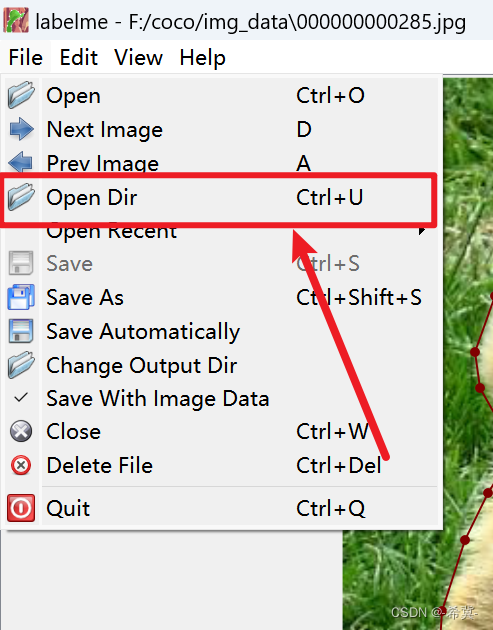
文章目录 一、环境配置与安装 二、使用labelme进行标注 三、数据集转化 3.1 转VOC 3.2 转coco 一、环境配置与安装 环境配置: 进入base环境下输入 conda create -n labelme 输入以下命令切入环境 conda activate labelme 安装: 直接输入命令 pip install labelme 二、使用labelme进行标注 打开,直接在当前环境下输入labelme crtl+n打开标注框 ctrl+z取消上一个标注点 打开图片所在的文件夹 进行标注,标注完成后记得保存








 本文介绍了如何配置环境并使用labelme进行图像标注,然后详细阐述了将标注数据转化为VOC和COCO两种格式的步骤,包括修改json文件、运行转换脚本等操作。
本文介绍了如何配置环境并使用labelme进行图像标注,然后详细阐述了将标注数据转化为VOC和COCO两种格式的步骤,包括修改json文件、运行转换脚本等操作。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1585
1585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








