







2121SC@SDUSC
storm-executor-spout(2)
用一个spout读取Twitter数据。采用拓扑并行化,多个spout从同一个流读取数据的不同部分。如果有多个流要读取,可以在任意组件内(spouts/bolts)访问TopologyContext。利用这一特性,能够把流划分到多个spouts读取。
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
//从context对象获取spout大小
int spoutsSize =
context.getComponentTasks(context.getThisComponentId()).size();
//从这个spout得到任务id
int myIdx = context.getThisTaskIndex();
String[] tracks = ((String) conf.get("track")).split(",");
StringBuffer tracksBuffer = new StringBuffer();
for(int i=0; i< tracks.length;i++){
//Check if this spout must read the track word
if( i % spoutsSize == myIdx){
tracksBuffer.append(",");
tracksBuffer.append(tracks[i]);
}
}
if(tracksBuffer.length() == 0) {
throw new RuntimeException("没有为spout得到track配置" +
" [spouts大小:"+spoutsSize+", tracks:"+tracks.length+"] tracks的数量必须高于spout的数量");
this.track =tracksBuffer.substring(1).toString();
}
...
}
可以把collector对象均匀的分配给多个数据源
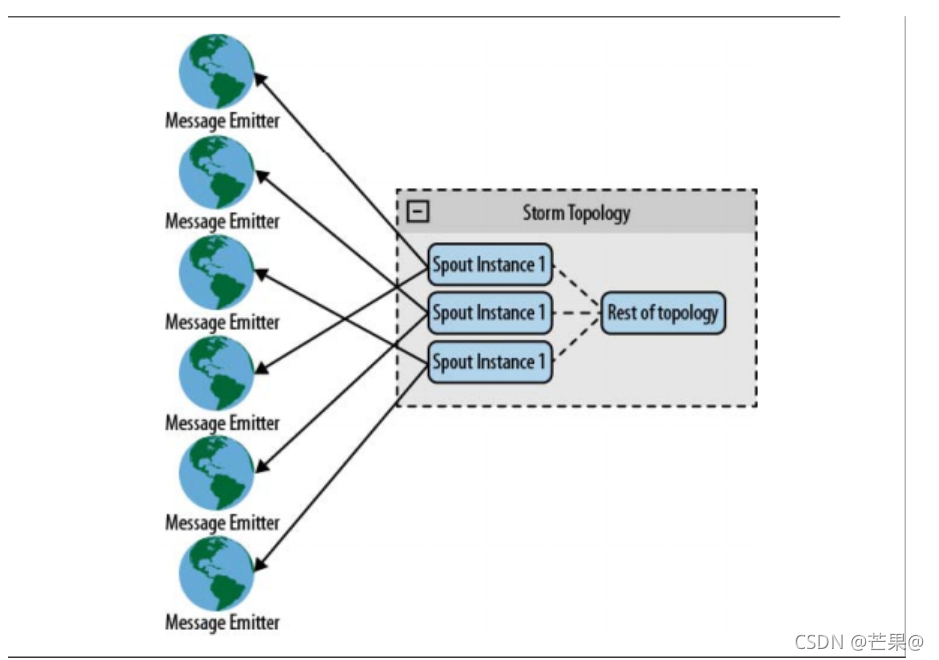
从一个spout连接到已知设备。也可以使用相同的方法连接未知设备,不过需要借助于一个协同系统维护的设备列表。协同系统负责探察列表的变化,并根据变化创建或销毁连接。比如,从web服务器收集日志文件时,web服务器列表可能随着时间变化。当添加一台web服务器时,协同系统探查到变化并为它创建一个新的spout。
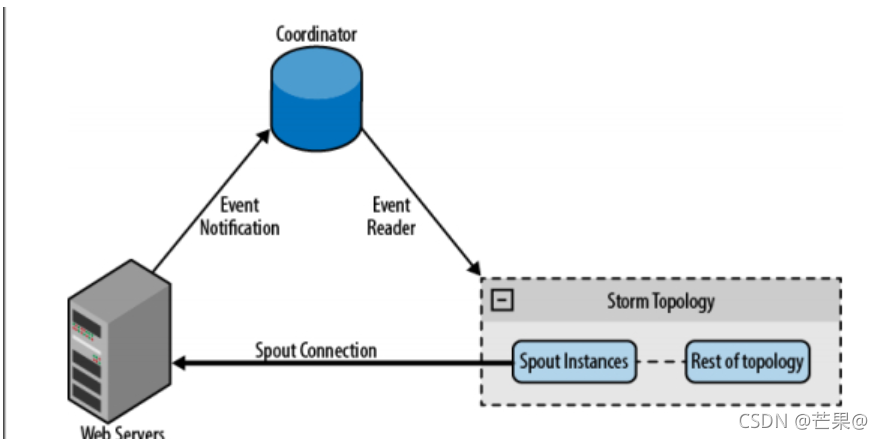
消息队列
第二种方法是,通过一个队列系统接收来自消息分发器的消息,并把消息转发给spout。更进一步的做法是,把队列系统作为spout和数据源之间的中间件,可以利用多队列系统的重播能力增强队列可靠性。不需要知道有关消息分发器的任何事情,而且添加或移除分发器的操作比直接连接简单的多。这个架构的问题在于队列是一个故障点,另外还要为处理流程引入新的环节。
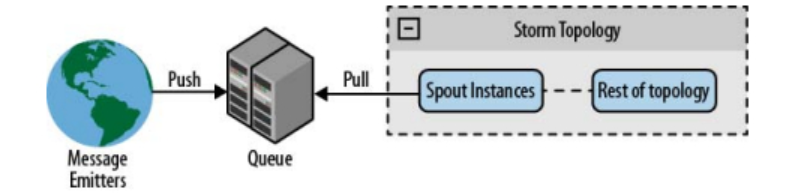
注:可以通过轮询队列或哈希队列(把队列消息通过哈希发送给spouts或创建多个队列使队列spouts一一对应)在多个spouts之间实现并行性。
在spout的open方法创建一个线程,用来获取消息(使用线程是为了避免锁定nextTuple在主循环的调用):
new Thread(new Runnable() {
@Override
public void run() {
try{
Jedis client= new Jedis(redisHost, redisPort);
List res = client.blpop(Integer.MAX_VALUE, queues);
messages.offer(res.get(1));
}catch(Exception e){
LOG.error("从redis读取队列出错",e);
try {
Thread.sleep(100);
}catch(InterruptedException e1){}
}
}
}).start();
这个线程的惟一目的就是,创建redis连接,然后执行blpop命令。每当收到了一个消息,它就被添加到一个内部消息队列,然后会被nextTuple消费。对于spout来说数据源就是redis队列,它不知道消息分发者在哪里也不知道消息的数量。
注:不要在spout创建太多线程,因为每个spout都运行在不同的线程。可以增加拓扑并行性,也就是通过Storm集群在分布式环境创建更多线程。
在nextTuple方法中,要做的惟一的事情就是从内部消息队列获取消息并再次分发它们。
public void nextTuple(){
while(!messages.isEmpty()){
collector.emit(new Values(messages.poll()));
}
}
注:可以借助redis在spout实现消息重发,从而实现可靠的拓扑。
小结
不存在适用于所有拓扑的架构模式。如果知道数据源,并且能够控制它们,就可以使用直接连接;然而如果需要添加未知数据源或从多种数据源接收数据,就最好使用消息队列。如果要执行在线过程,你可以使用DRPCSpout或类似的实现。
知识点学习:https://ifeve.com/getting-started-with-storm-4/

















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









