



x64汇编
-
所有指令,带q的是8个字节(64位),带l的是4个字节(32位), 32位的寄存器全是eax, ebx等,64位的寄存器全是rax,rbx等
为了方便,以下所有命令没有加l或者q,看的时候自行脑补即可
-
mov a, b,是从a移动到b, 注意:如果不带括号,则是直接改变寄存器的值,比如mov $rsp, $rbp,直接把寄存器值改了,如果是mov $1, ($rbp),则改变的是rbp指针指向的内容,相当于多了一次解引用
-
push, pop 改变的就是当前堆栈,相当于:push x 相当于:mov x, ($rsp), sub $rsp(假设x占用1个字节)(堆栈是从高地址向低地址"增加",所以是sub) (这两条顺序可能是反的
-
call x :首先把当前指令的下一条指令压栈,然后跳转到x地址继续执行:相当于:push 4($rip), jmp x, 而rbp指针不动,现象就是跳转前rbp指针指向的是要执行的下一条地址,而8中是说开辟新栈帧时,首先把上一个栈帧的rbp入栈,所以整体看起来,上一个栈帧最后一个地址(最小的地址)保存的是回到这个栈帧时要执行的下一条地址,而当前栈帧的第一个地址(最上面的地址)保存的是上一个栈帧的rbp,所以leave用于恢复rbp和rsp,ret用于跳转
-
leave指令:用于恢复rbp和rsp指针,相当于以下两条命令:mov $rbp, $rsp; pop $rbp, 第一条执行前,rbp指向当前栈帧的基地址(内容保存的是上一个栈帧的rbp),rsp指向当前栈帧的顶部地址,可以认为地址空间是竖条形,并且地址上高下低,是从上向下不断增长,此时rsp是小于rbp的,两者之间的距离即为当前栈帧的空间,第一条执行后,把rsp拉了上来,和rbp都指向了上一个栈帧的rbp,第二条相当于两条:把rbp指向的内容赋给了rbp指针,并且rsp指针向上移动4个(32位)或 8个(64位)字节,相当于:rbp向上拉到了上一个栈帧的起始地址,rsp向上移动了一位到了本栈帧要执行的下一条指令的地址,然后会跟ret指令:这一条指令是从下一条指令的地址继续执行,并且rsp继续上移一位
-
jnz/jne, je/jz注意,e完全等于z,这两个主要是判断一个ZF标志位,zero flag,如果结果为0,则这个标志位是1这两个指令一般和cmp s1, s2或 test s1, s1配合使用:cmp s1, s2, 等于 s1 -s2,如果s1 = s2, 则结果是0,则zf等于1,那么je就会跳转,所以这个je相当于:if (s1 == s2) {jmp xxx)
-
test s1, s1 等于s1 & s1, 如果 s1 是0,则结果是0, zf等与1, 那么je也会跳转,所以je/jz也就是jump if equal or zero
-
对于一些通用寄存的保存和恢复,有两种方式:调用者保存(caller save)和被调用者保存(callee save),看汇编代码时,如果调用前保存了某个寄存器值,调用后恢复了这个值,那可能就是caller save, x86_64中,只有rbx, rbp, r12~r15 是callee save,其余均是caller save.
-
寄存器的常见用途:rax用于保存返回值,ebp帧指针,esp栈顶指针,保存函数传递中前6个参数,依次是:rdi, rsi, rdx, rcx, r8, r9,超过6个的,才会用堆栈传参
-
每个子函数调用开始时,都会有的两条命令:push $rbp; mov $rsp, $rbp,这两条命令调用之前,rbp指向当前栈帧的基地址,rsp指向栈顶,rsp在rbp的下面,距离是当前栈帧的长度,第一条执行后,当前栈帧的基地址被保存到了rsp,并且rsp继续下移,此时就开辟了个新的栈帧,第二条是令rbp等于当前rsp,此时彻底忘记了上一个的rbp
-
栈帧的开辟空间和寻址方式:经过了指令8后,rsp和rbp是相同的,此时一般会有个开辟空间的指令:sub $N, $rsp, 把rsp向下移动了N,也就是开辟了空间,然后再寻址的时候,往往不用push或者pop,而是用mov a, -N($rbp),这种方式,也就是从rbp地址向下找,这是一种更常用的栈帧内部寻址方式,注意:有的时候并不开辟空间,而直接就用了mov a, -N($rbp)这种方式寻址,此时rsp是等于rbp的,但是寻到的地址(-N($rbp))是小于rsp的!!个人理解这种方式是考虑到整个栈的空间是足够用的,而频繁用push和pop,多了一条rsp自增自减的命令,效率变低,所以就直接这样做了,只要能保证退出栈的时候寄存器值都是对的,应该也没啥问题
-
如果开启了编译优化O2, 则rbp不一定是帧指针!!
如图:9中所说的rsp可能大于寻到的地址,这种有可能是本子函数不再调用其他子函数时才会有,否则调用的时候由于先要把下一条地址压栈,所以要保证esp指向的一定要是当前栈顶。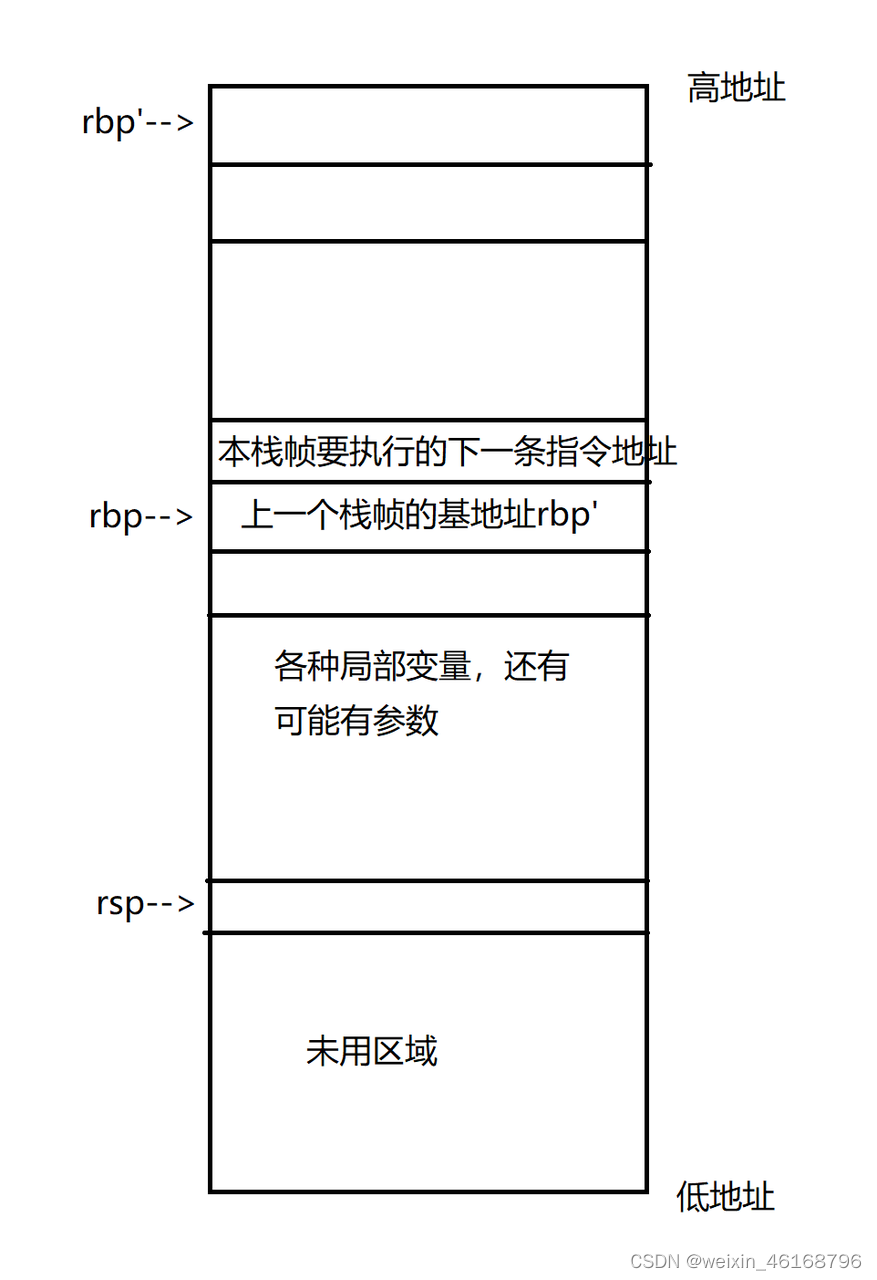
x86和x64汇编的区别
如果是32位汇编: mov a, b是从b 移动到a !!!
但是如果是 movq a, b是从a移动到b !!!!
Call x指令,等于push eip; jump x, 隐含着把eip指针压栈的操作
leave指令,等于mov esp, ebp; pop ebp, 注意,这里用的是32位的汇编,也就是把ebp移动到esp !!!
ret指令,等于pop eip,把之前保存的eip弹出来,所以leave 和ret往往是连在一起用的
但是,如果call了某一个函数,刚开始的汇编代码往往是有: push ebp; mov ebp, esp,可见没有和leave对应的"enter"指令,
注意,以上所有的push或者pop,都隐含着有一次esp指针的减少或者增加(堆栈向低地址增加)push是esp减少,pop是esp增加
win的x64汇编和mac的x64汇编区别
win的有一个和mac很大的区别,就是mov等指令的顺序都是和mac反的!!!比如mov a,b,在win上是从b到a !!!
但是在unix上是从a到b!!!
还有一点:在x86上,函数调用的参数一般是按顺序压到堆栈里面,所以有了__cdel和__stdcall两种顺序,但是在x64中,直接忽略掉这个参数,前几个参数都是用寄存器传递,后面才使用压栈。也就是fastcall的方式:
注意:win和mac上,传递参数的寄存器不同!!!win是rcx, rdx, r8, r9,只有前4个用寄存器传递,后面的压栈,而mac上是rdi, rsi, rdx, rcx,r8, r9。可见二者有两个区别:1.mac多了rdi, rsi,从第3个开始,才和win用相同的寄存器,2.即使相同,win是先rcx,再rdx,而mac是先rdx,再rcx !!!
除此之外,寄存器还有caller save和callee save之分,前者也称volatile,后者nonvolatile,如何理解呢?
比如在win-x64上,ecx是易变的,也就是说被调用的函数可以随意更改这种寄存器的值,那么如果下面的代码
更改 ecx;
Call fun;
访问ecx,
这里fun是可以随意更改ecx的值的,那么如果在调用完fun后,主函数还想读取call之前的ecx的值,那就必须在call之前把ecx保存起来,在call之后再恢复,这也就是所谓的caller save:
总结:逻辑关系是:由于某个寄存器是易变的,所以调用的某个函数可以随意更改该值,所以对于主函数,如果想访问调用前正确的该寄存器值,那必须要保存--call--恢复,也就是必须caller save,而反观被调用的函数,由于该寄存器是易变的,所以自己可以随意在被调用的子函数体中更改该值,而不需要做保存和恢复。
注意:这里某个寄存器需要做caller save的前提是:调用者需要访问call之前的值时才需要,而像eax这种保存返回值的寄存器,由于调用方就是要知道call完之后eax的值,所以这种就不需要做caller save了,所以说,所谓的caller/callee save都只是结果,而不是原因。
而callee save,也就是非易变的,比如rsi,这种寄存器调用者是默认call完之后,rsi还是call之前的值,不需要保存,而如果被调用的函数不需要改这种值,则也不需要去save,如果被调用函数需要改这个rsi,则必须在函数体开始Push, 函数结束的时候pop,也就是所谓callee save。
总结一下win和mac x64 汇编的区别:
| win-x64 | unix-x64 | |
| 指令的移动顺序mov a,b(所有两个操作数的指令都是这个顺序) | 从b到a | 从a到b |
| 传递参数的寄存器 | rcx, rdx, r8, r9 | rdi, rsi, rdx, rcx,r8, r9 |
| 易变的(需要caller save) | RAX, RCX, RDX, R8, R9, R10, R11, and XMM0-XMM5 | %rax, %rcx, %rdx, %rdi, %rsi, %rsp, and %r8-r11 |
| 非易变的(需要callee save) | RBX, RBP, RDI, RSI, RSP, R12, R13, R14, R15, and XMM6-XMM15 | %rbx, %rbp, and %r12-r15 |
| rax用途 | 函数的返回值 | |
| rip | 下一条指令的地址 | |
| rsp | 栈顶指针 | |
windbg调试进阶
-
如果有dll 和pdb,本地有代码,但是dll和pdb不是本地的代码编译出来的,但是本地的代码和编译dll/pdb的代码内容完全一致,那能不能直接用sln打开代码后attach调试呢?可以,说明当代码是完全一样时,vs不知道dll/pdb是来自哪个代码文件。
-
windbg中,用kbn可以显示frame的编号,注意是16进制的!!所以.frame 后面跟的其实是个16进制的数
-
dt -b this可以结构化打印this的内容
-
用windbg可以加断点后,执行一些命令,然后再继续执行,比如:bp HIDDeviceImpl::WriteDataToDevice+0x375 ".printf \"WaitFor\";dd (ebp-0x4c) L256;g"
解释:注意windbg暂时没有找到直接加行号断点的命令,只测试一下用函数名+偏移量可以加,这里的偏移量是通过先用vs attach,然后转到反汇编,找到的, .printf中需要再加个\,因为外边已经有双引号了。注意dd 后面可以直接跟寄存器,这里用ebp - 0x4c是因为查看汇编代码,这个地址刚好是需要查看的变量的地址,所以在这里查看变量的值,一个取巧的办法不是hard code变量的地址(这样需要先看出来变量的地址),而是借助寄存器+汇编代码,查看该变量在这一行汇编的时候刚好在哪个寄存器里面,然后在这里用这种方法打印该变量。
-
跳转指令jne的机器码是 0F 85 xx xx xx xx,其中4个xx是4个字节,= 跳转的目标地址 - 当前jne的地址 - 6(jne指令本身的长度),所以可以在dll中直接搜索这个hex,然后改这后面4个xx,就可以改跳转的地址。
lldb进阶
lldb的命令分为以下几大类:process, image, target, frame, thread, register, memory(或x), disassemble等,所有的命令都是以上几个命令价格空格再跟个subcommand(可能还有subsubcommnad),所以如果记不得命令具体是啥了,可以用help image查看这个命令后面可以跟哪些sub命令
-
所有的命令(sub命令)都可以有简写,比如target简写成ta,是取到第几个字母取决于有没有重名的命令,所以可以先输入1到2个字母试试,如果提示有重名,再多输一个字母
-
process save-core xxx.dmp命令可以将当前进程转储成dmp,所以如果要转储任意一个进程,可以先lldb attach,再用save-core
-
target variable可以打印当前文件中全局变量和局部静态变量,注意和frame variable一样,可以加个-L 打印地址
-
disassemble可以汇编某个地址,通常和image lookup --address联合使用,先查询某个指令所在的函数,再用disassemble --start-address 0x1eb8 --count 20 可以反汇编整个函数
-
image lookup --address后面可以跟数据的地址或code的地址,如果是数据地址,可以显示在哪个数据段,如果是code,可以显示所在的函数及偏移量
-
image dump sections 可以打印当前进程所有段信息的起始和终止地址

















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









