






 本文介绍了Transformer的基本结构,包括编码器和解码器的工作原理,以及注意力机制中的QKV概念。通过视觉和人类注意力的类比,深入解读了Multi-Head Attention的原理。还讨论了Mask的作用,最后总结了学习过程和参考资源。
本文介绍了Transformer的基本结构,包括编码器和解码器的工作原理,以及注意力机制中的QKV概念。通过视觉和人类注意力的类比,深入解读了Multi-Head Attention的原理。还讨论了Mask的作用,最后总结了学习过程和参考资源。
CV之Transformer--笔记一--Transformer原理学习
写在开头
这篇blog是在参与datawhale组队活动期间根据自己所学而写的,在看完资料后,记录自己的理解,所以内容不一定正确,希望各位大佬能指出错误。
用自己的话描述Transformer的结构
先上一副经典结构图
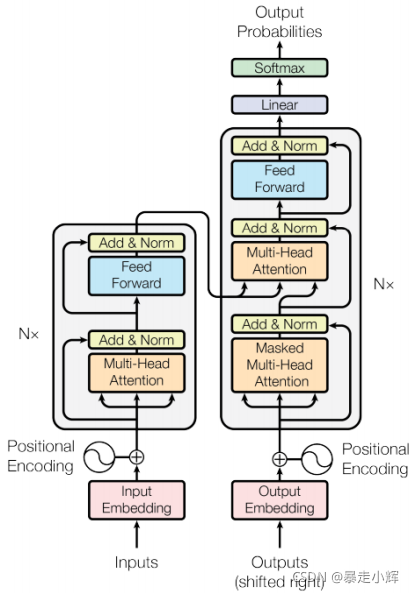
首先Transformer可以分为左右两边看,左边是一个编码器,右边是一个解码器。
编码器
我理解在vision中,inputs的是经过backbone卷积之后的矩阵,和位置编码结合后传入Multi-Head Attention 然后和输入做残差连接然后进行normalization。继续的传到前向传播网络(两个线性层+ReLU激活),然后和输入做残差连接然后进行normalization。对以上结构重复N遍,则完成编码器。
解码器
一开始的Output Embedding是一个初始符,相当于一个空的字符串,然后不断的将预测结果添加进embedding中,直至遇到停止符才停止。同样的Embedding会与位置编码结合后传入下一层。紧接的是Masked Multi-Head Attention然后与输入做残差连接然后进行normalization。剩下的和编码器那一部分类似,只不过输入是结合了编码器的输出。也是重复N次,再传进Linear层,最后结果softmax得到最终结果。
在结构图中的一些自己的观察
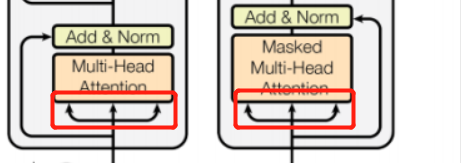
这里的三个分支,应该就是对应attention的Q、K、V
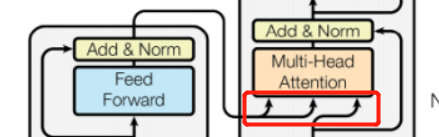
这里我理解是编码层的两个linear输出分别做Q和K,然后Masked attention模块的输出作为V
进一步的细节
关于attention的QKV究竟是啥
从人的视觉如何注意物体去思考:人的视觉观察问题是由主观的意愿和客观物体自带的特征相结合的结果。Q就是对应主观意义,自主性的选择;K就是对应客观物体的信息;而V就是在注意力的背景下,感官的输入。具体例子可参考李沐老师的《动手学深度学习》第二版,讲得很生动:https://zh-v2.d2l.ai/chapter_attention-mechanisms/attention-cues.html
从模型去思考:如下图所示(图源于极视平台的《搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了》,侵删)
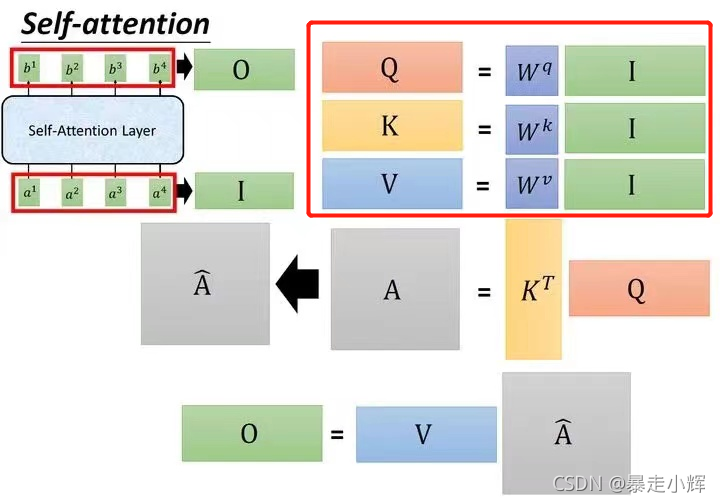
看右上角的红框,我理解QKV就是分别将input与一个可学习权重进行相乘所得到的,我们通过理论赋予QKV意义并在对应的地方使用他们。他们的W都是可学习的权重。
而Multi-Head Attention就是多个attention相结合,为的就是希望不同的attention能留意到特征中不同意义,更多元的进行特征提取。
关于Masked
根据datawhale的文档描述:Mask是为了屏蔽掉无效的padding和屏蔽掉来自“未来”的信息。
屏蔽掉来自“未来”的信息:因为attention会综合所有时间步的计算的,在解码的时候,就有可能获取到未来的信息。
总结
这次看Transformer看得挺认真的,这个最近太火了而且自己也感兴趣,感谢datawhale的开源,跟着文档的理论和代码一步步慢慢的啃,虽然仍有不懂,但真的比以前自己看清晰了很多。自己的代码部分还需要更多的时间去实践和理解。
参考
datawhale的动手学CV-Pytorch第六章:https://github.com/datawhalechina/dive-into-cv-pytorch
李沐老师的《动手学深度学习》第二版:https://zh-v2.d2l.ai/chapter_attention-mechanisms/attention-cues.html

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









