






 本文详细介绍了Pandas库的核心功能,包括数据结构Series和DataFrame的创建、操作与数据处理技巧。涵盖数据清洗、特征提取及统计分析方法,适合数据分析初学者和进阶者。
本文详细介绍了Pandas库的核心功能,包括数据结构Series和DataFrame的创建、操作与数据处理技巧。涵盖数据清洗、特征提取及统计分析方法,适合数据分析初学者和进阶者。
pandas 有三大作用:数据的引入 数据的特征提取 数据的清洗
pandas有两种数据结构,分别是Series和DataFrame
Series是一种类似于一维数组的对象,是由一组数据(各种numpy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象,并且它的索引值是可以重复的,在未指定索引值的情况下会默认使用(0,1,2,3…)作为索引值,可以自行指定索引值。
DataFrame是一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等)DataFrame既有行索引也有列索引,可以被看作是由Series组成的字典
Series
通过一维数组建立Series
通过数组创建Series的时候,如果没有为数据指定索引的话,会自动创建一个从0到n-1的整数索引
,当Series对象创建好后,可以通过index修改索引值
import numpy as np
import pandas as pd
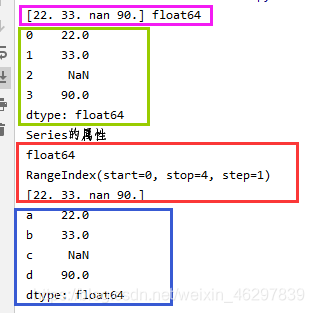
arr = np.array([22,33,np.nan,90])
print(arr,arr.dtype)
s1 = pd.Series(arr)
print(s1)
print('Series的属性')
print(s1.dtype)
print(s1.index)
print(s1.values)
s1.index=['a','b','c','d']
print(s1)
Series通过字典的方式创建
Series通过字典的方式创建时指定数据和索引,若不指定则使用key作为索引,value作为数据
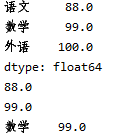
s2 = pd.Series(data = [88,99,100],index=['语文','数学','外语'])
print(s2)
print('------')
dict1 = {'语文':88,'数学':99,'外语':100}
s3 = pd.Series(dict1)
print(s3)

Series值获取方法
一:通过方括号+索引的方式获取对应索引的数据,可能返回多条数据
Series通过方括号+下标值/索引值+冒号来获取一段数据
二:通过方括号+下标值的方式获取数据
import numpy as np
import pandas as pd
dict1 = {'语文':88,'数学':99,'外语':100}
s1 = pd.Series(dict1,dtype=np.float)
print(s1)
print(s1['语文'])#通过key索引
print(s1[1])#通过下标索引
print(s1[1:2])
结果如下:
Series的运算
numpy中的数组运算,在Series中都保留了,都可以使用,并且Series在进行数组运算的时候
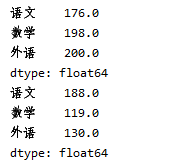
print(s1*2)
arr1 = np.array([100,20,30])
print(s1+arr1)
将Series中的nan值改为指定值
pandas中的isnull和notnull两个函数可以用于在Series中检测缺失值,这两个函数返回一个布尔类型的Series
s2 = pd.Series({'dfy':100,'zhang':88})
print(s2)
# s2.index = ['a','b']
s2 = pd.Series(s2,index=['dfy','zhang','c'])
print(s2)
print(pd.isnull(s2))#寻找无效值所在
print('------')
print(s2[pd.isnull(s2)])#打印出无效值 notnull则是寻找有效值
s2[pd.isnull(s2)]=-1
print(s2)#将无效值改为-1

自动对齐
当多个series对象之间进行运算的时候,如果不同series之间具有不同的索引值,那么运算会 自动对齐不同索引值的数据,如果某个series没有某个索引值,那么结果会赋值为NaN
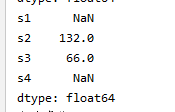
s4 = pd.Series(data=[22,33,44],index=['s1','s2','s3'])
s5 = pd.Series(data=[22,33,99],index=['s3','s4','s2'])
print(s4+s5)#数据会自动对齐,没有数据的就用无效值
DataFrame
通过二维数组方式建立
import pandas as pd
import numpy as np
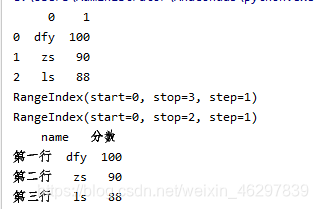
arr =[['dfy',100],['zs',90],['ls',88]]
df1 = pd.DataFrame(arr)#表格形式
print(df1)
print(df1.index)#行索引
print(df1.columns)#列索引
df1 = pd.DataFrame(arr,index=['第一行','第二行','第三行'],columns=['name','分数'])#修改索引
print(df1)
通过字典方式建立
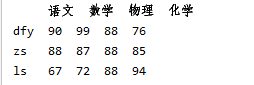
dict1 = {
'语文':[90,88,67],
'数学':[99,87,72],
'物理':88,
'化学':[76,85,94]
}
df2 = pd.DataFrame(dict1)#此刻会将字典的key值作为列索引
df2.index=['dfy','zs','ls']#若不加上行索引那么会默认用012
print(df2)
索引
DataFrame可以直接通过列索引获取指定列的数据,如果需要获取指定行的数据的话,需要通过ix方法来获取对应行索引的行数据
dict1 = {
'语文':[90,88,67],
'数学':[99,87,72],
'物理':88,
'化学':[76,85,94]
}
df2 = pd.DataFrame(dict1)#此刻会将字典的key值作为列索引
df2.index=['dfy','zs','ls']#若不加上行索引那么会默认用012
print(df2)
print(df2['语文'])#打印出所有的语文成绩,表格数据只能以列来取数据不能以行,比如这里就不能是用'dfy'来索引
print(df2['语文']['dfy'])#表格数据索引只能先列后行,不能先行后列
# 若要从行为索引开始取数据,则用ix来索引
print(df2.ix['dfy']['语文'])

添加新行新列
numpy不可以添加新行新列,但是DataFrame可以
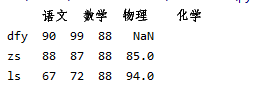
dict1 = {
'语文':[90,88,67],
'数学':[99,87,72],
'物理':88,
'化学':[76,85,94]
}
df2 = pd.DataFrame(dict1)
df2.index=['dfy','zs','ls']
df2['化学']['dfy']=np.nan
print(df2)
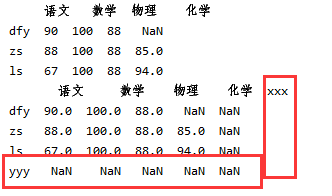
df2['数学']=100
print(df2)#改变一列
df2['xxx']=np.nan#新增列
df2.ix['yyy']=np.nan#新增行
print(df2)
pandas数据处理
1.使用pandas可以读取csv文件、excel文件以及json文件的数据
pd.read_csv()
pd.read_excel()
pd.read_json()
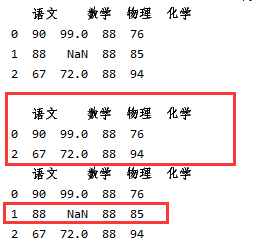
2.修改DataFrame中的数据以及将数据中有无效值的一行删除(使用dropna()),在dropna中添加参数(how=‘all’或者’any’),使用all时当有无效值的那行有其他有效值时就不会删除数据,当使用any时会将有无效值的那一行都删除。
dict1 = {
'语文':[90,88,67],
'数学':[99,87,72],
'物理':88,
'化学':[76,85,94]
}
df2 = pd.DataFrame(dict1)
# df2.ix[1]=np.nan
df2['数学'][1]=np.nan
print(df2)
print('------')
print(df2.dropna())#将有无效值的一行删除
print(df2.dropna(how='all'))#使用all不会将数据删去,当那一行都是无效值时会被删,但是用any的话一行都会被删
3 填充缺省值为指定值,使用fillna()
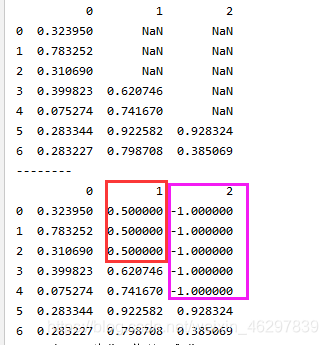
df3 = pd.DataFrame(np.random.random((7,3)))
print(df3)
df3.ix[:4,2]=np.nan
df3.ix[:2,1]=np.nan
print(df3)
print('--------')
# print(df3.fillna(0))#将所有缺省值填充为0
print(df3.fillna({1:0.5,2:-1}))#使得列索引为1的缺省值变成0.5,列索引为2的缺省值变成-1
pandas常用的数学方法
pandas常用的数学统计方法
count 计算非NA值的数量
describe 针对Series或DataFrame列计算统计
min/max/sum 计算最小值 最大值 总和
argmin argmax 计算能够获取到最小值和最大值的索引位置(整数)
idxmin idxmax 计算能够获取到最小值和最大值的索引值
quantile 计算样本的分位数(0到1)
mean 值的平均数
median 值的中位数
mad 根据平均值计算平均绝对距离差
var 样本数值的方差
std 样本值的标准差
cumsum 样本值的累计和
cummin cummax 样本的累计最小值 最大值
cumprod 样本值的累计积
pct_change 计算百分数变化
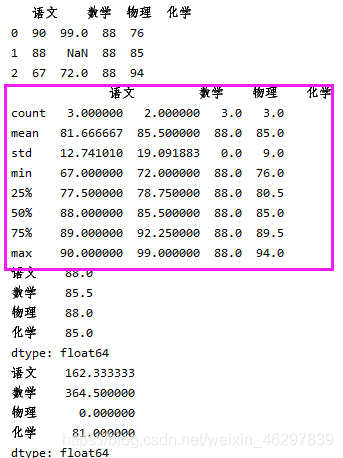
print(df2.describe())
print(df2.quantile())
相关系数 print(df2.corr())
协方差 print(df2.cov())
print(df2)
print(df2.describe())
print(df2.median())
print(df2.var())
print(df2.std())
print(df2.corr())#相关系数
print(df2.cov())#协方差 相关程度
unique方法用于获取Series或DataFrame某列中的唯一值数组(去重数据后的数组)
value_counts方法用于计算一个Series或DataFrame某列中各值的出现频率
isin方法用于判断矢量化集合的成员资格,是否在里面,可用于选取Series中或DataFrame列中数据的子集
print('-------')
s1 = pd.Series(['a','b','c','b','a'])
print(s1.unique())
print(s1.value_counts())#计算出每个值出现的次数
print(s1.value_counts()['a'])#计算其中的某个值出现的次数
print(s1.isin(['a','b']))#判断元素是否在列表
pandas的层次索引与取值的新方法
iloc 对下标值进行操作 Series与DataFrame都可以操作
loc 对索引值进行操作 Series与DataFrame都可以操作
import pandas as pd
s1 = pd.Series(data=[99,87,76,67,99],
index=[['2017','2017','2018','2018','2018'],['dfy','lsi','dfy','lsi','ami']])
#数据透视表 用到层次索引
print(s1)
print(s1.iloc[1])
print(s1.loc['2017','lsi'])
df1 = pd.DataFrame({
'year':[2016,2016,2017,2017,2018],
'fruit':['apple','banana','apple','banana','apple'],
'production':[2345,3242,5667,2576,2134],
'profits':[23.22,76.89,90.99,78.22,98.76]
})#iloc 对下标值进行操作
print(df1.iloc[2,2])
#loc 对索引值进行操作 先对行进行索引 也可以使用ix索引
print(df1.loc[2,'production'])
pandas:按照层次索引进行统计数据
df1 = pd.DataFrame({
'year':[2016,2016,2017,2017,2018],
'fruit':['apple','banana','apple','banana','apple'],
'production':[2345,3242,5667,2576,2134],
'profits':[23.22,76.89,90.99,78.22,98.76]
})
print(df1)
print('-------')
df2 = df1.set_index(['year','fruit'])#此时就会按照所规定的的索引值去归一数据
print(df2)
print(df2.index)
df1.index=['a','b','c','d','e']#自定义索引
print(df1)
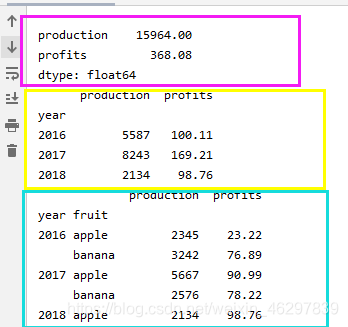
print('--------')
print(df2.sum())#按照行索引相加
print(df2.sum(level='year'))#按照year这个级别求和
print(df2.sum(level=['year','fruit']))#按照两个级别求和,比如此处就是按照某年的哪种水果的所有产量加起来


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









