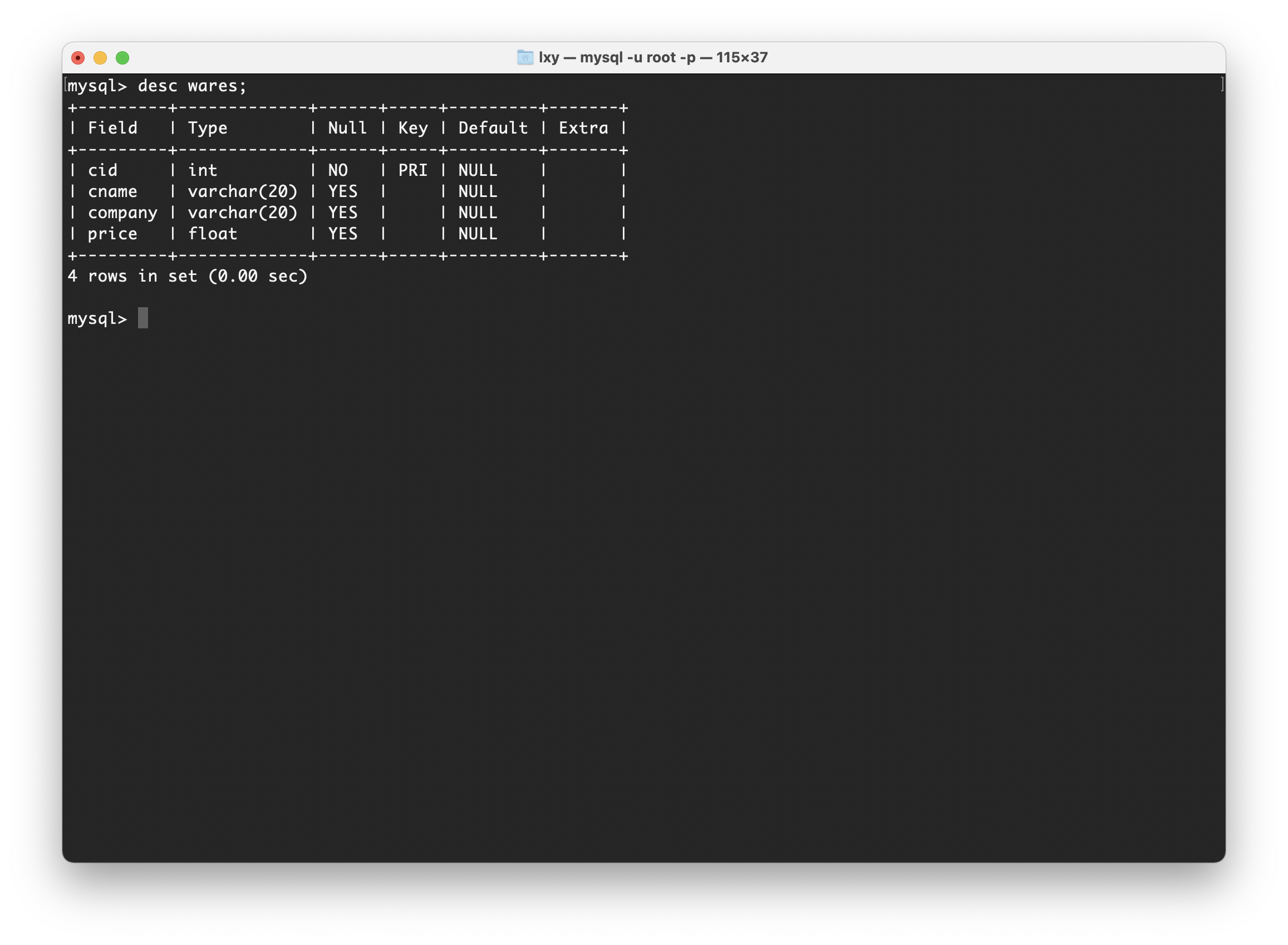
通过将原先的Message表分离成两个表,确保了表中的每列都和主键相关,遵循了第二范式。
第三范式:属性直接依赖于主键
属性直接依赖于主键,简单来说就是需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。比如A—B---C,A和B有直接关系,但是A和C没有直接关系,只有通过B的间接关系,所以不符合第三范式。
现有一个Student表,其中包含字段“学号”,“姓名”,“年龄”,“性别”,“所在院校”,“院校地址”,如下图:
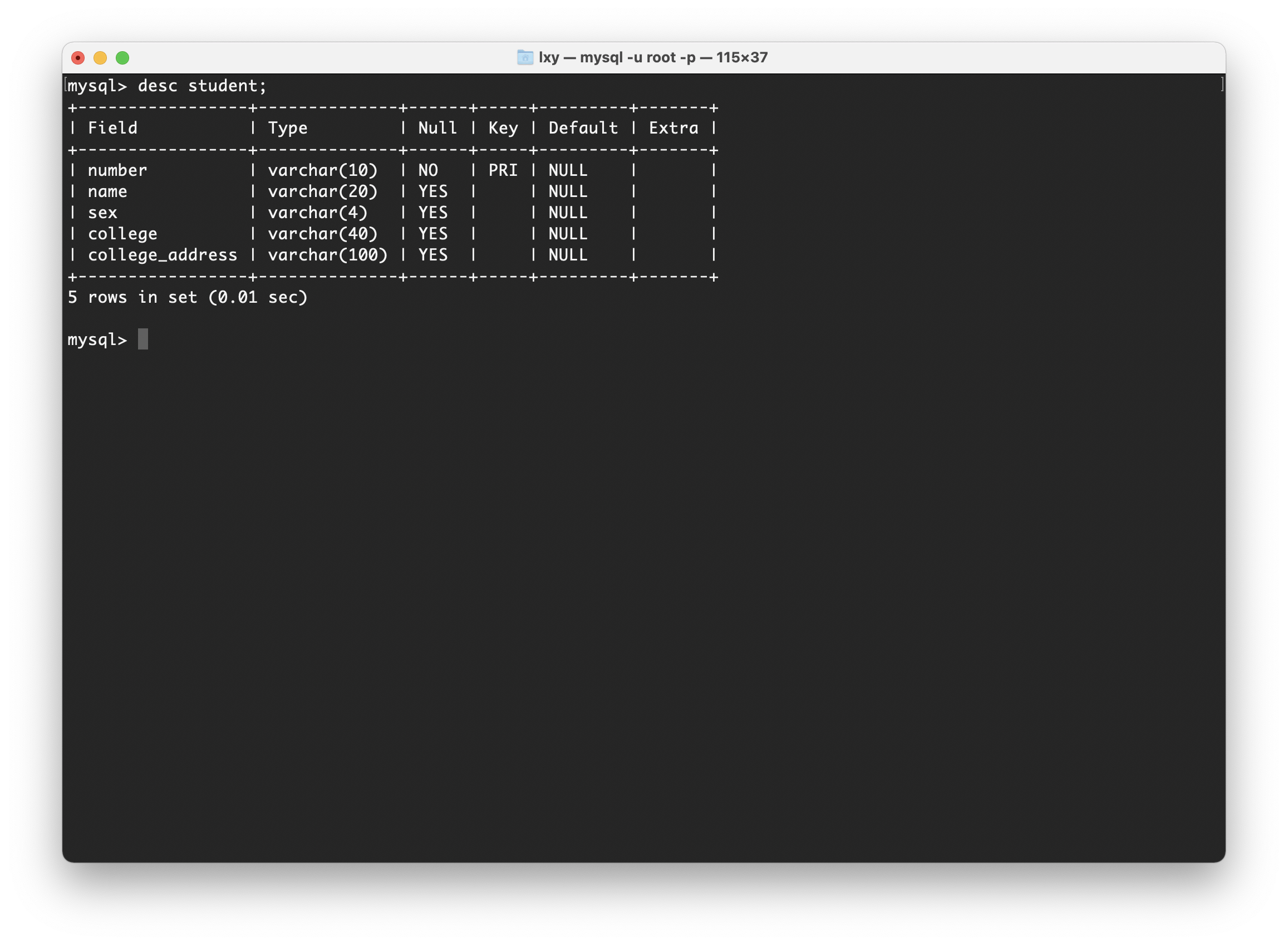
在此表中,学号是主键,姓名、性别属性与学号有直接关系(都是用于描述学生),但是所在院校和院校地址与学号只有间接关系,所以此表不符合第三范式。对于此表,我们可以将表拆分为两个表,一个学生信息表Students,一个所在院校表Colleges,将姓名设置为外键与所在院校表建立联系,如下图:
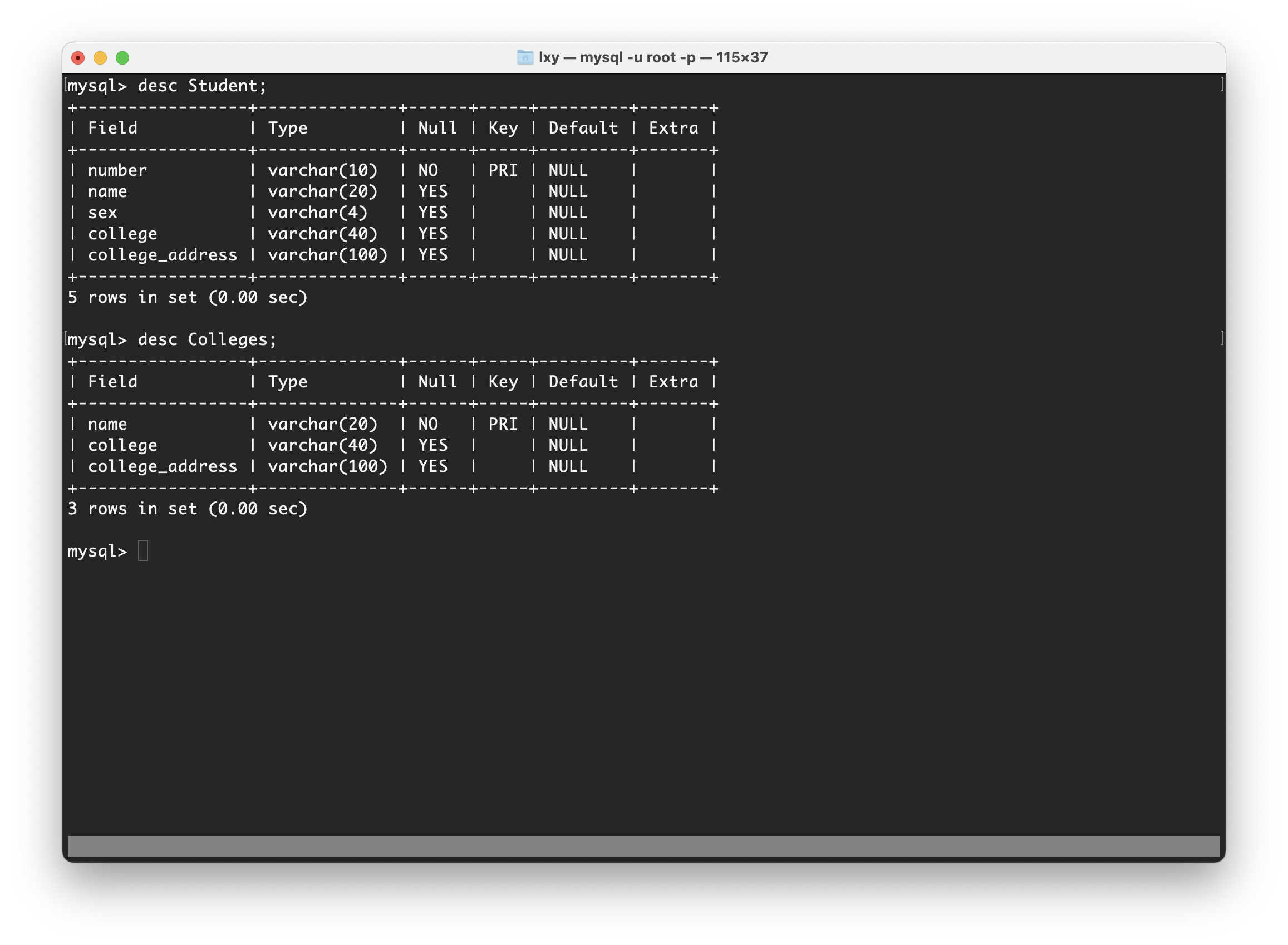
将Student表拆分成Students表和Colleges表的操作,遵循了第三范式。
参考资料
https://www.cnblogs.com/linjiqin/archive/2012/04/01/2428695.html

















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









