







数据预处理
缺失值处理
import pandas as pd
import numpy as np
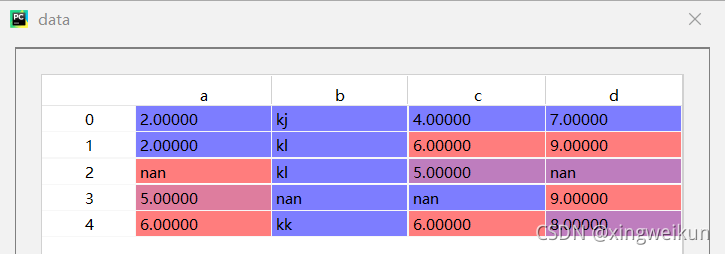
data=pd.read_excel('missing.xlsx')#数据框data
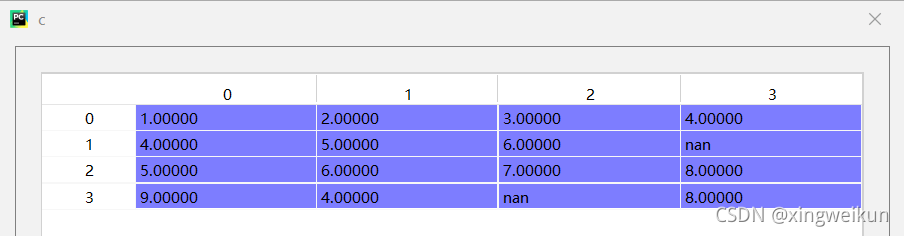
c=np.array([[1,2,3,4],[4,5,6,np.nan],[5,6,7,8],[9,4,np.nan,8]])#数组c
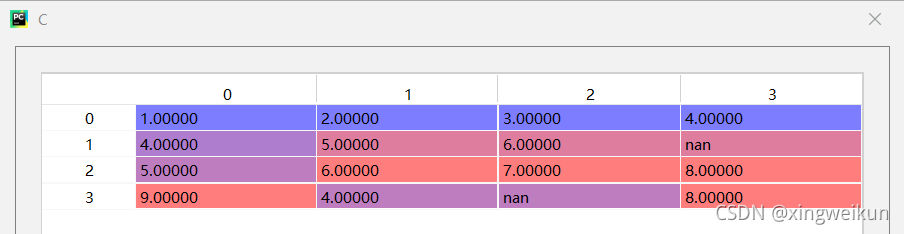
C=pd.DataFrame(c)#数据框C
使用Scikit-learn中的数据预处理模块进行缺失值填充
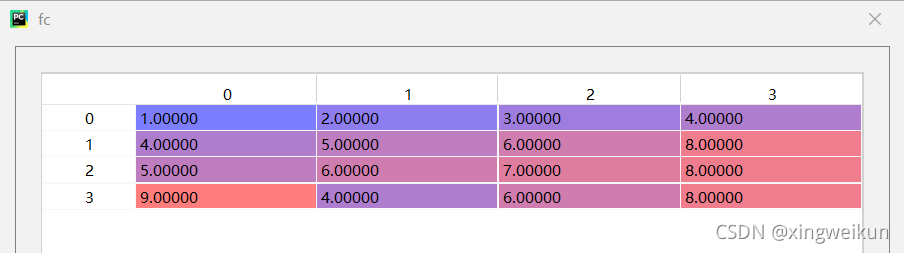
下面对C数据框中的数据采用按列均值填充
对c数组中的数据采用按行中位数填充
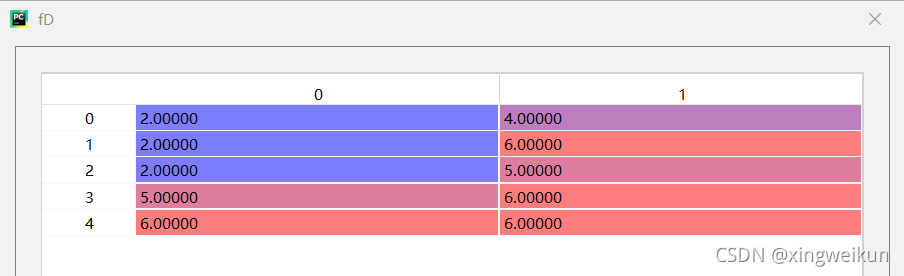
对data数据中的a,c列采用按列最频繁值填充进行填充
from sklearn.impute import SimpleImputer
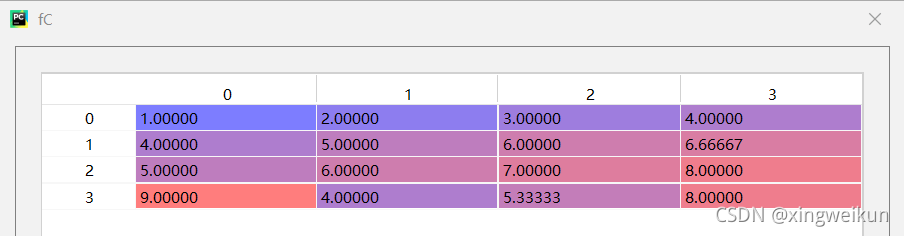
fC=C
imp=SimpleImputer(missing_values=np.nan,strategy='mean')
imp.fit(fC)
fC=imp.transform(fC)
fc=c
imp=SimpleImputer(missing_values=np.nan,strategy='median')
imp.fit(fc)
fc=imp.transform(fc)
fD=data[['a','c']]
imp=SimpleImputer(missing_values=np.nan,strategy='most_frequent')
imp.fit(fD)
fD=imp.transform(fD)
数据规范化
import numpy as np
data=np.load('data.npy')
data=data[:,1:]
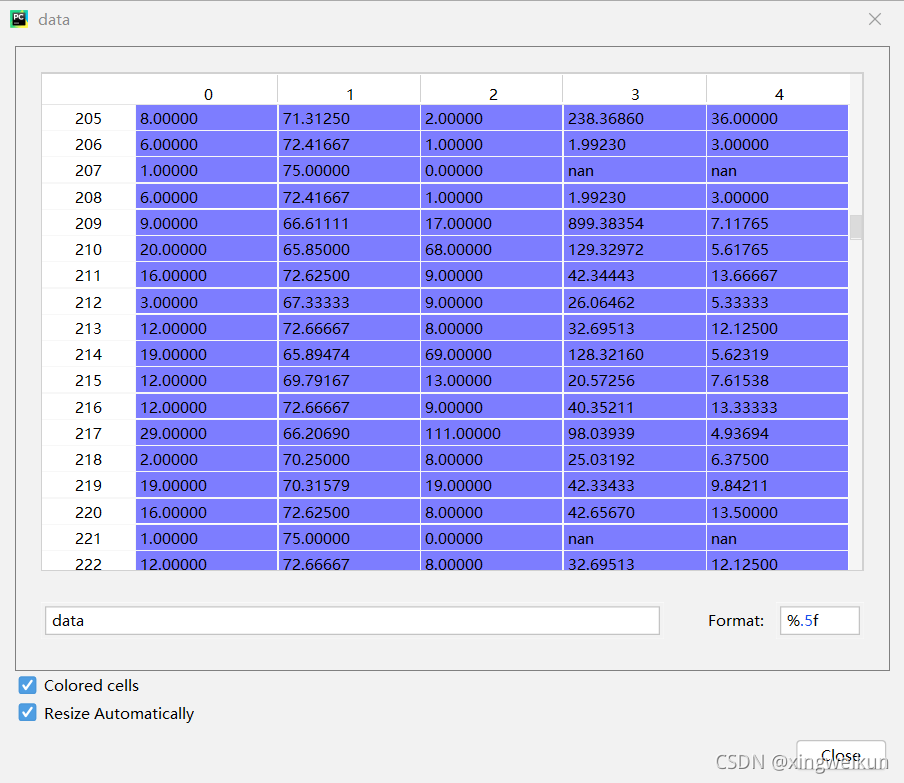
可以看出指标之间的数据差异比较大,需要做规范化处理
同时该数据存在空值,在进行规范化处理之前需要先对其进行填充处理
这里采用按列均值填充
from sklearn.impute import SimpleImputer
imp=SimpleImputer(missing_values=np.nan,strategy='mean')
imp.fit(data)
data=imp.transform(data)
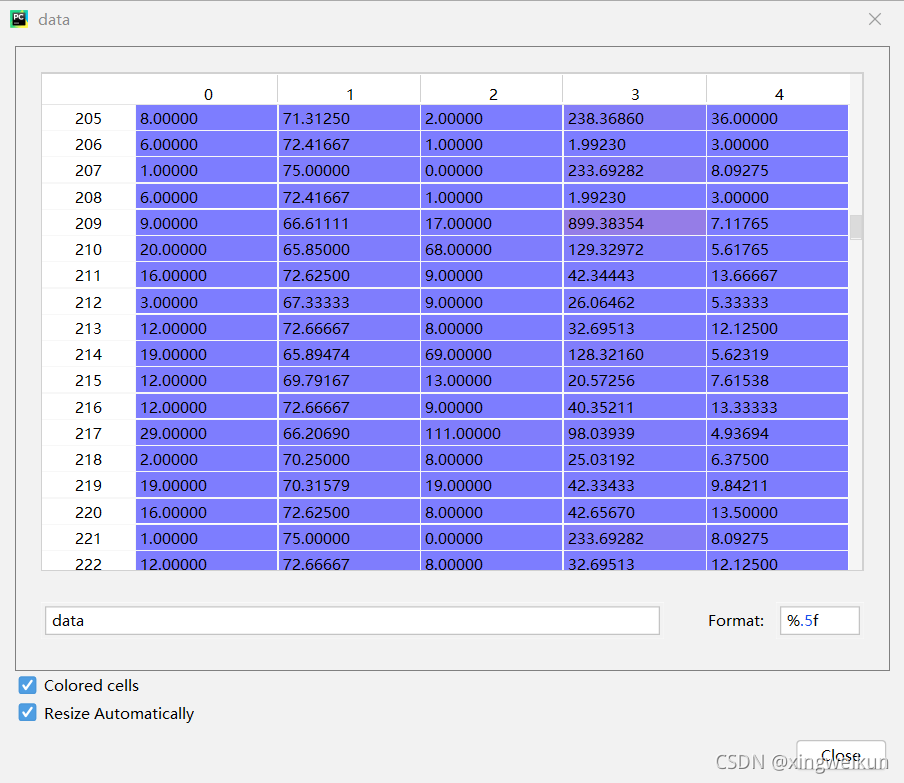
为了区分,定义x=data,x1=data
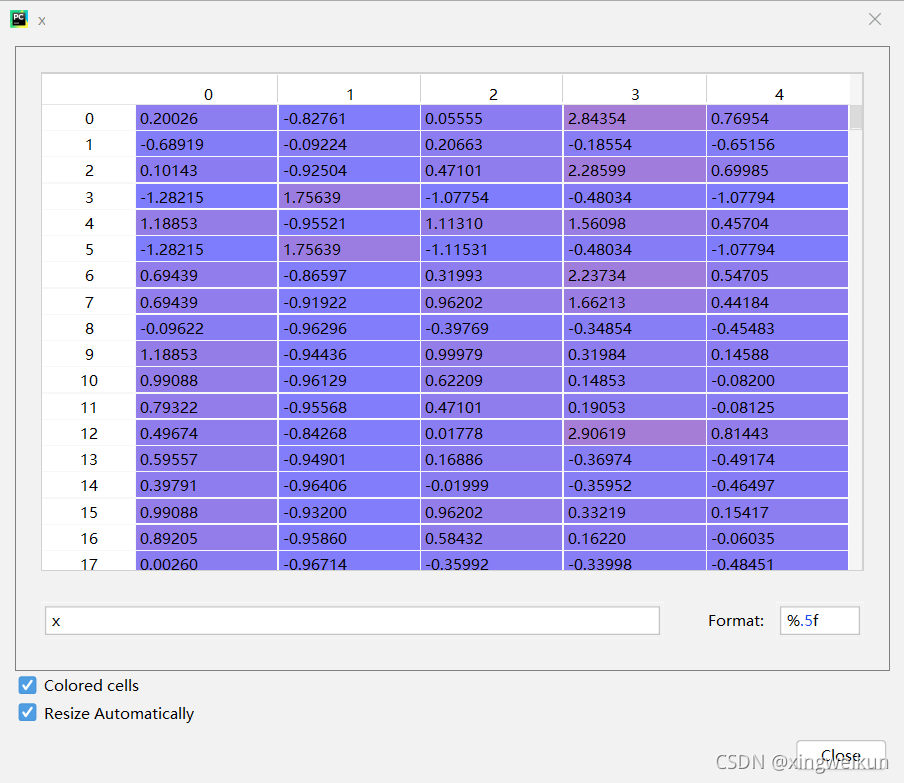
对x做均值-方差规范化处理
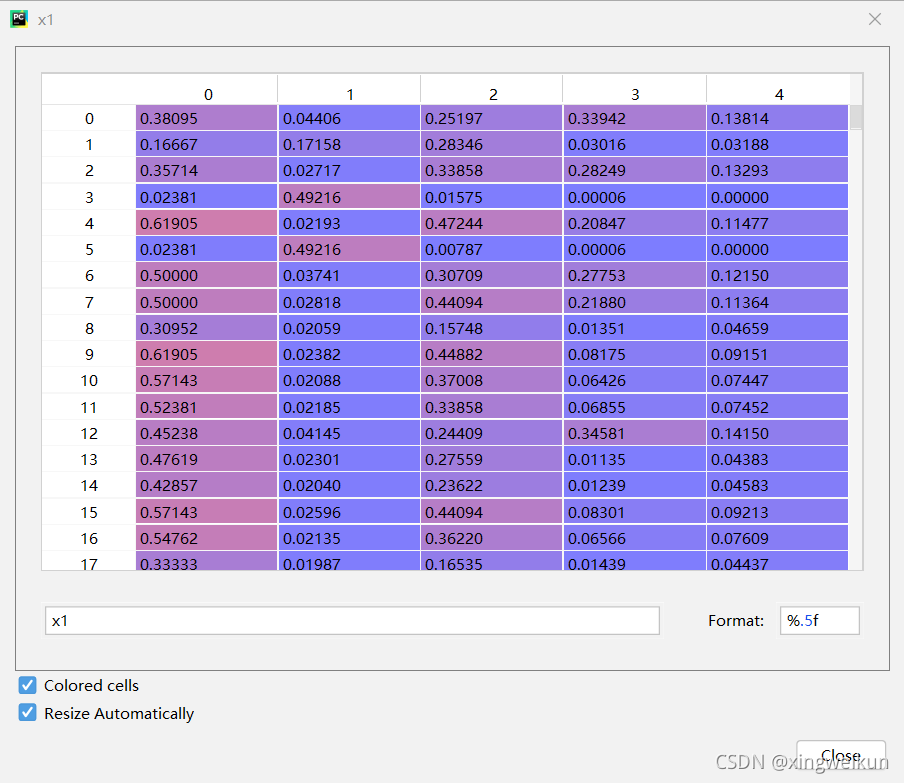
对x1做极差规范化处理
首先对x做均值-方差规范化处理
from sklearn.preprocessing import StandardScaler
x=data
scaler=StandardScaler()
scaler.fit(x)
x=scaler.transform(x)
对x1做极差规范化处理
from sklearn.preprocessing import MinMaxScaler
x1=data
min_max_scaler=MinMaxScaler()
min_max_scaler.fit(x1)
x1=min_max_scaler.transform(x1)
主成分分析
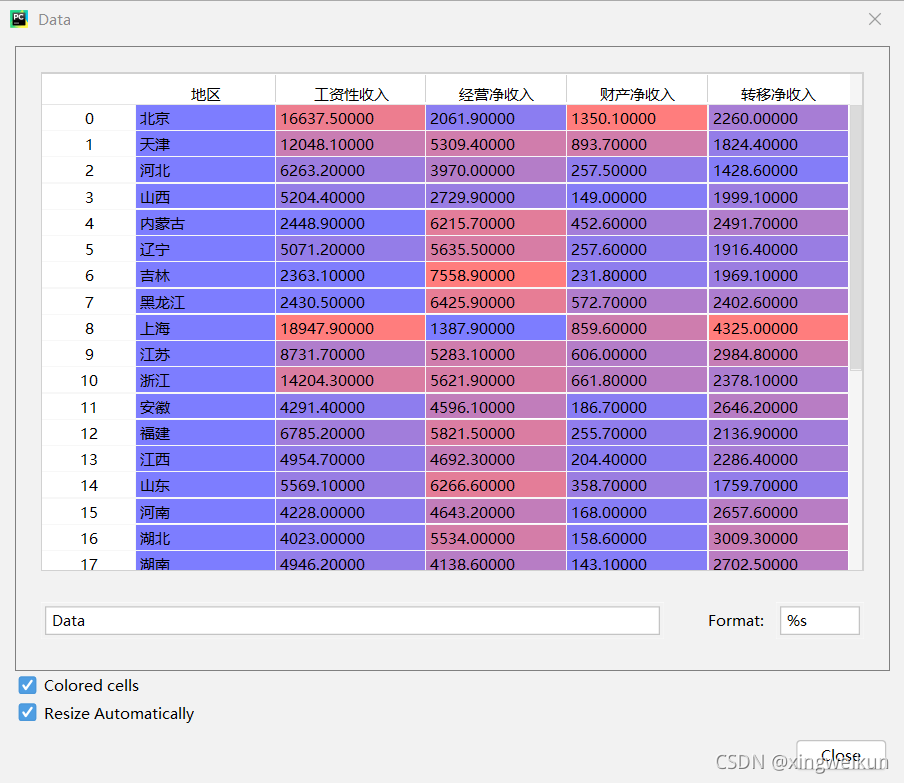
import pandas as pd
Data=pd.read_excel('农村居民人均可支配收入来源2016.xlsx')
X=Data.iloc[:,1:]
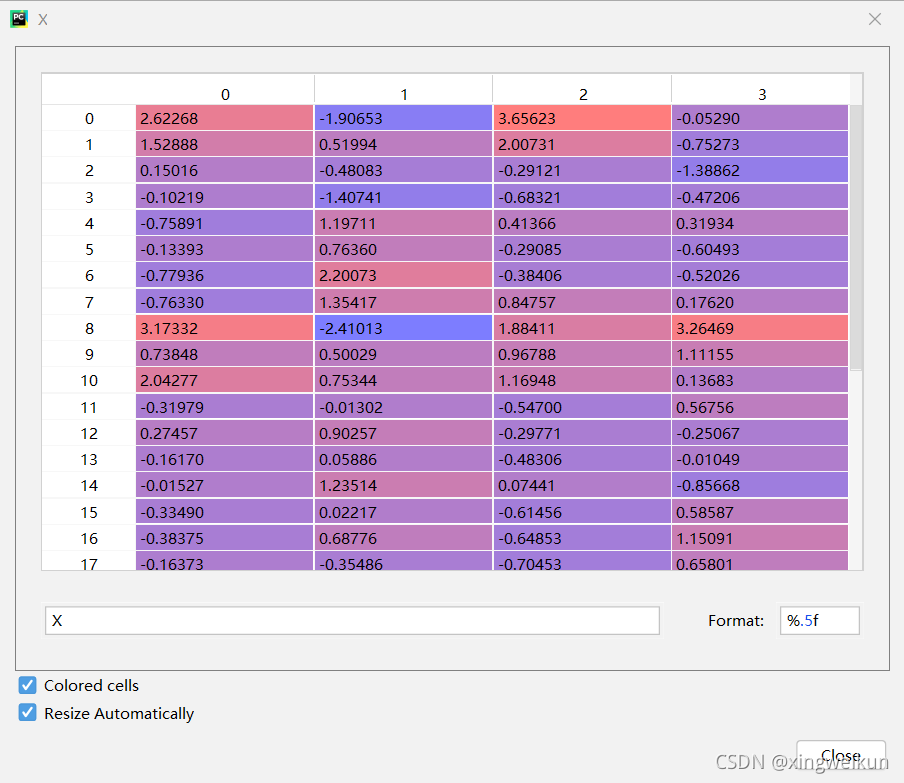
#数据规范化处理
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
scaler.fit(X)
X=scaler.transform(X)
#主成分分析
from sklearn.decomposition import PCA#导入主成分分析模块PCA
pca=PCA(n_components=0.95)#创建对象pca,设置累计贡献率为95%以上
pca.fit(X)#对待分析的数据进拟合训练
Y=pca.transform(X)#返回提取的主成分
tzxl=pca.components_#特征向量
tz=pca.explained_variance_#特征值
gxl=pca.explained_variance_ratio_#主成分方差百分比(贡献率)
#验证第一个主成分前面的4个分量的值
Y00=sum(X[0,:]*tzxl[0,:])
Y01=sum(X[1,:]*tzxl[0,:])
Y02=sum(X[2,:]*tzxl[0,:])
Y03=sum(X[3,:]*tzxl[0,:])
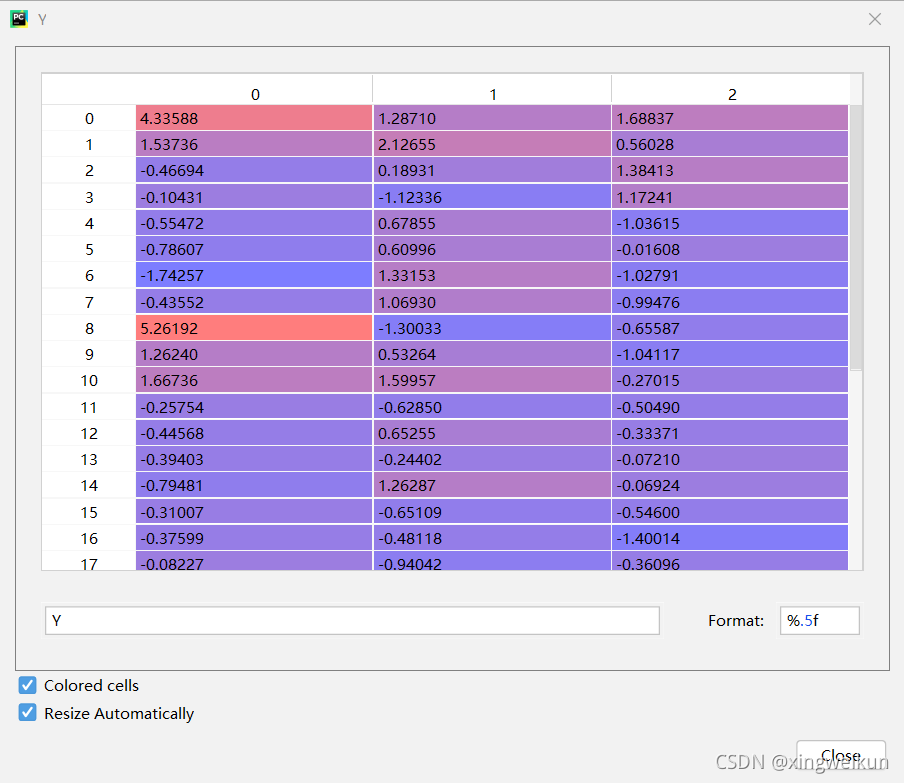


基于主成分进行综合排名.
定义综合排名指标为F
F计算公式
F=g1Y1+g2F2+…+gmFm
m表示提取的主成分个数,Fi和gi(i<=m)分别表示第i个主成分和其贡献率
F=gxl[0]*Y[:,0]+gxl[1]*Y[:,1]+gxl[2]*Y[:,2]#综合得分=各个主成分*贡献率之和
dq=list(Data['地区'].values)#提取地区
Rs=pd.Series(F,index=dq)#以地区作为index,综合得分为值,构建序列
Rs=Rs.sort_values(ascending=False)#按综合得分降序进行排序
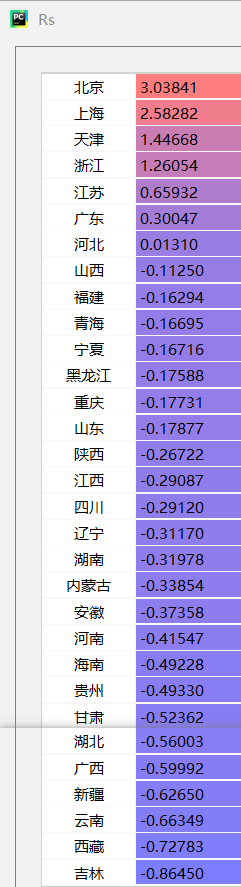
线性回归
在发电场中电力输出(PE)与AT(温度)、V(压力)、AP(湿度)、RH(压强)有关
求出PE与AT、V、AP、RH之间的线性回归关系式系数向量(包括常数项)和拟合优度(判定系数)
今有某次测试数据AT=28.4、V=50.6、AP=1011.9、RH=80.54,试利用构建的线性回归模型预测其PE值
读取数据,确定自变量x和因变量y
import pandas as pd
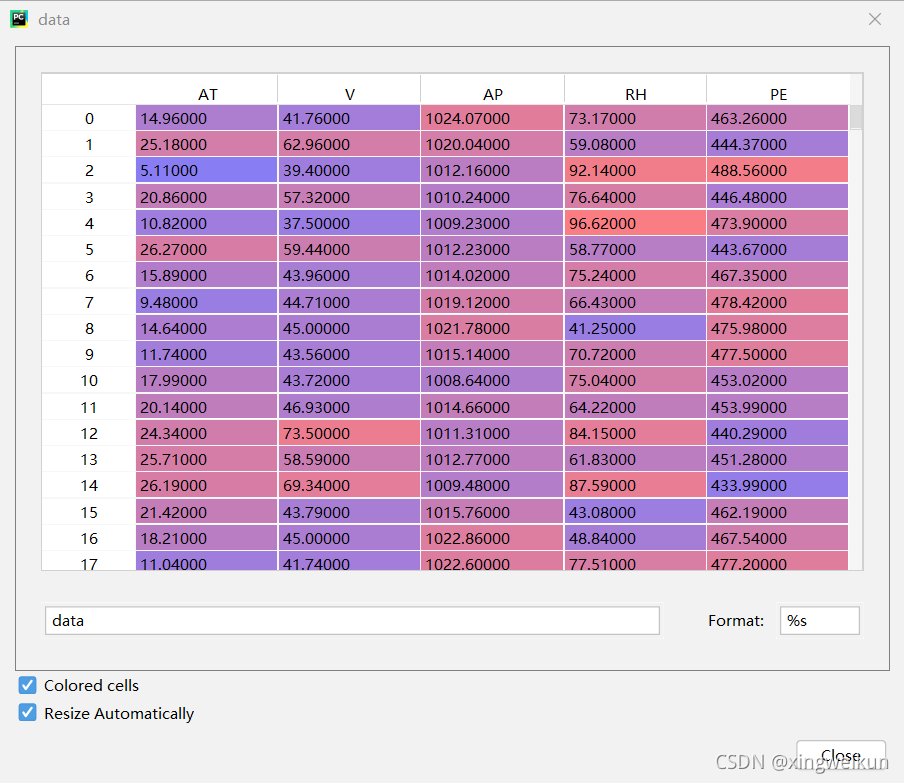
data=pd.read_excel('发电场数据.xlsx')
x=data.iloc[:,0:4].values
y=data.iloc[:,4].values
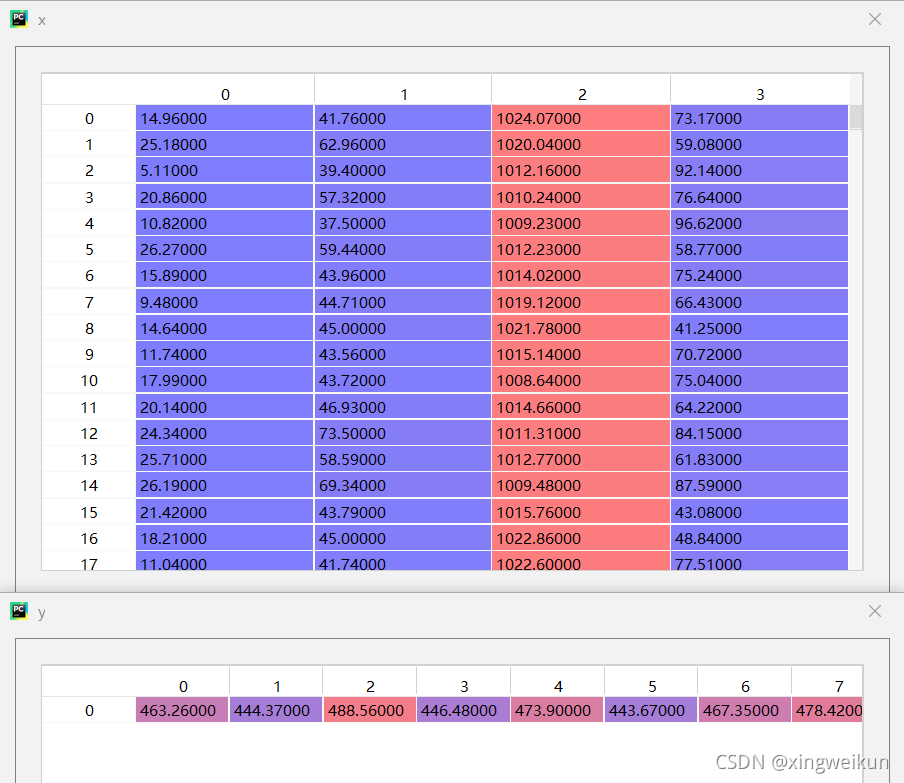
线性回归分析
#导入线性回归模块,简称为LR
from sklearn.linear_model import LinearRegression as LR
lr=LR()#利用LR创建线性回归对象lr
lr.fit(x,y)#对数据进行拟合训练
Slr=lr.score(x,y)#判定系数R^2
c_x=lr.coef_#x对应的回归系数
c_b=lr.intercept_#回归系数常数项

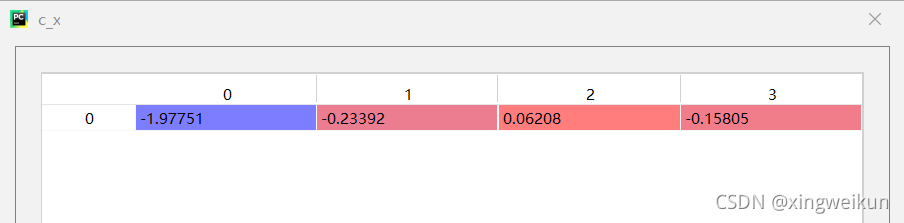
利用线性回归模型进行预测
(1)可以利用lr对象中的predict()方法进行预测
import numpy as np
x1=np.array([28.4,50.6,1011.9,80.54])
x1=x1.reshape(1,4)
R1=lr.predict(x1)
(2)也可以利用线性回归方程式进行预测
r1=x1*c_x
R2=r1.sum()+c_b
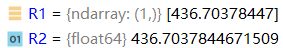
两种方法预测结果一致



















 2103
2103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











