










目录
在上面数组的数据结果过了之后,接下来轮到链表
无论对于哪种语言,链表都是一个很重要的数据结构
链表的定义
链表通过指针将一组零散的内存块组合在一起,其中,我们把内存块成为链表的“节点”,为了将所有节点串起来,每个链表的节点除了存储数据之外,还需要记录链表的下一个节点地址
链表的结构如图所示
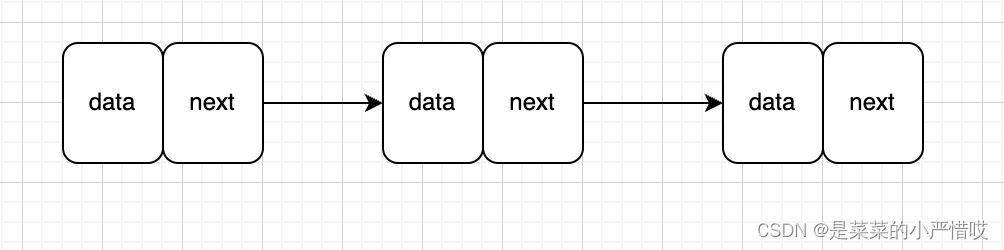
data+next就是一个节点
链表的特点
1、不需要连续的内存空间
2、有指针引用
常见的链表结构:单向链表、双向链表、循环链表
也正是因为链表的特点,所以链表没有所谓的内存地址计算公式,并且,因为链表每个节点除了数据之外还包含下一个节点的特性,存储相同的数据,链表占用的内存会比数组多
单链表
上面的链表结构示意图其实就是一个单链表
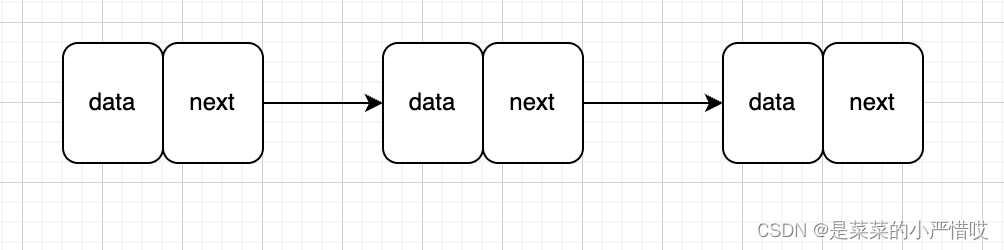
链表不像数组那样有内存地址计算公式,所以如果想要在链表里进行查询,那就是从头开始,一个一个看next,直到找到对应的数据为止,也就是说,时间复杂度是O(n)
链表的插入如何插入呢?插入的地方可以有三个,一个是从头插入,一个是从尾插入,一个是从中间插入,插入头或者尾的时候,我们只需要找到对应的位置,将next指向进行改变就可以了,而插入中间位置不大一样,需要改变插入节点前后的next指针
它和数组的插入明显的不一样就是链表不用移动,链表的插入就是先断开指针,断开前指向当前,当前的next指向断开后,而数组如果插入尾部,其实和链表的效果是一样的,不过链表不需要考虑越界问题,但,需要考虑内存问题
链表的删除,就更简单,直接把断开前的next指向断开后就好了
链表还有两个特殊的节点,头节点和尾节点,头节点用来记录链表的基地址,拿到头节点,我们就可以遍历整个链表,而尾节点特殊的地方是因为,尾节点的next是NULL,表示这是链表的最后一个节点
循环链表
循环链表是一种特殊的单链表,它和单链表唯一的区别就在于尾节点,单链表的尾节点是指向一个空地址NULL,而循环链表的尾节点,指向的是头节点,就像一个环一样, 首尾相连,所以才叫做循环链表
双向链表
所谓双向链表,和单链表不同的是,单链表只有一个指向后置节点的next指针,而双向链表除了存在指向后置节点的指针之外,还存在一个指向前置节点的prev节点,也就是说,通过一个节点,获取完成这一整个链表
当然,多了一个前置指针,占用的内存空间更大了
双向循环链表
双向链表存在一个延伸,那就是双向循环链表,和循环链表相似,也是尾节点的next指向头节点,当然,你可能会说,既然是双向链表,我尾节点一直prev也能获取到头,但是,有没有一种可能,直接尾节点.next更快呢?
代码实现链表
用代码实现链表,其实无非就是节点和每个节点之间的对应关系
我们来构建一个这样的数据结构
public class MyListNodes {
private ListNode head;
private int size = 0;
public class ListNode {
int value;
ListNode next;
public ListNode(int value) {
this.value = value;
this.next = null;
}
}
}
简单来写其实就是这样的,MyListNodes是我们的链表,ListNode是我们一个个的节点,根据我们上面说的特性,链表拿到一个head,头结点,就可以拿到整个链表,并且可以存储一个链表的长度方便后续的使用
当然,链表是有它自己的一些方法的,我们实现一些经典的常用的方法,比如插入头、插入第n个、删除头、删除第n个、打印,当然,细节之处我们暂时忽略,比如越界问题,某个节点为空的异常等
public class MyListNodes {
private ListNode head;
private int size = 0;
/**
* @Description: 插入头节点
* @Author: create by YanXi on 2022/8/26 14:35
* #Enail: best.you@icloud.com
*
* @param value 要插入的值
* @exception
* @Return: void
*/
public void insertHead(int value) {
ListNode node = new ListNode(value);
// 不能直接替换,head可能有数据
node.next = head;
head = node;
}
/**
* @Description: 插入某一个位置
* @Author: create by YanXi on 2022/8/26 15:10
* #Enail: best.you@icloud.com
*
* @param value 要插入的值
* @param position 要插入的位置
* @exception
* @Return: void
*/
public void insertNP(int value, int position) {
// 如果等于 0 ,说明是头结点
if (position == 0) {
insertHead(value);
} else {
// 找到要插入的节点的位置
ListNode nowPostition = head;
for (int i = 0; i < position; i++) {
nowPostition = nowPostition.next;
}
// 打断链表,插入新节点,并链接断开的点位
ListNode node = new ListNode(value);
// 断开后,让新的节点的指针指向原来的下一个节点
node.next = nowPostition.next;
// 将上一个节点的下一个节点指向新节点
nowPostition.next = node;
}
}
/**
* @Description: 删除头节点
* @Author: create by YanXi on 2022/8/26 15:12
* @Email: best.you@icloud.com
*
* @param
* @exception
* @Return: void
*/
public void deleteHead() {
head = head.next;
}
/**
* @Description: 删除某个位置的节点
* @Author: create by YanXi on 2022/8/26 15:12
* @Email: best.you@icloud.com
*
* @param position 要删除的位置
* @exception
* @Return: void
*/
public void deleteNP(int position) {
if (position == 0) {
deleteHead();
}else {
ListNode nowPostition = head;
for (int i = 0; i < position; i++) {
nowPostition = nowPostition.next;
}
nowPostition.next = nowPostition.next.next;
}
}
/**
* @Description: 打印整个链表
* @Author: create by YanXi on 2022/8/26 15:12
* @Email: best.you@icloud.com
*
* @param
* @exception
* @Return: void
*/
public void printList() {
ListNode nowPostition = head;
System.out.println(nowPostition.value);
while (nowPostition.next != null) {
System.out.println(nowPostition.value);
nowPostition = nowPostition.next;
}
}
/**
* @Description: 查找指定值的node
* @Author: create by YanXi on 2022/8/26 15:24
* @Email: best.you@icloud.com
*
* @param queryValue 要查找的值
* @exception
* @Return: ListNode
*/
public ListNode query(int queryValue) {
ListNode nowPostition = head;
while (nowPostition.next != null) {
if (nowPostition.value == queryValue) {
break;
}
nowPostition = nowPostition.next;
}
return nowPostition;
}
public class ListNode {
int value;
ListNode next;
public ListNode(int value) {
this.value = value;
this.next = null;
}
}
}
当然, 我们也可以实现一个双向链表,双向链表比单链表多了一个前驱结点
我们实现一下插入头方法就行了,其他的方法其实也就是类似的
public class DoubleListNodes {
private DoubleNode head; // 头结点
private DoubleNode tail; // 尾结点
public DoubleListNodes() {
head = null;
tail = null;
}
/**
* @Description: 插入头结点
* @Author: create by YanXi on 2022/8/28 16:10
* @Email: best.you@icloud.com
*
* @param data 要插入的数据
* @exception
* @Return: void
*/
public void insertHead(int data) {
DoubleNode node = new DoubleNode(data);
if (head == null) {
tail = node;
} else {
head.pre = node;
node.next = head;
}
head = node;
}
class DoubleNode{
int value; // 值
DoubleNode next; // 下一节点
DoubleNode pre; // 前一节点
public DoubleNode(int value) {
this.value = value;
this.next = null;
this.pre = null;
}
}
}
面试题-LRU缓存淘汰算法
如何设计LRU缓存淘汰算法?
所谓LRU,就是长时间不使用的就淘汰掉
我们只需要维护一个有序的单链表就行了,这个顺序,就是加入的时间排序
如果新插入一个值,先遍历链表,如果存在,那就删除,并且插入到头结点,如果不存在,那就直接插入头部,当然,需要判断链表能否继续插入,毕竟LRU也是有存储限制的,如果有,直接插入,没有的话,那就删除最后的节点,最后的节点一定是相对于最少使用的
当然,这只是一个简单的使用,实际在查询时,可以结合数组等方法,进行优化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









