







重写和重载的区别;
面向对象三大特征;
接口和抽象类有什么共同点和区别;
深拷贝和浅拷贝;
== 和equals和HashCOde的区别;
ArrayList 与 LinkedList 区别?其实是考链表和数组的区别;
ArrayList源码 分1.7 1.8;
HashMap和ConcurrentHashMap区别,讲讲各自原理
String、StringBuffer、StringBuilder 的区别;
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同;
讲讲反射
序列化和反序列化;
了解UML吗?说几个你常用的设计模式;
手写饿汉式、懒汉式。
IO多路复用
重写和重载的区别
首先一个方法的组成是 权限修饰符+返回值类型+方法名+(形参列表)+{方法体}
1.定义
方法的Overload 重载是发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
方法的Override重写是子类继承父类之后,可以对子类中同名同参数的方法,进行覆盖操作,参数列表和方法名必须相同
2.具体规则:
重写:首先要遵循“两同两小一大”
- “两同”即方法名相同、形参列表相同;
- “两小”指的是①子类方法返回值类型应比父类方法返回值类型更小或相等(父类被重写的方法的返回值类型是void,则子类被重写的方法的返回值类型真实void
父类被重写的方法的返回值类型是A类型,则子类重写的方法的返回值类型可以使A类或A类的子类
父类被重写的方法的返回值类型是基本数据类型,则子类重写的方法的返回值类型必须是相同的基本数据类型)②子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等; - “一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等。
其次,如果父类方法访问修饰符为 private/final/static 则子类就不能重写该方法
3.从编译运行的角度看:重载不表现为多态性,重写表现为多态性
重载,是指允许存在多个同名方法,而这些方法的参数不同。 编译器根据方法不同的参数表, 对同名方法的名称做修饰。对于编译器而言,这些同名方法就成了不同的方法。 它们的调用地址在编译期就绑定了。 Java的重载是可以包括父类和子类的,即子类可以重载父类的同名不同参数的方法。
所以: 对于重载而言,在方法调用之前,编译器就已经确定了所要调用的方法,这称为“早绑定”或**“静态绑定”** ;
而对于多态,只有等到方法调用的那一刻, 解释运行器才会确定所要调用的具体方法,这称为“晚绑定”或“动态绑定” 。
6.java基本数据类型
Java 中有 8 种基本数据类型,分别为:
- 6 种数字类型:
- 4 种整数型:
byte、short、int、long - 2 种浮点型:
float、double
- 4 种整数型:
- 1 种字符类型:
char - 1 种布尔型:
boolean。
这 8 种基本数据类型的默认值以及所占空间的大小如下:
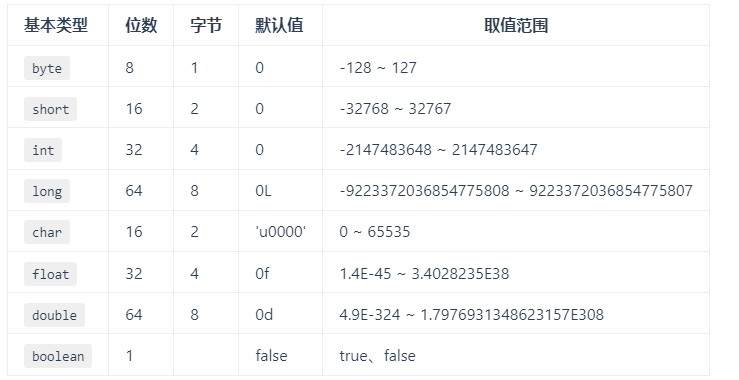
7.基本类型和包装类型的区别
- 成员变量包装类型不赋值就是
null,而基本类型有默认值且不是null。 - 包装类型可用于泛型,而基本类型不可以。
- 基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被
static修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。 - 相比于对象类型, 基本数据类型占用的空间非常小。
自动装箱与拆箱了解吗?原理是什么?
什么是自动拆装箱?
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 拆箱:将包装类型转换为基本数据类型;
8.面向对象三大特征
封装,继承,多态
封装:
封装是指把一个对象的状态信息(也就是属性)隐藏在对象内部,不允许外部对象直接访问对象的内部信息。但是可以提供一些可以被外界访问的方法来操作属性。
继承:
一. 继承性的格式:class A extend B{}
A:子类,派生类,subclass
B:父类,超类,基类,superclass
**二. 继承性的体现:**一旦子类A继承父类B以后,子类A中就获取了父类B中声明的所有属性和方法。特别地是父类中声明为private的属性或方法,子类继承父类以后,仍然认为获取了父类中私有的结构。只因为封装性的影响,使得子类不能直接调用父类的结构而已。
子类继承父类以后,还可以声明自己特有的属性或方法,实现功能的扩展。
三. Java中关于继承性的规定:
1.一个类中可以被多个子类继承
2.Java中类的单继承性:一个类只能有一个父类
3.子类是相对的概念
4.子类直接继承的父类称为:直接父类。间接继承的父类称为:间接父类
5.子类继承父类以后,就获取了直接父类以及所有间接父类中声明的属性和方法
四.补充:
1.如果我们没有显式的声明一个类的父类的话,则此类继承与java.lang.Object类
2.所有的java类(除java.lang.Object类之外)都直接或间接地继承与java.lang.Object
3.所有的java类具有java.lang.Object类声明的功能
多态:
1.理解多态性,可以理解为一个事物的多种形态
2.对象的多态性:父类的引用指向子类对象
Person p1=new Man();
3.多态的使用:虚拟方法调用
有了对象的多态性后,我们在编译期,只能调用父类中声明的方法,但在运行期,我们实际执行的是子类重写父类的方法。
总结:编译:看左边;运行:看右边
5.对象的多态性,只适用于方法,不适用于属性
7.有了对象的多态性以后,内存中实际上是加载了子类特有的属性和方法的,但是由于变量声明为父类类型,导致编译时,只能调用父类中声明的属性和方法。子类特有的属性和方法不能调用。
多态性的理解
1.实现代码的通用性
2.object类中定义的public boolean equals(Object obj){}
3.抽象类,接口的使用肯定体现了多态性。(抽象类,接口不能实例化)
9.接口和抽象类有什么共同点和区别?
抽象类:使用abstract修饰的类,(然后接三个特点)
①抽象类只能被继承;
②所以不能使用final修饰;
③抽象类不能被实例化。
接口:接口是一个抽象类型;是抽象方法的集合,接口中定义的方法,默认是public abstract修饰的抽象方法;接口支持多继承
相同点:
① 抽象类和接口都不能被实例化
② 抽象类和接口都可以定义抽象方法,子类/实现类必须覆写这些抽象方法
不同点:
构造方法的不同:① 抽象类有构造方法,接口没有构造方法
定义方法的不同:③抽象类可以包含普通方法,接口中只能是public abstract修饰抽象方法(Java8之后可以)
继承性的区别:③ 抽象类只能单继承,接口可以多继承
属性的区别:④ 抽象类可以定义各种类型的成员变量,接口中只能是public static final修饰的静态常量
抽象类的使用场景:
既想约束子类具有共同的行为(但不再乎其如何实现),又想拥有缺省的方法,又能拥有实例变量
接口的应用场景:
约束多个实现类具有统一的行为,但是不在乎每个实现类如何具体实现;实现类中各个功能之间可能没有任何联系
10 深拷贝和浅拷贝
当我们想复制一个对象是,最自然的操作就是直接赋值给另一个变量,这种做法只是复制了对象的地址,即现在两个变量是指向了同一个变量,任意一个变量操作了其中一个属性,都会影响到另一个变量,这种拷贝我们称之为引用拷贝,这种对同一个对象的操作,当然算不上真正意义上的拷贝,所以引用拷贝并不是对象拷贝。我们聊的对象拷贝一般指的是浅拷贝和深拷贝。
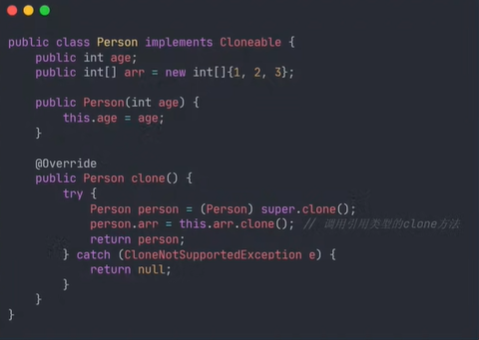
Object提供了一个clone()方法,见名知意,这个方法跟拷贝有关,该方法的访问修饰符为protected,如果子类不重新该方法,并将其声明为public,外部就调用不了对象的clone()方法。子类在重写时直接调用Object的clone()即可,如
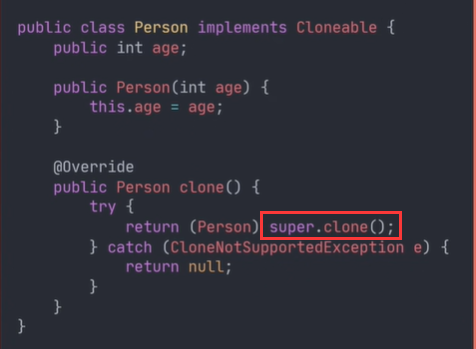
clone()是native方法,底层已经实现了对象的逻辑,注意子类一定要实现Cloneable接口,复制就会抛出异常。这样我们就可以调用clone()方法来复制对象,

这时候,两个对象就指向两个不同的对象了
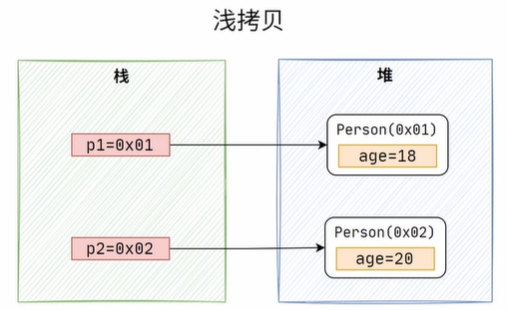
各自改变属性,也不会影响到另一个对象。但也存在一个问题,如果拷贝的对象中有引用类型,

那这种浅拷贝的方式,只会拷贝这类属性的引用地址,
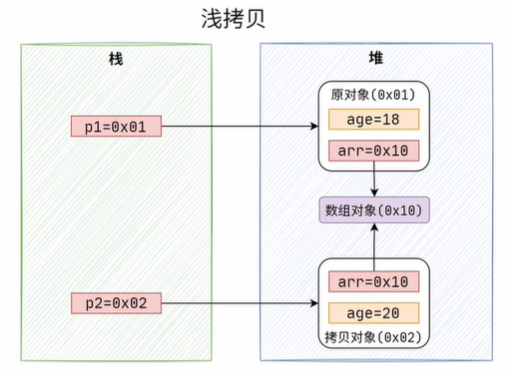
即拷贝对象和原对象的属性,都指向了同一个对象,如果对这类属性进行操作,则会影响到另一个对象的属性,如果也想将对象中的引用类型属性也进行拷贝,那就得用深拷贝了。我们需要对clone()方法修改一下,再clone()完对象后,我们再对对象的属性进行一次clone(),这样就完成了属性的复制。
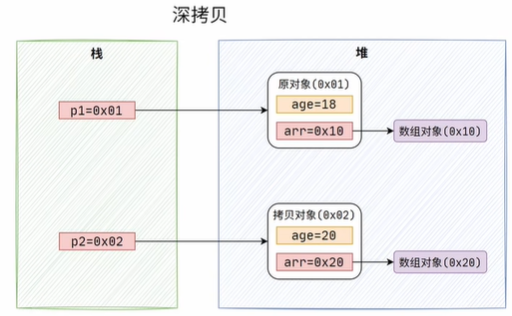
此时对象中的所有属性,也就指向不同的对象实例了。
稍微总结一下三者的区别。引用拷贝只是复制对象的地址,并不会创建一个新对象,浅拷贝会创建一个对象,并进行属性复制,不过对引用类型的属性,只会复制其对象地址,深拷贝则是完全复制整个对象,包括引用类型的属性
11. == 和equals和HashCode的区别
== 对于基本类型和引用类型的作用效果是不同的:
- 对于基本数据类型来说,
==比较的是值。 - 对于引用数据类型来说,
==比较的是对象的内存地址。
equals() 不能用于判断基本数据类型的变量,只能用来判断两个对象是否相等。equals()方法存在于Object类中,而Object类是所有类的直接或间接父类,因此所有的类都有equals()方法。但是Object类的eequals方法实际是使用的 ==
Object 类 equals() 方法:
public boolean equals(Object obj) {
return (this == obj);
}所以equals() 方法存在两种使用情况:
- 类没有重写
equals()方法 :通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象,使用的默认是Object类equals()方法。 - 类重写了
equals()方法 :一般我们都重写equals()方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
hashCode()
Java hashCode() 和 equals()的若干问题解答 - 如果天空不死 - 博客园
hashCode() 在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!
而在散列表中使用hashCode()的时候,一定要重写equals方法,因为如果产生哈希碰撞时候,需要比较对象是否相等,假如使用HashSet,相等需要进行覆盖,没有equals无法判断两个对象是否相等
12.String、StringBuffer、StringBuilder 的区别?
可变性:
String 是不可变的(后面会详细分析原因)。
StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串,不过没有使用 final 和 private 关键字修饰,最关键的是这个 AbstractStringBuilder 类还提供了很多修改字符串的方法比如 append 方法。
线程安全性:
String 中的对象是不可变的,
是线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能:
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据: 适用
String - 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
13.String的不可变性
翻开JDK源码,java.lang.String类起手前三行,是这样写的:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
@Stable
private final byte[] value;
......
......
}首先String类是用final关键字修饰,这说明String不可继承。再看下面,String类的主力成员字段value是个char[ ]数组,而且是用final修饰的。final修饰的字段创建以后就不可改变。
有的人以为故事就这样完了,其实没有。因为虽然value是不可变,也只是value这个引用地址不可变。挡不住Array数组是可变的事实。Array的数据结构看下图,

也就是说Array变量只是stack上的一个引用,数组的本体结构在heap堆。String类里的value用final修饰,只是说stack里的这个叫value的引用地址不可变。没有说堆里array本身数据不可变。看下面这个例子,
final int[] value={1,2,3}
int[] another={4,5,6};
value=another; //编译器报错,final不可变
value用final修饰,编译器不允许我把value指向堆区另一个地址。但如果我直接对数组元素动手,分分钟搞定。
final int[] value={1,2,3};
value[2]=100; //这时候数组里已经是{1,2,100}所以String是不可变,关键是因为SUN公司的工程师,在后面所有String的方法里很小心的没有去动Array里的元素,没有暴露内部成员字段。private final char value[]这一句里,private的私有访问权限的作用都比final大。而且设计师还很小心地把整个String设成final禁止继承,避免被其他人继承后破坏。所以String是不可变的关键都在底层的实现,而不是一个final。考验的是工程师构造数据类型,封装数据的功力。
14.集合
ArrayList源码
ArrayList的源码分析:
2.1 jdk 7情况下
ArrayList list = new ArrayList();//底层创建了长度是10的Object[]数组elementData
list.add(123);//elementData[0] = new Integer(123);
…
list.add(11);//如果此次的添加导致底层elementData数组容量不够,则扩容。
默认情况下,扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中。
结论:建议开发中使用带参的构造器:ArrayList list = new ArrayList(int capacity)
2.2 jdk 8中ArrayList的变化:
ArrayList list = new ArrayList();//底层Object[] elementData初始化为{}.并没有创建长度为10的数组
list.add(123);//第一次调用add()时,底层才创建了长度10的数组,并将数据123添加到elementData[0]
…
后续的添加和扩容操作与jdk 7 无异。
总结:jdk7中的ArrayList的对象的创建类似于单例的饿汉式,而jdk8中的ArrayList的对象的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。
jdk8中对arraylist的初始化进行了修改但是注解没改
15.集合
ArrayList 与 LinkedList 区别?
- 是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; - 底层数据结构:
ArrayList底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!) - 插入和删除是否受元素位置的影响:
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。LinkedList采用链表存储,所以,如果是在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),时间复杂度为 O(1),如果是要在指定位置i插入和删除元素的话(add(int index, E element),remove(Object o)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入。
- 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 - 内存空间占用:
ArrayList的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
ArrayList : 是基于动态数组,连续存储内存,适合下标访问(随机访问),扩容机制:默认情况下,扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中;
ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)LinkedList:基于链表的实现,存储内存是分散的,适合做插入和删除操作,查询慢,需要遍历链表,LinkedList连链表必须使用Iterator不能使用 for 循环,因为 for 循环是根据get(i) 获取某一元素时都需要对List进行重新遍历,应能消耗极大。
16.comparable 和 Comparator 的区别
Comparable接口的方式一旦一定,保证Comparable接口实现类的对象在任何位置都可以比较大小。
Comparator接口属于临时性的比较。
comparable:自然排序
对于自定义类来说,如果需要排序,我们可以让自定义类实现Comparable接口,重写compareTo(obj)方法。
在compareTo(obj)方法中指明如何排序
Comparator接口的使用:定制排序
1.背景:
当元素的类型没有实现java.lang.Comparable接口而又不方便修改代码,
或者实现了java.lang.Comparable接口的排序规则不适合当前的操作,
那么可以考虑使用 Comparator 的对象来排序
2.重写compare(Object o1,Object o2)方法,比较o1和o2的大小:
如果方法返回正整数,则表示o1大于o2;
如果返回0,表示相等;
返回负整数,表示o1小于o2。
17.比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
HashSet、LinkedHashSet和TreeSet都是Set接口的实现类,都能保证元素唯一,并且都不是线程安全的。HashSet、LinkedHashSet和TreeSet的主要区别在于底层数据结构不同。HashSet的底层数据结构是哈希表(基于HashMap实现)。LinkedHashSet的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。- 底层数据结构不同又导致这三者的应用场景不同。
HashSet用于不需要保证元素插入和取出顺序的场景,LinkedHashSet用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet用于支持对元素自定义排序规则的场景。
18.反射
反射的使用是基于class对象来处理的。在java中每一个类都存在着它的class对象,通过编译后,每一个类都会生成与之相关.class文件用来存储这些类信息。反射就是通过获取这些类信息例如获取该类对象存在那些变量及其类型,存在那些方法和构造函数细节。获取到这些信息后就可以以反射的方式创建一个该对象并对其进行相关操作。反射的使用大大的提高了代码的可扩展性,实现了一些本不能实现的功能,例如动态代理中就常常用到了反射。但是它破环了java中内部细节不对外部公开的封装特性,所以滥用可能会导致一系列安全问题。同时使用反射会降低性能,因为java不会对反射代码进行优化。
获取Class对象的三种方式:getClass();xx.class;Class.forName("xxx");
19.ConcurrentHashMap和HashMap
ConcurrentHashMap:ConcurrentHashMap的底层数据结构和hashmap类似都是使用数组+链表+红黑树实现的,所以基本功能和hashmap类似,并在其基础上加上了同步机制。在jdk1.7中使用分段锁segment来对数组进行分段,segment继承自ReentrantLock,分段后每个segment中的数组内容可以分开被线程操作。在size操作时先不加锁,最多计算三次,前后两次结果使相同的话就直接返回,若不相同则加锁计算。jdk1.8后采用Synchronize+CAS+Node的方式来保证并发安全性。使用此方式每次同步操作的对象不是整个数组而是每个Entry的头节点,它减小了封锁粒度,提升了效率。查询时不会加锁,只在修改时加锁。线程通过cas来抢占任务,成功后开始加锁操作。并且ConcurrentHashmap支持扩容时执行获取操作。
HashMap:在1.8之前,HashMap的底层是数组加链表,在1.8之后是数组+链表+红黑树; 它的put流程是:基于哈希算法来确定元素位置,当我们向集合存入数据时,他会计算传入的key的哈希值,并利用哈希值取绝对值再根据集合长度取余来确定元素的位置,如果这个位置已经存在其他元素了,就会发生哈希碰撞,则hashmap就会通过链表将这些元素组织起来,如果链表的长度达到8时,就会转化为红黑树,从而提高查询速度。 扩容机制:HashMap中数组的默认初始容量为16,当达到默认负载因子0.75时,会以2的指数倍进行扩容。 Hashmap时非线程安全的,在多线程环境下回产生循环死链,因此在多线程环境下建议使用ConcurrentHashMap。
说说final
final可以修饰类,方法,变量。 final修饰类,该类不可被继承。 final修饰方法,该方法不能被重写。 final修饰变量,如果是基本变量则值不能再改变,如果是引用变量则引用地址不能改变,但值可以改变。
Hashmap 和 hashtable
1.Hashtable在实现Map接口时保证了线程安全性,而HashMap则是非线程安全的。所以Hashtable的性能不如HashMap,因为为了保证线程它牺牲了一些性能。 2.Hashtable不允许存入null,无论是以null作为key或value,都会引发异常但则HashMap是允许的。Hashtable是很古老的API,性能不好,不推荐使用,要在多线程下使用ConcurrrntHashMap,它不但保证了线程安全,也通过降低锁的粒度提高了并发访问时的性能
说说static关键词
static可修饰类,方法,代码块,变量。不可以修饰构造器。\n 被static修饰的类为静态类,可以在不创建实例的情况下访问它的静态方法或静态成员变量,而其实例方法或实例成员变量只能通过其实例对象来访问。\n 在静态方法中不能使用this,因为this是随着对象创建而存在。 \n 静态成员变量随着静态类的加载而创建。
说说hashmap
在1.8之前,HashMap的底层是数组加链表,在1.8之后是数组+链表+红黑树; 它的put流程是:基于哈希算法来确定元素位置,当我们向集合存入数据时,他会计算传入的key的哈希值,并利用哈希值取绝对值再根据集合长度取余来确定元素的位置,如果这个位置已经存在其他元素了,就会发生哈希碰撞,则hashmap就会通过链表将这些元素组织起来,如果链表的长度达到8时,就会转化为红黑树,从而提高查询速度。 扩容机制:HashMap中数组的默认初始容量为16,当达到默认负载因子0.75时,会以2的指数倍进行扩容。 Hashmap时非线程安全的,在多线程环境下回产生循环死链,因此在多线程环境下建议使用ConcurrentHashMap。
20、序列化和反序列化
序列化的意思就是将对象的状态转化成字节流,以后可以通过这些值再生成相同状态的对象。对象序列化是对象持久化的一种实现方法,它是将对象的属性和方法转化为一种序列化的形式用于存储和传输。反序列化就是根据这些保存的信息重建对象的过程。
序列化:将java对象转化为字节序列的过程。
反序列化:将字节序列转化为java对象的过程。
优点:
a、实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(通常存放在文件里)Redis的RDB
b、利用序列化实现远程通信,即在网络上传送对象的字节序列。 Google的protoBuf
反序列化失败的场景:
序列化ID:serialVersionUID不一致的时候,导致反序列化失败
21、多路IO
IO多路复用指的是单个线程能够同时完成对多个IO事件的监听处理。linux提供了select、poll和epoll三种多路复用方式。本质上是利用内核缓存fd描述文件,并内核完成对文件描述符的监听操作。selec是将所用文件描述符的集合从用户态拷贝到内核空间,底层采用的是数组。poll和select相似,主要区别是poll底层使用的是链表,所以其能够监听的文件描述符不受限制。但是这两种方法都需要多次的内核与用户空间的复制拷贝,并且用户空间还需要在O(N)的时间复杂度下对描述符进行遍历才具体知道哪一个文件描述符发生了事件。epoll在内核开辟空间底层采用红黑树,用户可以直接在内核创建需要需要关注的文件描述的节点,当事件发送内核将对应文件描述符直接存入队列并将其返回到用户空间。epoll这种方式可以减少每次调用时从用户空间复制到内核的操作,并且因为内核返回的发送事件描述符的队列,可以减少每次轮询的操作,使得在O(1)的时间复杂度就能找到发送事件的描述符。
22.RabbitMQ
RabbitMQ 有哪些工作模式?
- 简单模式
- work 工作模式
- pub/sub 发布订阅模式
- Routing 路由模式
- Topic 主题模式
如何保证消息的可靠性?
消息到 MQ 的过程中搞丢,MQ 自己搞丢,MQ 到消费过程中搞丢。
- 生产者到 RabbitMQ:事务机制和 Confirm 机制,注意:事务机制和 Confirm 机制是互斥的,两者不能共存,会导致 RabbitMQ 报错。
- RabbitMQ 自身:持久化、集群、普通模式、镜像模式。
- RabbitMQ 到消费者:basicAck 机制、死信队列、消息补偿机制。
设计模式与原则
Q:了解设计模式吗?
A:
常用的设计模式有单例模式、工厂模式、代理模式、适配器模式、装饰器模式、模板方法模式等等。像sping中的定义的bean默认为单例模式,spring中的BeanFactory用来创建对象的实例,他是工厂模式的体现。AOP面向切面编程时代理模式的体现,它的底层就是基于动态代理实现的。适配器模式在springMVC中有体现,它的处理器适配器会根据处理器规则适配相应的处理器执行,模板方法模式用来解决代码重复的问题等
1、单例模式
Java设计模式之创建型:单例模式_张维鹏的博客-优快云博客
<Java设计模式>(三)单例模式_爱编程的大李子的博客-优快云博客
某个类只能生成一个实例,该实例全局访问,例如Spring容器里一级缓存里的单例池。
优点:
唯一访问:如生成唯一序列化的场景、或者spring默认的bean类型。
提高性能:频繁实例化创建销毁或者耗时耗资源的场景,如连接池、线程池。
缺点:
不适合有状态且需变更的
实现方式:
饿汉式:线程安全速度快
懒汉式:双重检测锁,第一次减少锁的开销、第二次防止重复、volatile防止重排序导致实例化未完成
静态内部类:线程安全利用率高
枚举:effictiveJAVA推荐,反射也无法破坏
懒汉式-安全版
public class Singleton {
private Singleton(){}
private static Singleton instance;
public static Singleton getInstance() {
if(instance==null){
synchronized (Singleton.class){
if(instance==null) {
instance = new Singleton();
}
}
}
return instance;
}
}
饿汉式
public class Singleton {
private Singleton(){}
public static final Singleton instance=new Singleton();
public static Singleton getInstance(){
return instance;
}
}2、工厂模式
Java设计模式之创建型:工厂模式详解(简单工厂+工厂方法+抽象工厂)_张维鹏的博客-优快云博客_java工厂模式
定义一个用于创建产品的接口,由子类决定生产何种产品。
优点:解耦:提供参数即可获取产品,通过配置文件可以不修改代码增加具体产品。
缺点:每增加一个产品就得新增一个产品类
3、抽象工厂模式
提供一个接口,用于创建相关或者依赖对象的家族,并由此进行约束。
优点:可以在类的内部对产品族进行约束
缺点:假如产品族中需要增加一个新的产品,则几乎所有的工厂类都需要进行修改。
UML
<Java设计模式>(二)UML类图 | 设计模式概述和分类_爱编程的大李子的博客-优快云博客
什么是UML?
一、概念
- UML—-Unified modeling language UML(统一建模语言),是一种用于软件系统分析和设计的语言工具,它用于帮助软件开发人员进行思考和记录思路的结果
- UML 本身是一套符号的规定,就像数学符号和化学符号一样,这些符号用于描述软件模型中的各个元素和他们之间的关系
二、分类:
- 1)用例图(use case)
- 2)静态结构图:类图、对象图、包图、组件图、部署图
- 3)动态行为图:交互图(时序图与协作图)、状态图、活动图
类图是描述类与类之间的关系的,是 UML 图中最核心的
类图
- 1)用于描述系统中的类(对象)本身的组成和类(对象)之间的各种静态关系
- 2)类之间的关系:依赖、泛化(继承)、实现、关联、聚合与组合
- 3)例子看链接

















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









