







Correlation Congruence for Knowledge Distillation
Abstract
作者提出了一个新的框架,称为知识提取相关同余(CCKD),它不仅传递实例级信息,而且传递实例之间的相关性。
Introdution
CCKD的唯一要求是教师和学生的维度应该相同。为了解决教师网络和学生网络特征表示不匹配的问题,我们对教师网络和学生网络都采用了一个维度相同的全连接层。
主要贡献:
- 我们提出了一种新的提取框架&相关同余知识提取(CCKD),它不仅关注实例同余,而且关注相关同余。
- 我们介绍了一种通用的基于内核的方法来更好地捕获小批量中实例之间的相关性。我们评估和分析了不同相关性指标对不同任务的影响。
- 我们探索了小批量训练的不同采样器策略,以进一步提高相关知识转移
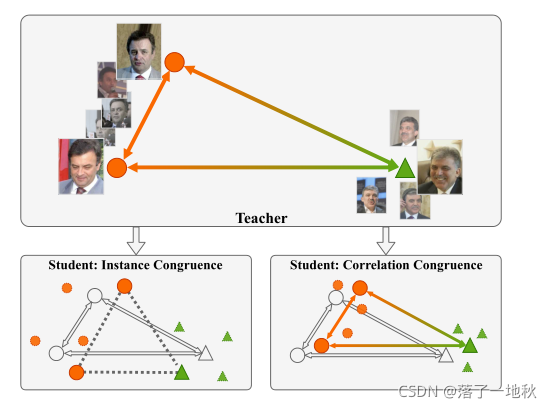

图1:实例一致性和相关性一致性之间的差异。当只关注实例一致性时,学生实例之间的相关性可能与教师实例之间的相关性大不相同,班内的凝聚力会更差。CCKD通过在传递知识时添加相关同余来解决该问题
2.Related Work
本文在实例知识的基础上,将嵌入空间中实例之间的相关性作为有价值的知识,将嵌入空间中实例之间的相关性传递给实例之间,进行知识提炼。
3.CCKD
3.1 3.1. Background and Notations

Wt , Ws : teacher and student 的网络参数
X , Y : 代表输入的数据集和对应的 gt 真值
Ф : 代表网络映射函数
fs,ft :代表老师和学生的特征表示
zt,zs : 全连接层输出
pt,ps:经过softmax的预测值
3.2. Knowledge Distillation

不管最终预测[15]、特征表示[30]或隐藏层激活[25]的一致性约束如何,这些方法只关注实例一致性,而忽略实例之间的相关性。由于教师和学生之间的能力差距,对于一个轻量级的学生来说,很难通过实例级信息从一个重量级的教师那里学习相同的映射函数。
简单来说:传统的kd只是说在实例级的信息kd。
3.3. Correlation Congruence
考虑了实例级的信息,同时考虑到实例间的信息。

Fs,Ft : 特征表示集(特征矩阵的集合)

Ψ : 映射函数 (C是 nxn 的关系矩阵。)

Cij 特征图 i 和 j 的关系 Cij

φ : 度量关系的函数。

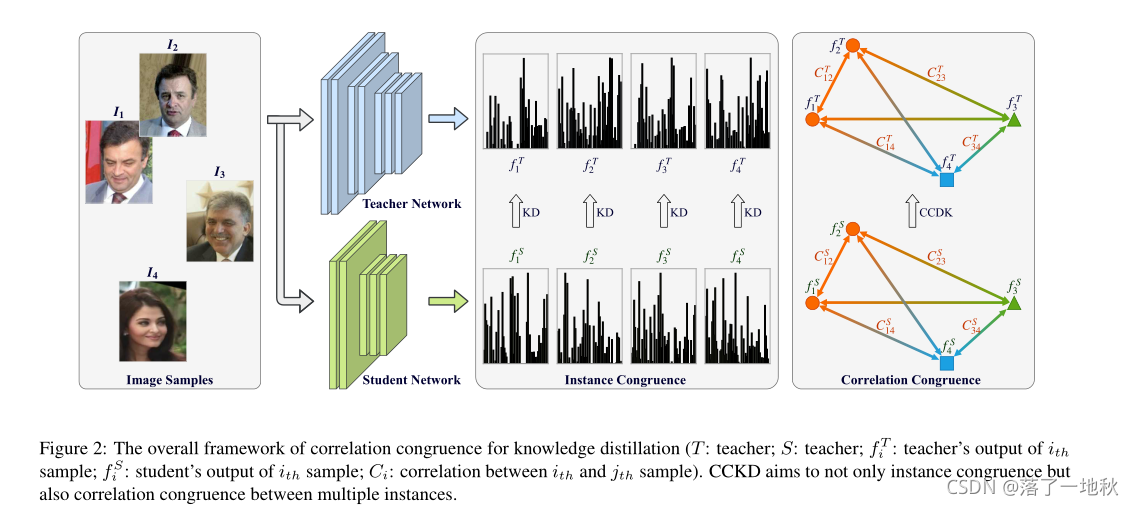
3.4. Generalized kernel-based correlation
由于嵌入空间(一律代表着特征空间)的维数非常高,因此捕获实例之间的复杂相关性并不容易[31]。在本节中,我们将介绍内核技巧,以捕获特征空间中实例之间的高阶相关性。让x,y∈ Ω 表示特征空间中的两个实例,我们引入不同的映射函数k:Ω×Ω → R 作为相关度量,包括:
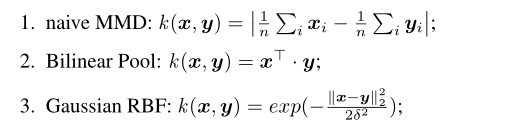
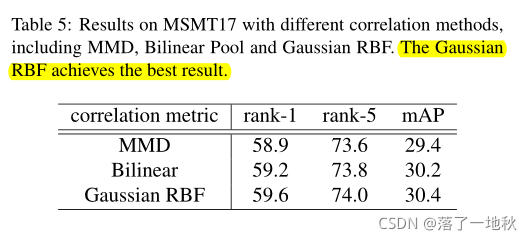
MMD可以反映平均嵌入之间的距离。双线性池[22]可以看作是一个简单的二阶函数,其中两个实例之间的相关性由元素点积计算。高斯径向基函数(Gaussian-RBF)是一种常用的核函数,其值仅取决于与原点空间的欧氏距离。

与朴素的MMD和双线性池相比,高斯RBF在捕捉实例之间复杂的非线性关系方面更加灵活和强大。基于高斯径向基函数,相关映射函数φ可由核函数 K:F×F ∈ Rn×n计算,其中每个元素可计算为:
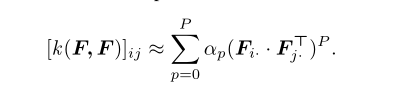

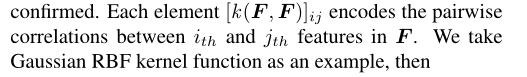
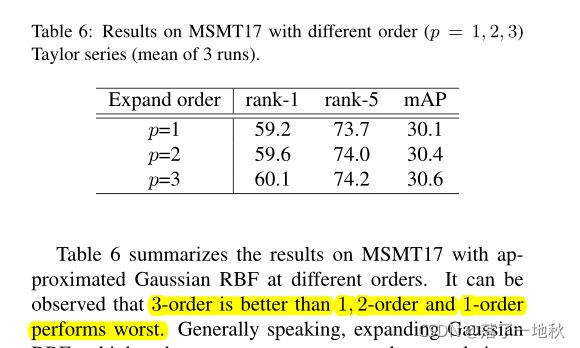
可以用P阶泰勒级数来近似。一旦指定了核函数,那么系数 αp 也得到了确认。每个元素[k(F,F)]ij 将第i个实例 ith 和 第 j个 实例 j th 特 征之间的成对相关性编码为F。以高斯径向基函数核函数为例,对其进行了分析
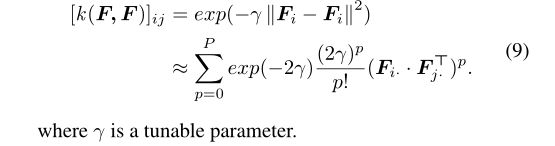
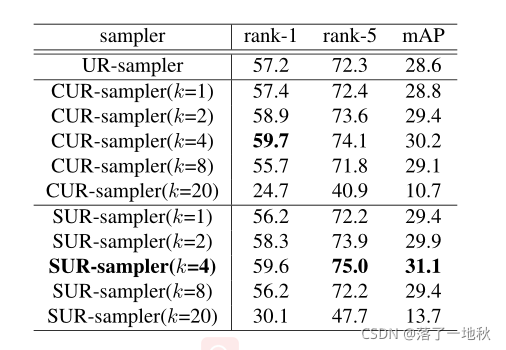
3.5. Strategy for Mini-batch Sampler
由于实例之间的相关性是在一个小批量中计算的,因此适当的采样器对于平衡类内和类间相关性的一致性非常重要。一个简单的策略是统一随机取样器(UR取样器),这将导致这样一种情况,即当类数较大时,所有示例都来自不同的类。虽然它是实例同余的真值梯度的无偏估计,但UR采样器会导致类内相关梯度的高偏估计。为了平衡类内和类间的相关性一致性,我们提出了两种小批量采样器策略:
class-uniform random sampler (CUR-sampler) and superclass-uniorm random sampler (SUR-sampler).
类均匀随机采样器(CUR采样器)和超类单形随机采样器(SUR采样器)
具体采样策略
CURsampler按类采样,并为每个采样类随机选择固定k个示例(每个批次由6个类别组成,每个类别包含k=8个示例,形成48个批次大小)。SUR-sampler与CUR-sampler类似,但不同之处在于它通过超类对示例进行采样,超类是通过聚类生成的真实类的一种更软的形式。为了得到训练示例的超类,我们首先使用教师模型提取特征,然后使用K-means聚类。示例的超类被定义为它所属的集群。与CUR-sampler相比,SUR-sampler由于超类反映了嵌入空间中实例的错乱结构,因此对于不平衡标签具有更大的灵活性和容错性。
3.6. Complexity analysis and implementation details
为了解决教师和学生之间维度不匹配的问题,在教师和学生网络中都增加了一个固定长度维度的全连接层,这对本文中的其他方法影响不大。
4. Experiments(具体一些细节看论文,比如参数的设定,网络的选择)
本工作选择了ResNet[12]和MobileNet[26]网络。
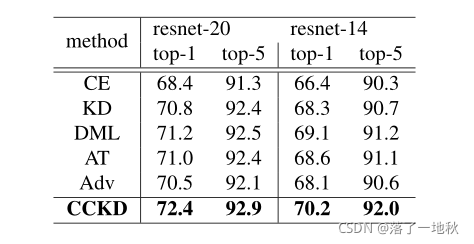
4.2. Classification Results on CIFAR-100
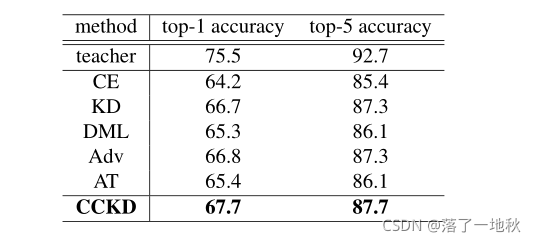
Results on ImageNet-1K
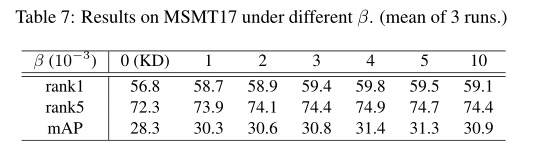
4.4. Person Re-Identification on MSMT17
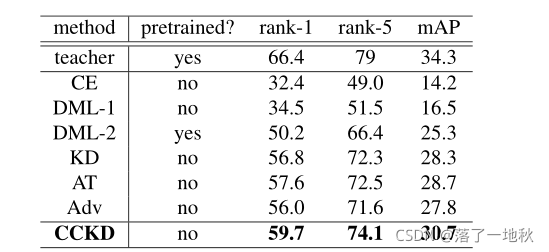
4.5. Face recognition results on Megaface
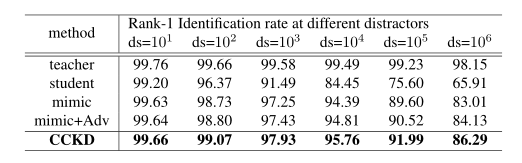
4.6. Ablation Studies

















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









