






对于以下数据
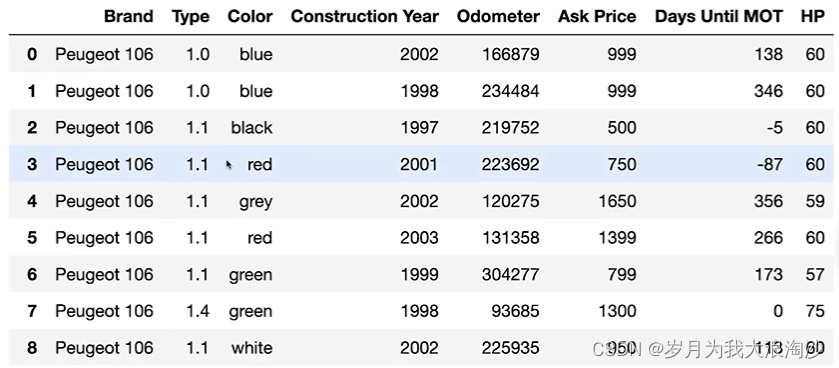
- Type、Color 独热编码
- Year、Odometer、HP不是一个量纲,要做归一化操作
具体操作如下
独热编码
# 颜色独热编码
# 使用get_dummies按照one-hot进行编码
df_colors=df['Color'].str.get_dummies().add_prefix('Color: ')
# 类型独热编码
# 先转成字符串
df_types=df['Type'].apply(str).str.get_dummies().add_prefix('Type: ')
# 添加独热编码数据列
df=pd.concat([df,df_colors,df_types],axis=1)
# 去除独热编码对应的原始列
# 每个Brand都一样,删掉
df=df.drop(['Brand','Type','Color'],axis=1)
效果
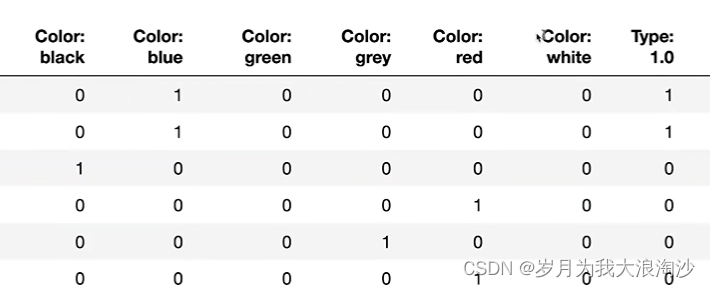
标签编码vs独热编码
标签编码:把一个类别表示成一个数值,比如0,1,2,3….
独热编码:在标签特征的基础上创建一个向量,向量的长度跟类别种类的个数相同。除了一个位置是1,其他位置均为0,
·1的位置对应的是相应类别出现的位置
但是,不可以直接将标签编码作为特征输入到模型里,因为数与数之间是有大小关系的,而且这些大小相关的信息必然会用到模型当中,这与原来特征的特点产生了矛盾,对于深度学习,数据分析来说它们之间并不存在所谓的“大小”,可以理解为平行关系。所以对于这类特征来说,直接用0,1,2…
的方式来表示是存在问题的,所以用独热编码来表达一个类别性特征
例:标签编码——大专:0 , 本科:1, 硕士:2, 博士:3, 大专:4, 独热编码——本科:(1,0,0,0), 硕士:(0,0,1,0), 博士:(0,0,0,1)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









