









GMTracker重读经典站在师兄师姐的肩膀上—Learnable Graph Matching: Incorporating Graph Partitioning with Deep Feature Learning for Multiple Object Tracking
Learnable Graph Matching: Incorporating Graph Partitioning with Deep
Feature Learning for Multiple Object Tracking
可学习的图匹配:将图分区与深度特征学习相结合以进行多对象跟踪。
发布在:cvpr 2022
环境配置与代码参考之前自己在刚开学的时候写过的GmTracker环境配置(当时和师兄第一次见面师兄晚上忙到11点帮忙改好的环境)对毕业的师兄表示感谢
虽然自己之前也在刚开学的时候汇报过GMTracker这一篇论文在组会的时候,当时主要是结合的讲解的代码,论文中的公式呀原理什么的其实真的是没有看明白。
上一个阶段自己完成了点跟踪常用的一些框架的学习,于是到了第二个阶段想办法完成点到实例的一个匹配,于是兜兜转转有回到了师兄师姐当时的起点,图匹配
我感觉开学这么久总是在读论文,继续读论文,虽然建立了体系,但是却缺失了回顾的过程。借着导师发我师兄论文的机会,也拜读完了师姐的论文和师兄师姐推荐的图匹配的两篇经典论文。
我借着这一个很好的机会重新学习一下GMTracker,这次应该会读的更加的明白,也可以懂得师兄师姐的创新点究竟在哪?
我将这一篇文章作为第四个图匹配论文的经典系列,站在师兄师姐的肩膀上学习这一篇论文。
摘要概览
-
跨帧数据关联是多目标跟踪(MOT)任务的核心。
-
作者发现了存在的两个主要的核心问题包括了
-
现有方法大多忽略轨迹和帧内检测之间的上下文信息,这使得跟踪器难以在严重遮挡等具有挑战性的情况下生存。
-
端到端关联方法仅依赖于深度神经网络的数据拟合能力,而几乎没有利用基于优化的分配方法的优势。
-
基于图的优化方法大多利用单独的神经网络来提取特征,这带来了训练和推理之间的不一致。
-
提出了一种新颖的可学习图匹配方法来解决这些问题。将轨迹和帧内检测之间的关系建模为通用无向图。
-
那么关联问题就变成了轨迹图和检测图之间的一般图匹配问题
-
为了使优化端到端可微,我们将原始图匹配放松为连续二次规划,然后借助隐函数定理将其训练纳入深度图网络。

背景补充
这个地方是之前的经典的图匹配算法中没有提到的部分,因此补充一下背景知识便于后面的理解。
有原来的QAP问题:是一个NP难的问题。转化为连续的形式来进行松弛
为了使得图匹配问题可以通过可微优化方法来求解,通常需要对原始的离散优化问题进行放松。放松的意思是将离散的选择(如节点是否匹配)转化为连续的变量,使得优化问题变成一个连续的二次规划问题(Quadratic Programming, QP)。
- 二次规划(QP):是指目标函数是二次的(即包含平方项),约束条件是线性的优化问题。
- 连续放松:这意味着,原本在图匹配中可能只有“匹配”和“不匹配”两种选择的情况,在放松后,节点之间的匹配关系变成了一个连续变量,可以在某个范围内取值。这样,优化问题就变成了一个更容易处理的连续优化问题。通过这种放松,可以让我们使用常见的梯度下降等优化算法来求解问题。
这里就变成了一个连续的问题,例如之前的松弛是双随机矩阵,或者是谱方法这种。之前介绍过的。
所以大的理论还是要学习一下的,但基本的概念我相信这次就完全可以看懂了。
引言与相关工作
TBD范式的两个步骤:检测+数据关联。
最近的MOT工作主要从以下两个方面致力于提高数据关联的性能:
-
将关联问题表述为组合图划分问题,并通过先进的优化技术来解决它 (参考刚刚写的一篇论文外观图和运动图)
-
通过深度学习的力量改进外观模型
在MOT的图视图中,每个顶点代表一个检测边界框或一个轨迹,而边是在不同帧的顶点之间构建的,以表示它们之间的相似性。
-
那么关联问题可以表述为最小成本流问题(
这里描述的就是传统的匈牙利算的的匹配问题) 最流行的方法是在两个框架之间构建二分图并采用匈牙利算法 -
由于缺乏历史轨迹和长期记忆,这些方法对遮挡的鲁棒性不强。 传统上,这个问题的解决方法是从多个帧构建图,然后根据最小成本流问题的最优解导出最佳关联。
-
所有这些现有的工作都集中在寻找跨框架的最佳匹配,但忽略了框架内的上下文。(忽略了本身之间的关系)
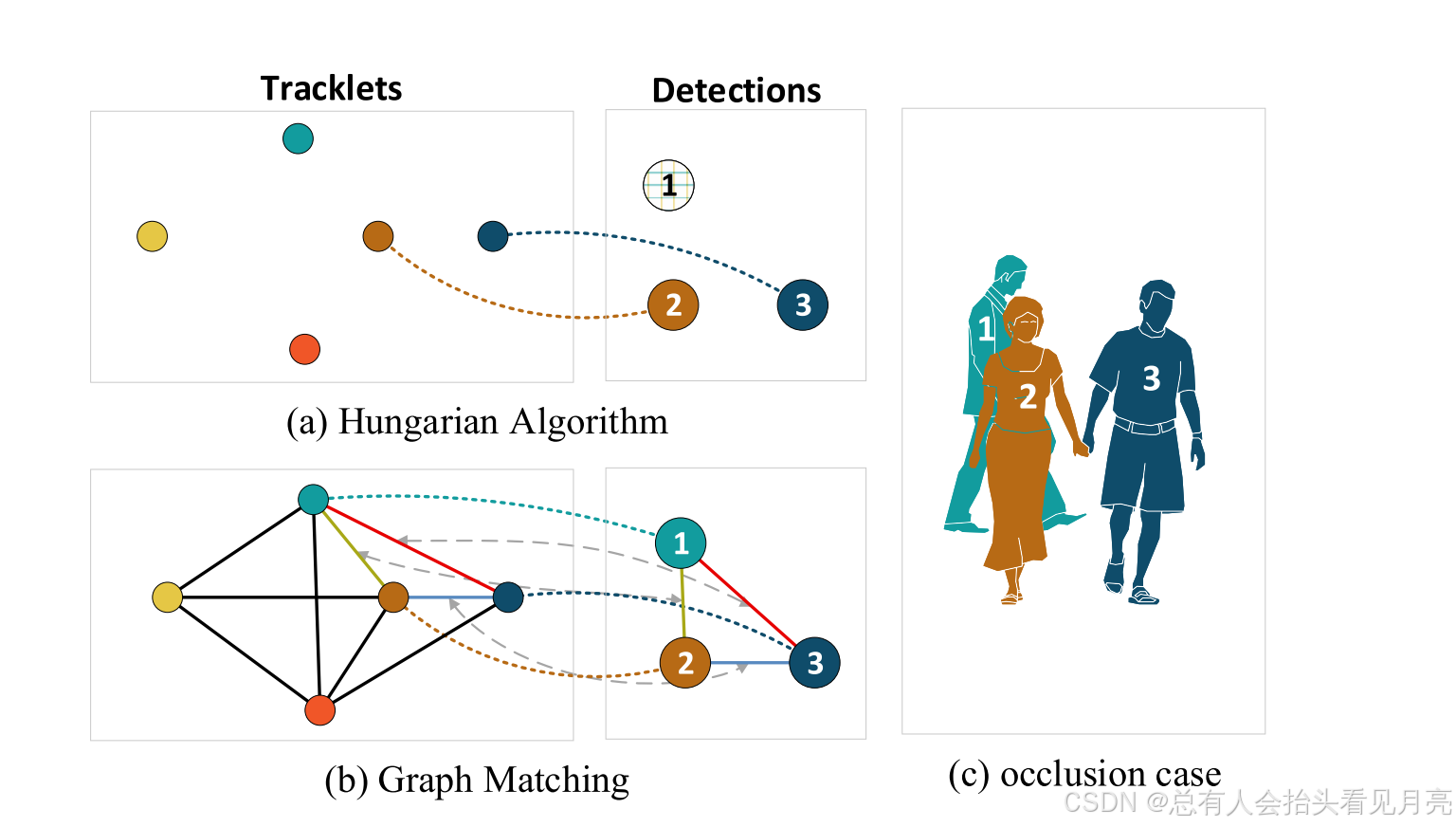
图 1:我们的图匹配公式中使用的图内关系的图示。 我们利用二阶边到边相似度来模拟群体活动,这在严重遮挡下更加稳健。 请注意,并非轨迹图中的所有顶点都可以与检测图匹配,因为它们在当前帧中消失。
通过过去与邻域对象的关系将被遮挡的对象与正确的轨迹进行匹配图1只是展示了这样一个例子。 有趣的是,同一框架内的这些成对关系可以表示为一般图中的边。
由二分图匹配变为了通用的图匹配的问题。
为了进一步将这种新颖的分配公式与强大的特征学习相结合,我们首先将图匹配的原始公式放松为二次规划,然后基于 KKT 条件和隐函数定理推导可微的 QP 层 图匹配问题,受到 OptNet的启发。 最后,可以与特征协同学习分配问题。
本文的贡献
-
我们不只关注跨框架的关联,而是强调框架内关系的重要性。 特别是,我们建议将关系表示为通用图,并将关联问题表示为通用图匹配。
-
为了解决这个具有挑战性的分配问题,并进一步将其与深度特征学习结合起来,我们基于问题的连续松弛推导了可微的二次规划层,并利用隐函数定理和KKT条件来推导反向过程中输入特征的梯度 -传播。
-
成对图匹配还考虑图中的二阶边到边关系。拉格朗日分解和分解图匹配是两个代表性的方法。
-
将问题松弛为凸优化问题,然后利用 KKT 条件和隐函数定理推导最优解处所有变量的梯度。
核心方法——Graph Matching Formulation for MOT
首先给出图匹配公式在MOT领域的数学表达形式
本文创新新的提出了一个新的方法(也可能不是它最早提的):图匹配公式放松为凸二次规划(QP),并将公式从边权重扩展到边缘特征。 这种松弛促进了特征表示和组合优化的可微分和联合学习。
Detection and Tracklet Graphs Construction
第一部分的公式描述给出了检测图和轨迹图的构建方式。
- 定义检测集和跟踪集(从过去的帧获得的轨迹的集合):nd 和 nt 表示检测到的对象和候选轨迹的数量。
D t = { D 1 t , D 2 t , ⋯ , D n d t } \mathcal{D}^{t}=\left\{D_{1}^{t}, D_{2}^{t}, \cdots, D_{n_{d}}^{t}\right\} Dt={D1t,D2t,⋯,Dndt}
T t = { T 1 t , T 2 t , ⋯ , T n t t } \mathcal{T}^{t}=\left\{T_{1}^{t}, T_{2}^{t}, \cdots, T_{n_{t}}^{t}\right\} Tt={T1t,T2t,⋯,Tntt}
- 其中检测集中的每一次检测由一个三元组表示:
D p t = ( I p t , g p t , t ) D_{p}^{t}=\left(\mathbf{I}_{p}^{t}, \mathbf{g}_{p}^{t}, t\right) Dpt=(Ipt,gpt,t)
- 其中 It p 包含检测区域中的图像像素
g p t = ( x p t , y p t , w p t , h p t ) \mathbf{g}_{p}^{t}=\left(x_{p}^{t}, y_{p}^{t}, w_{p}^{t}, h_{p}^{t}\right) gpt=(xpt,ypt,wpt,hpt)
- 是一个几何向量,包括检测边界框的中心位置和大小。
- 将检测框加入到轨迹集中的表示方式为:
T i d t ← T i d t − 1 ∪ { D ( i d ) t − 1 } T_{i d}^{t} \leftarrow T_{i d}^{t-1} \cup\left\{D_{(i d)}^{t-1}\right\} Tidt←Tidt−1∪{D(id)t−1}
- 然后我们将第 t 帧中的检测图定义为:帧 t 的轨迹图为:
G D t = ( V D t , E D t ) , G T t = ( V T t , E T t ) \mathcal{G}_{D}^{t}=\left(\mathcal{V}_{D}^{t}, \mathcal{E}_{D}^{t}\right),\mathcal{G}_{T}^{t}=\left(\mathcal{V}_{T}^{t}, \mathcal{E}_{T}^{t}\right) GDt=(VDt,EDt),GTt=(VTt,ETt)
- 每个顶点 i ∈ Vt D 和顶点 j ∈ Vt T 分别表示检测 Dt i 和轨迹 Tt j 。
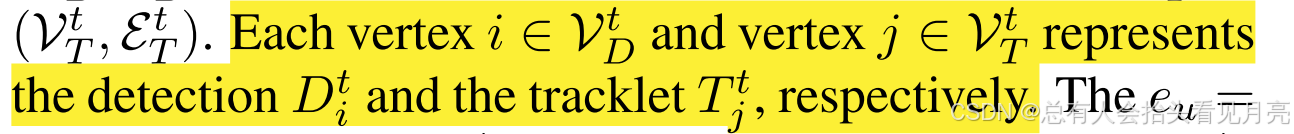
e u = ( i , i ′ ) is the edge in E D t e_{u}=\left(i, i^{\prime}\right) \text { is the edge in } \mathcal{E}_{D}^{t} eu=(i,i′) is the edge in EDt
e v = ( j , j ′ ) is the edge in E T t . e_{v}=\left(j, j^{\prime}\right) \text { is the edge in } \mathcal{E}_{T}^{t} . ev=(j,j′) is the edge in ETt.
然后,帧t中的数据关联可以表示为 GtD 和 GtT 之间的图匹配问题。为简单起见,我们将在以下部分中忽略t。
Basic Formulation of Graph Matching(基本图匹配公式)
给定检测图GD和轨迹图GT,图匹配问题是最大化匹配的顶点和由这些顶点连接的对应边之间的相似度。 在下面的推导中,我们使用通用符号G1和G2来获得通用图匹配公式。
和综述一样是一个传统的QAP问题。(K-B QAP)
maximize Π J ( Π ) = tr ( A 1 Π A 2 Π ⊤ ) + tr ( B ⊤ Π ) , s.t. Π 1 n = 1 n , Π ⊤ 1 n = 1 n , \begin{array}{ll} \underset{\boldsymbol{\Pi}}{\operatorname{maximize}} & \mathcal{J}(\boldsymbol{\Pi})=\operatorname{tr}\left(\mathbf{A}_{1} \boldsymbol{\Pi} \mathbf{A}_{2} \boldsymbol{\Pi}^{\top}\right)+\operatorname{tr}\left(\mathbf{B}^{\top} \boldsymbol{\Pi}\right), \\ \text { s.t. } & \boldsymbol{\Pi} \mathbf{1}_{n}=\mathbf{1}_{n}, \boldsymbol{\Pi}^{\top} \mathbf{1}_{n}=\mathbf{1}_{n}, \end{array} Πmaximize s.t. J(Π)=tr(A1ΠA2Π⊤)+tr(B⊤Π),Π1n=1n,Π⊤1n=1n,
Π ∈ { 0 , 1 } n × n \boldsymbol{\Pi} \in\{0,1\}^{n \times n} Π∈{0,1}n×n
-
是一个置换矩阵,表示两个图的顶点之间的匹配,
-
A1 ∈ Rn×n, A2 ∈ Rn×n 分别是图 G1 和 G2 的加权邻接矩阵
B ∈ R n × n \mathbf{B} \in \mathbb{R}^{n \times n} B∈Rn×n
- B ∈ Rn×n 是 G1 和 G2 之间的顶点亲和度矩阵。 1n表示所有值为1的n维向量。
Reformulation and Convex Relaxation(重构与凸松弛)
这里介绍的就是本文创新性的提出的松弛方法。
对于 Koopmans-Beckmann 的 QAP,因为 Π 是置换矩阵
Π ⊤ Π = Π Π ⊤ = I \boldsymbol{\Pi}^{\top} \boldsymbol{\Pi}=\boldsymbol{\Pi} \boldsymbol{\Pi}^{\top}=\mathbf{I} Π⊤Π=ΠΠ⊤=I
根据之前给出的公式一:我们可以推导出等价的形式将其重写为:
Π ∗ = arg min Π 1 2 ∥ A 1 Π − Π A 2 ∥ F 2 − tr ( B ⊤ Π ) . ( 2 ) \boldsymbol{\Pi}^{*}=\underset{\boldsymbol{\Pi}}{\arg \min } \frac{1}{2}\left\|\mathbf{A}_{\mathbf{1}} \boldsymbol{\Pi}-\boldsymbol{\Pi} \mathbf{A}_{\mathbf{2}}\right\|_{F}^{2}-\operatorname{tr}\left(\mathbf{B}^{\top} \boldsymbol{\Pi}\right) .(2) Π∗=Πargmin21∥A1Π−ΠA2∥F2−tr(B⊤Π).(2)
下面我们给出其简单的证明过程。(自己推的不一定正确)
其中 ∥ ⋅ ∥ F 表示 Frobenius 范数。 \text { 其中 }\|\cdot\|_{F} \text { 表示 Frobenius 范数。 } 其中 ∥⋅∥F 表示 Frobenius 范数。
- 利用矩阵的秩和转置的性质可以得到下面的推导形式。(公式1可以重写为)
tr ( A 1 Π A 2 Π ⊤ ) = tr ( Π ⊤ A 1 Π A 2 ) . J ( Π ) = tr ( Π ⊤ A 1 Π A 2 ) + tr ( B ⊤ Π ) . \operatorname{tr}\left(A_{1} \Pi A_{2} \Pi^{\top}\right)=\operatorname{tr}\left(\Pi^{\top} A_{1} \Pi A_{2}\right) . \mathcal{J}(\Pi)=\operatorname{tr}\left(\Pi^{\top} A_{1} \Pi A_{2}\right)+\operatorname{tr}\left(B^{\top} \Pi\right) . tr(A1ΠA2Π⊤)=tr(Π⊤A1ΠA2).J(Π)=tr(Π⊤A1ΠA2)+tr(B⊤Π).
- Frobenius 范数的平方可写为:
∥ A 1 Π − Π A 2 ∥ F 2 = tr ( ( A 1 Π − Π A 2 ) ⊤ ( A 1 Π − Π A 2 ) ) . \left\|A_{1} \Pi-\Pi A_{2}\right\|_{F}^{2}=\operatorname{tr}\left(\left(A_{1} \Pi-\Pi A_{2}\right)^{\top}\left(A_{1} \Pi-\Pi A_{2}\right)\right) . ∥A1Π−ΠA2∥F2=tr((A1Π−ΠA2)⊤(A1Π−ΠA2)).
展开为:
∥ A 1 Π − Π A 2 ∥ F 2 = tr ( ( Π ⊤ A 1 ⊤ − A 2 ⊤ Π ⊤ ) ( A 1 Π − Π A 2 ) ) . \left\|A_{1} \Pi-\Pi A_{2}\right\|_{F}^{2}=\operatorname{tr}\left(\left(\Pi^{\top} A_{1}^{\top}-A_{2}^{\top} \Pi^{\top}\right)\left(A_{1} \Pi-\Pi A_{2}\right)\right) . ∥A1Π−ΠA2∥F2=tr((Π⊤A1⊤−A2⊤Π⊤)(A1Π−ΠA2)).
∥ A 1 Π − Π A 2 ∥ F 2 = tr ( Π ⊤ A 1 ⊤ A 1 Π ) − 2 tr ( A 2 ⊤ Π ⊤ A 1 Π ) + tr ( A 2 ⊤ A 2 Π ⊤ Π ) . \left\|A_{1} \Pi-\Pi A_{2}\right\|_{F}^{2}=\operatorname{tr}\left(\Pi^{\top} A_{1}^{\top} A_{1} \Pi\right)-2 \operatorname{tr}\left(A_{2}^{\top} \Pi^{\top} A_{1} \Pi\right)+\operatorname{tr}\left(A_{2}^{\top} A_{2} \Pi^{\top} \Pi\right) . ∥A1Π−ΠA2∥F2=tr(Π⊤A1⊤A1Π)−2tr(A2⊤Π⊤A1Π)+tr(A2⊤A2Π⊤Π).
- 由于 Π是置换矩阵,因此满足正交性 Π⊤Π=𝐼利用这一性质,可以得到常数因此可以忽略。
1 2 ∥ A 1 Π − Π A 2 ∥ F 2 = 常数 − tr ( Π ⊤ A 1 Π A 2 ) . \frac{1}{2}\left\|A_{1} \Pi-\Pi A_{2}\right\|_{F}^{2}=\text { 常数 }-\operatorname{tr}\left(\Pi^{\top} A_{1} \Pi A_{2}\right) \text {. } 21∥A1Π−ΠA2∥F2= 常数 −tr(Π⊤A1ΠA2).
因此它们之间应该是等价的形式的。
可以证明置换矩阵的凸包位于双随机矩阵的空间内。 因此,QAP(方程2)可以通过仅将置换矩阵 Π 约束为双随机矩阵 X 来松弛至最紧的凸松弛,形成以下 QP 问题:
X ∗ = arg min X ∈ D 1 2 ∥ A 1 X − X A 2 ∥ F 2 − tr ( B ⊤ X ) , where D = { X : X 1 n = 1 n , X ⊤ 1 n = 1 n , X ≥ 0 } . \begin{array}{l} \mathbf{X}^{*}=\underset{\mathbf{X} \in \mathcal{D}}{\arg \min } \frac{1}{2}\left\|\mathbf{A}_{\mathbf{1}} \mathbf{X}-\mathbf{X} \mathbf{A}_{\mathbf{2}}\right\|_{F}^{2}-\operatorname{tr}\left(\mathbf{B}^{\top} \mathbf{X}\right),\\ \text { where } \mathcal{D}=\left\{\mathbf{X}: \mathbf{X} \mathbf{1}_{n}=\mathbf{1}_{n}, \mathbf{X}^{\top} \mathbf{1}_{n}=\mathbf{1}_{n}, \mathbf{X} \geq \mathbf{0}\right\} \text {. } \end{array} X∗=X∈Dargmin21∥A1X−XA2∥F2−tr(B⊤X), where D={X:X1n=1n,X⊤1n=1n,X≥0}.
From Edge Weights to Edge Features(从边的权重到边特征)
- 在上面的图匹配公式中,加权邻接矩阵 A ∈ Rn×n 中的元素 ai,i’ 是一个标量,表示edge(i, i’) 上的权重。
这个加权矩阵A在之前的两篇论文中都以及见过了
-
为了便于在 MOT 问题中的应用,我们通过使用 l2 归一化边缘特征 hi,i’ ∈ Rd 而不是 A 中标量形成的边缘权重 ai,i’ 来扩展松弛 QP 公式。
-
我们构建一个加权邻接张量 H ∈ Rd×n×n,其中 Hi,i’ = hi,i’ ,即,我们将 hi,i’ 的每个维度视为 A 中的元素 ai,i’ 并连接 它们沿着通道维度连接起来。
-
H1 和 H2 分别是 G1 和 G2 的加权邻接张量。 然后是方程中的优化目标。 可以进一步扩展以考虑两个对应的 n 维边缘特征之间的 l2 距离,而不是标量差异:
Π ∗ = arg min Π ∑ c = 1 d 1 2 ∥ H 1 c Π − Π H 2 c ∥ F 2 − tr ( B ⊤ Π ) \boldsymbol{\Pi}^{*}=\underset{\boldsymbol{\Pi}}{\arg \min } \sum_{c=1}^{d} \frac{1}{2}\left\|\mathbf{H}_{1}^{c} \boldsymbol{\Pi}-\boldsymbol{\Pi} \mathbf{H}_{2}^{c}\right\|_{F}^{2}-\operatorname{tr}\left(\mathbf{B}^{\top} \boldsymbol{\Pi}\right) Π∗=Πargminc=1∑d21∥H1cΠ−ΠH2c∥F2−tr(B⊤Π)
= arg min Π ∑ i = 1 n ∑ i ′ = 1 n ∑ j = 1 n ∑ j ′ = 1 n 1 2 ∥ h i i ′ π i j − h j j ′ π i ′ j ′ ∥ 2 2 − tr ( B ⊤ Π ) = arg min Π ∑ i = 1 n ∑ i ′ = 1 n ∑ j = 1 n ∑ j ′ = 1 n 1 2 ( π i j 2 − 2 π i j π i ′ j ′ h i i ′ ⊤ h j j ′ + π i ′ j ′ 2 ) − tr ( B ⊤ Π ) \begin{aligned} = & \underset{\boldsymbol{\Pi}}{\arg \min } \sum_{i=1}^{n} \sum_{i^{\prime}=1}^{n} \sum_{j=1}^{n} \sum_{j^{\prime}=1}^{n} \frac{1}{2}\left\|\mathbf{h}_{i i^{\prime}} \pi_{i j}-\mathbf{h}_{j j^{\prime}} \pi_{i^{\prime} j^{\prime}}\right\|_{2}^{2} \\ & -\operatorname{tr}\left(\mathbf{B}^{\top} \boldsymbol{\Pi}\right) \\ = & \underset{\boldsymbol{\Pi}}{\arg \min } \sum_{i=1}^{n} \sum_{i^{\prime}=1}^{n} \sum_{j=1}^{n} \sum_{j^{\prime}=1}^{n} \frac{1}{2}\left(\pi_{i j}^{2}-2 \pi_{i j} \pi_{i^{\prime} j^{\prime}} \mathbf{h}_{i i^{\prime}}^{\top} \mathbf{h}_{j j^{\prime}}\right. \\ & \left.+\pi_{i^{\prime} j^{\prime}}^{2}\right)-\operatorname{tr}\left(\mathbf{B}^{\top} \boldsymbol{\Pi}\right) \end{aligned} ==Πargmini=1∑ni′=1∑nj=1∑nj′=1∑n21∥hii′πij−hjj′πi′j′∥22−tr(B⊤Π)Πargmini=1∑ni′=1∑nj=1∑nj′=1∑n21(πij2−2πijπi′j′hii′⊤hjj′+πi′j′2)−tr(B⊤Π)
其中n是图G1和G2中的顶点数,下标i和i’是图G1中的顶点,j和j’是图G2中的顶点。 我们重新表述方程为:(也就得到了要求解的置换矩阵)
之后就是根据得到的置换矩阵求解其相似度矩阵了(边)(也是用到之前看的论文中的因式分解的图匹配的思想)
M是:是两个图中所有可能的边之间的对称二次亲和力矩阵。
π ∗ = arg min π π ⊤ ( ( n − 1 ) 2 I − M ) π − b ⊤ π , where π = vec ( Π ) , b = vec ( B ) and M ∈ R n 2 × n 2 \begin{array}{l} \boldsymbol{\pi}^{*}=\underset{\boldsymbol{\pi}}{\arg \min } \boldsymbol{\pi}^{\top}\left((n-1)^{2} \mathbf{I}-\mathbf{M}\right) \boldsymbol{\pi}-\mathbf{b}^{\top} \boldsymbol{\pi},\\ \text { where } \boldsymbol{\pi}=\operatorname{vec}(\boldsymbol{\Pi}), \mathbf{b}=\operatorname{vec}(\mathbf{B}) \text { and } \mathbf{M} \in \mathbb{R}^{n^{2} \times n^{2}} \end{array} π∗=πargminπ⊤((n−1)2I−M)π−b⊤π, where π=vec(Π),b=vec(B) and M∈Rn2×n2
我们将置换矩阵Π替换为双随机矩阵x就可以得到最终要推导的形式了。也就是方式为了一个QP问题来进行求解
x ∗ = arg min x ∈ D ′ x ⊤ ( ( n − 1 ) 2 I − M ) x − b ⊤ x , \mathbf{x}^{*}=\underset{\mathbf{x} \in \mathcal{D}^{\prime}}{\arg \min } \mathbf{x}^{\top}\left((n-1)^{2} \mathbf{I}-\mathbf{M}\right) \mathbf{x}-\mathbf{b}^{\top} \mathbf{x}, x∗=x∈D′argminx⊤((n−1)2I−M)x−b⊤x,
w h e r e D ′ = { x : R x = 1 , U x ≤ 1 , x ≥ 0 , R = 1 n 2 ⊤ ⊗ I n 1 , U = I n 0 ⊤ ⊗ 1 n 1 } , ⊗ d e n o t e s K r o n e c k e r p r o d u c t . where \mathcal{D}^{\prime}=\left\{\mathbf{x}: \mathbf{R x}=\mathbf{1}, \mathbf{U x} \leq \mathbf{1}, \mathbf{x} \geq \mathbf{0}, \mathbf{R}=\mathbf{1}_{n_{2}}^{\top} \otimes\right. \left.\mathbf{I}_{n_{1}}, \mathbf{U}=\mathbf{I}_{n_{0}}^{\top} \otimes \mathbf{1}_{n_{1}}\right\}, \otimes denotes Kronecker product. whereD′={x:Rx=1,Ux≤1,x≥0,R=1n2⊤⊗In1,U=In0⊤⊗1n1},⊗denotesKroneckerproduct.
因式分解部分复习
在实现中,我们首先计算GD和GT中边之间的余弦相似度来构造矩阵Me ∈ R|ED|×|ET|。 矩阵 Me 的元素是两个图中边缘特征 hi,i’ 和 hj,j’ 之间的余弦相似度:
M e u , v = h i , i ′ ⊤ h j , j ′ \mathbf{M}_{e}^{u, v}=\mathbf{h}_{i, i^{\prime}}^{\top} \mathbf{h}_{j, j^{\prime}} Meu,v=hi,i′⊤hj,j′
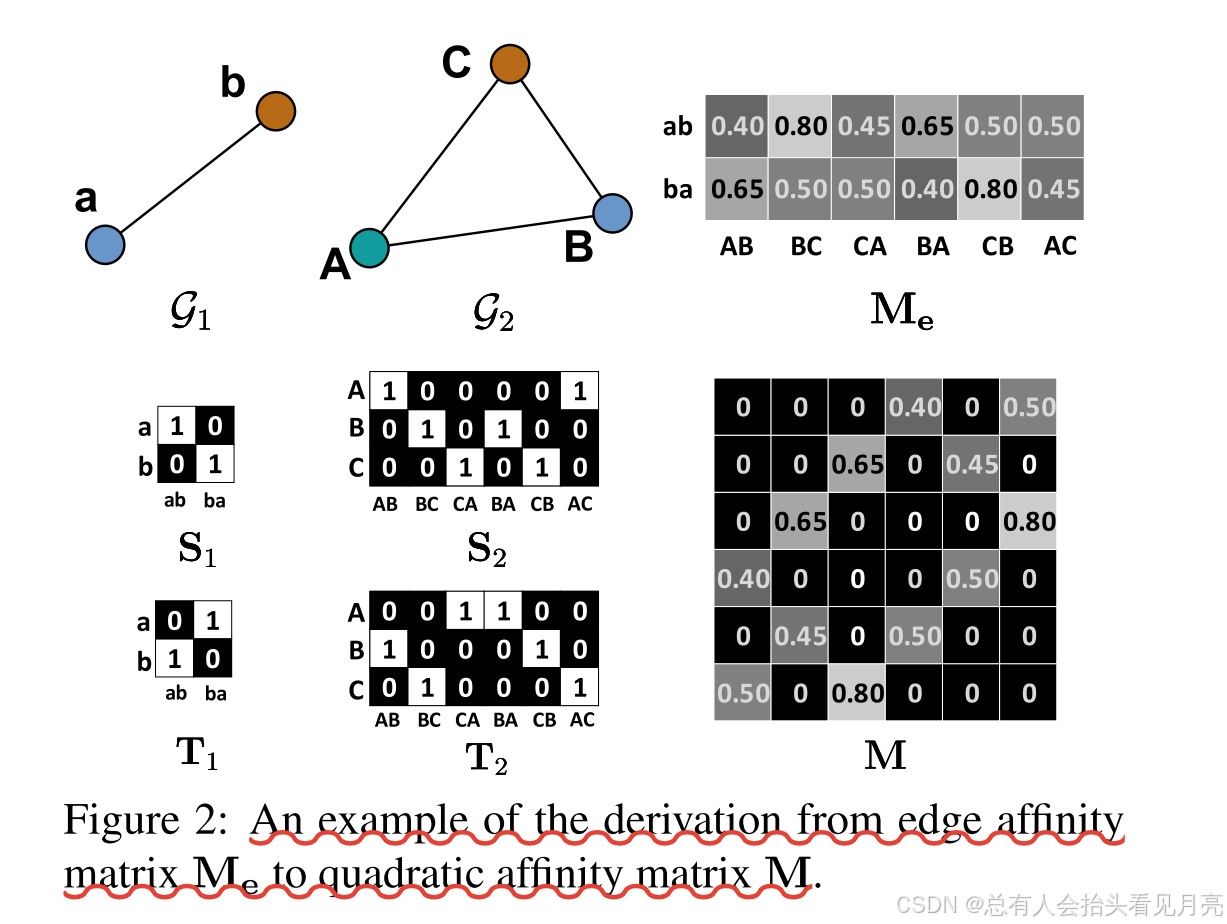
M = ( S D ⊗ S T ) diag ( vec ( M e ) ) ( T D ⊗ T T ) ⊤ , \mathbf{M}=\left(\mathbf{S}_{\mathbf{D}} \otimes \mathbf{S}_{\mathbf{T}}\right) \operatorname{diag}\left(\operatorname{vec}\left(\mathbf{M}_{\mathbf{e}}\right)\right)\left(\mathbf{T}_{\mathbf{D}} \otimes \mathbf{T}_{\mathbf{T}}\right)^{\top}, M=(SD⊗ST)diag(vec(Me))(TD⊗TT)⊤,


从图中也能看出来0和1表示连接关系。
此外,顶点亲和度矩阵 B 中的每个元素是顶点 i ∈ VD 上的特征 hi 与顶点 j ∈ VT 上的特征 hj 之间的余弦相似度:
B i , j = h i ⊤ h j \mathbf{B}_{i, j}=\mathbf{h}_{i}^{\top} \mathbf{h}_{j} Bi,j=hi⊤hj
核心流程
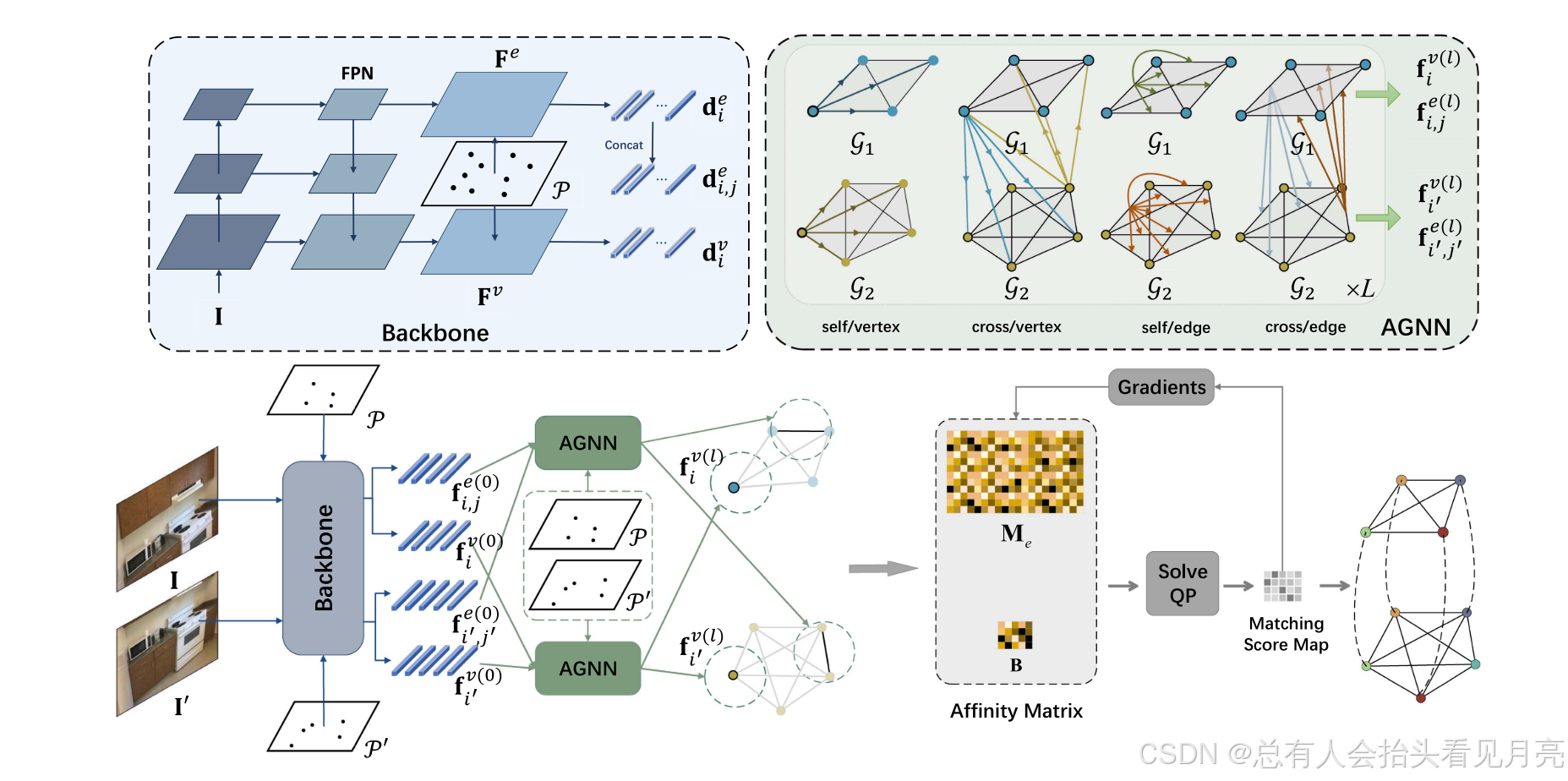
我们的图匹配网络的流程由三部分组成:
- (1)检测和轨迹图中的特征编码;
- (2)通过跨图图卷积网络(GCN)
- (3)可微图匹配层进行特征增强。
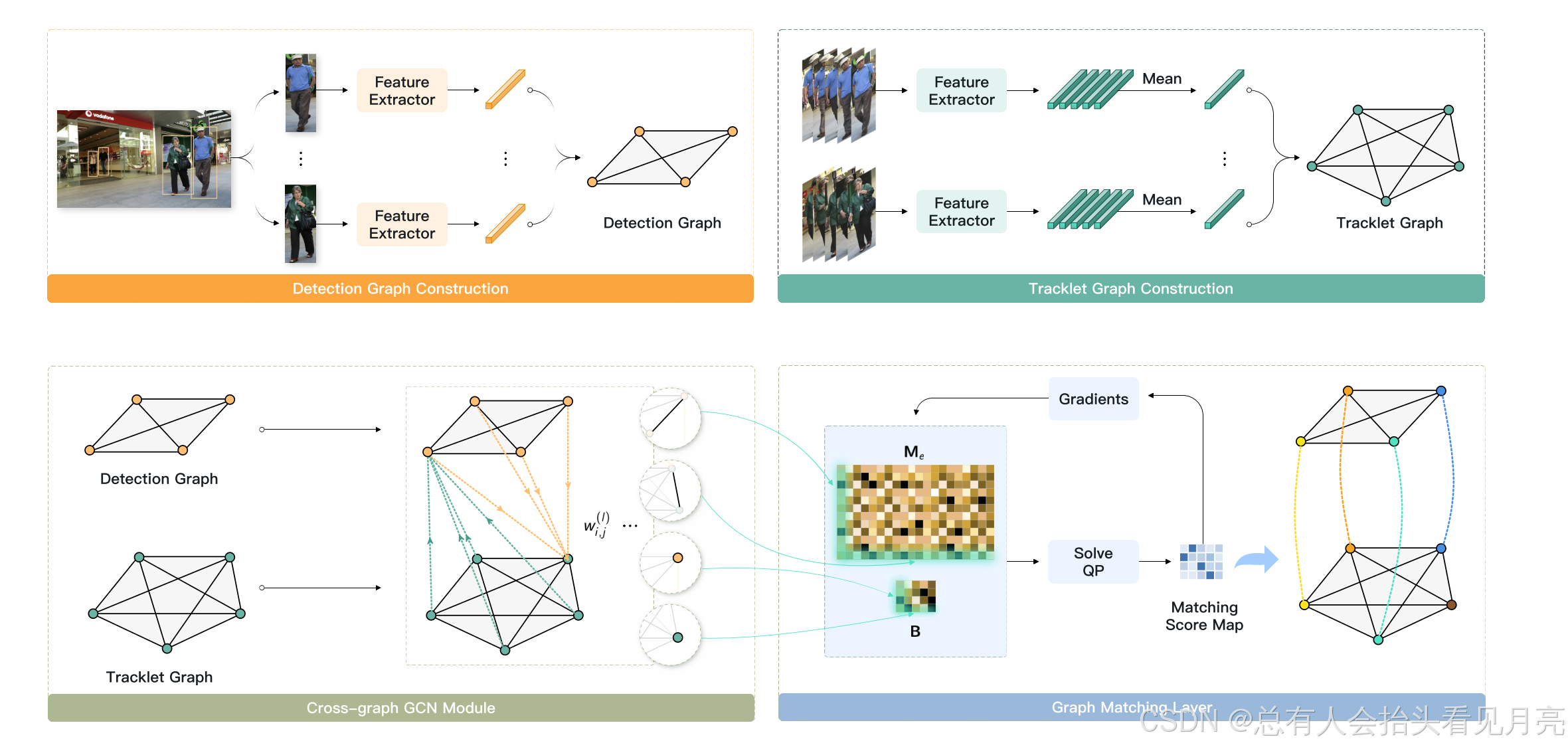
图 3:我们的方法概述。 我们首先从检测中提取特征并使用这些特征构建检测图。 Tracklet 图构建步骤与检测图类似,但我们对 Tracklet 中的特征进行平均。 然后采用跨图GCN来增强特征。 权重 wi,j 来自特征相似度和几何信息。 我们方法的核心是可微图匹配层,根据公式7构建为 QP 层。 图匹配层中的 Me 和 B 表示式中的边缘亲和度矩阵。 以及等式 11中的顶点亲和力矩阵.
下面的部分我们就分别对这三个部分来进行介绍。
Feature Encoding in Two Graphs(两个图的特征编码)
我们利用预训练的重识别(ReID)网络和多层感知器(MLP)来为每个检测 Di 生成外观特征 ai D。 Tracklet Tj 的外观特征 aj T 是通过对之前检测的所有外观特征进行平均而获得的。
Cross-Graph GCN(跨图卷积增强)
我们只是在图GD和图GT之间采用了一个GCN模块来增强特征,因此称为Cross-Graph GCN.
检测图和轨迹图上的初始顶点特征是顶点上的外观特征。
h i ( 0 ) = a D i and h j ( 0 ) = a T j . \mathbf{h}_{i}^{(0)}=\mathbf{a}_{D}^{i} \text { and } \mathbf{h}_{j}^{(0)}=\mathbf{a}_{T}^{j} . hi(0)=aDi and hj(0)=aTj.
下面的公式就和我师姐论文SCGTracker中的公式信息保持一致了区别就是g这个变量用的不一样,师姐两个坐标xy这里用的应该是提到的4个坐标位置。
对于这两个公式的解释参考学习一下之前写的师姐论文的解析
w i , j ( l ) = cos ( h i ( l ) , h j ( l ) ) + IoU ( g i , g j ) w_{i, j}^{(l)}=\cos \left(\mathbf{h}_{i}^{(l)}, \mathbf{h}_{j}^{(l)}\right)+\operatorname{IoU}\left(\mathbf{g}_{i}, \mathbf{g}_{j}\right) wi,j(l)=cos(hi(l),hj(l))+IoU(gi,gj)
h i ( l + 1 ) = MLP ( h i ( l ) + ∥ h i ( l ) ∥ 2 m i ( l ) ∥ m i ( l ) ∥ 2 ) , \mathbf{h}_{i}^{(l+1)}=\operatorname{MLP}\left(\mathbf{h}_{i}^{(l)}+\frac{\left\|\mathbf{h}_{i}^{(l)}\right\|_{2} \mathbf{m}_{i}^{(l)}}{\left\|\mathbf{m}_{i}^{(l)}\right\|_{2}}\right), hi(l+1)=MLP hi(l)+ mi(l) 2 hi(l) 2mi(l) ,
后面不同的地方就在于师姐计算了亲和力矩阵的方式是用余弦相似度,下面的是用数学的凸优化问题求解出来的近似的M在更具M进行匹配的。

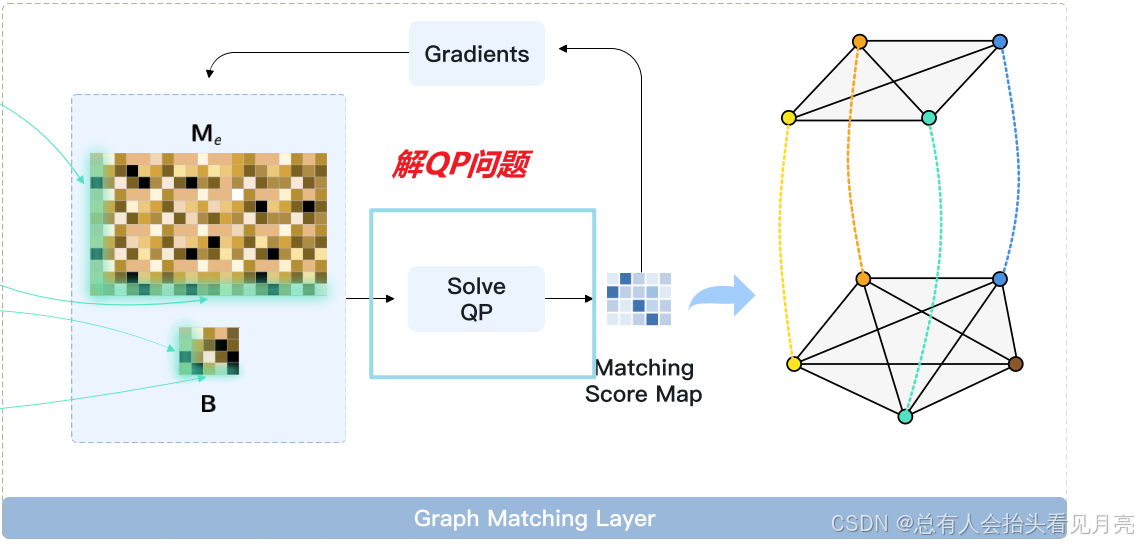
Differentiable Graph Matching Layer(可微图匹配层)
在增强图 GD 和 GT 上的顶点特征并构造边特征之后,我们遇到了我们方法的核心组件:可微图匹配层。 通过优化方程中的 QP。 6. 根据二次亲和矩阵 M 和顶点亲和矩阵 B,我们可以推导出最佳匹配得分向量 x 并将其重塑回形状 nd × nt 以获得匹配得分图 X。
由于我们最终将图匹配问题表述为 QP,因此我们可以将图匹配模块构建为神经网络中的可微 QP 层。 由于 KKT 条件是最优解 x* 及其对偶变量的充要条件,因此我们可以基于 KKT 条件和隐函数定理导出图匹配层后向传递中的梯度,这受到 OptNet 的启发
在我们的实现中,我们采用 qpth 库 来构建图匹配模块。 在推理阶段,为了降低计算成本并加速算法,我们仅使用CVXPY库求解QP进行前向操作
(也就是之前配环境一直失败找师兄的原因。)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











