







 这篇博客详细介绍了评分卡模型的构建流程,包括实验设计、样本设计、模型训练与评估,以及逻辑回归和集成学习评分卡的实现。在模型上线过程中,强调了模型的区分度、稳定性与业务指标。还涵盖了特征筛选、WOE编码和模型评价指标如AUC、KS等。
这篇博客详细介绍了评分卡模型的构建流程,包括实验设计、样本设计、模型训练与评估,以及逻辑回归和集成学习评分卡的实现。在模型上线过程中,强调了模型的区分度、稳定性与业务指标。还涵盖了特征筛选、WOE编码和模型评价指标如AUC、KS等。
1. 模型构建流程
1.1 实验设计
- 新的模型能上线一定要比原有方案有提升,需要通过实验证明

- 业务逐渐稳定后,人工审核是否会去掉
- 一般算法模型上线后,在高分段和低分段模型表现较好,中间的用户可能需要人工参与审核
- 模型表现越来越好之后,人工审核的需求会逐步降低,但不会去掉
- 标准模型:逻辑回归,随机森林
- 策略和模型不会同时调整
1.2 样本设计
- ABC卡观察期,表现期
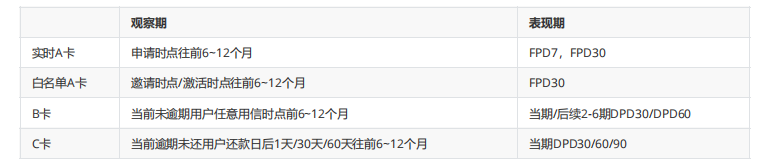
- 还款状态和DPD一起刻画了用户的逾期情况
- A卡 申请新客 B卡未逾期老客 C卡 逾期老客
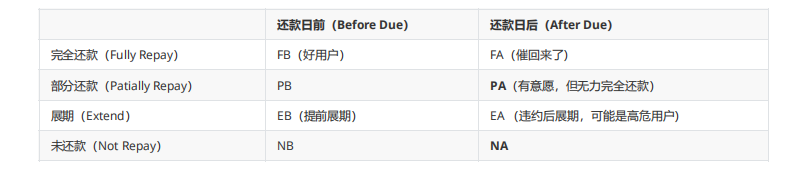
- 当前逾期:出现逾期且到观测点为止未还清 NA,PA
- 历史逾期:曾经出现过逾期已还清或当前逾期 FA,NA,PA
- 举例

上面情况属于A卡

上面情况属于B卡

上面情况属于C卡 - 样本设计表格
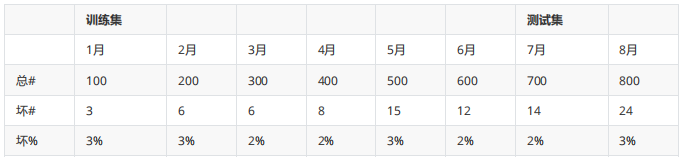
- 观察坏样本的比例,不要波动过大
- 客群描述:首单用户、内部数据丰富、剔除高危职业、收入范围在XXXX
- 客群标签:好: FPD<=30 坏: FPD>30
1.3 模型训练与评估
- 目前还是使用机器学习模型,少数公司在尝试深度学习
- 模型的可解释性>稳定性>区分度
- 区分度:AUC,KS
- 稳定性: PSI
- 业务指标:通过率,逾期率
- 逾期率控制在比较合理的范围的前提下,要提高通过率
- A卡,要保证一定过得通过率,对逾期率可以有些容忍
- B卡,想办法把逾期率降下来,好用户提高额度
- AUC 和 KS
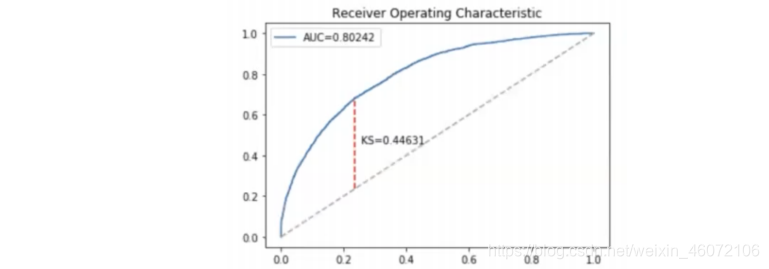
- AUC:ROC曲线下的面积,反映了模型输出的概率对好坏用户的排序能力
- KS反映了好坏用户的分布的最大的差别
- ROC曲线是对TPR和FPR的数值对的记录
- KS = max(TPR-FPR)
- AUC和KS的区别可以简化为:
- AUC反映模型区分度的平均状况
- KS反映了模型区分度的最佳状况
- PSI和特征里的PSI完全一样
1.4 模型上线整体流程

2. 逻辑回归评分卡
2.1 评分映射方法
- 使用逻辑回归模型可以得到一个[0,1]区间的结果, 在风控场景下可以理解为用户违约的概率, 评分卡建模时需要把违约的概率映射为评分
2. 计算
- 用户的基础分为650分
- 当这个用户非逾期的概率是逾期的概率的2倍时,加50分
- 非逾期的概率是逾期的概率的4倍时,加100分
- 非逾期的概率是逾期的概率的8倍时,加150分
- 以此类推,就得到了业内标准的评分卡换算公式

- score是评分卡映射之后的输出, 正 样 本 是样本非逾期的概率, 负 样 本 是样本逾期的概率
- 逻辑回归评分卡如何与评分卡公式对应:
- 逻辑回归方程为
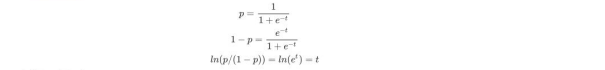
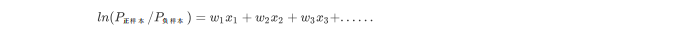
- 在信用评分模型建模时,逻辑回归的线性回归成分输出结果为 正 样 本 负 样 本 ,即对数似然。
- 由对数换底公式可知:
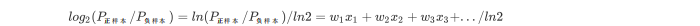
只需要解出逻辑回归中每个特征的系数,然后将样本的每个特征值加权求和即可得到客户当前的标准化信用评分
- 基础分(Base Score)为650分,步长(Point of Double Odds,PDO)为50分,这两个值需要根据业务需求进行调整
3. 应用
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
import numpy as np
import random
import math
- 读取数据
data = pd.read_csv('data/Bcard.txt')
data.head()
输出结果

- 数据字段说明:
- bad_ind 为标签
- 外部评分数据:td_score,jxl_score,mj_score,rh_score,zzc_score,zcx_score
- 内部数据: person_info, finance_info, credit_info, act_info
- obs_month: 申请日期所在月份的最后一天(数据经过处理,将日期都处理成当月最后一天)
- 看一下月份分布,用最后一个月做为跨时间验证集
data.obs_mth.unique()
输出结果:
array(['2018-10-31', '2018-07-31', '2018-09-30', '2018-06-30', '2018-11-30'], dtype=object)
- 划分测试数据和验证数据(时间外样本)
train = data[data.obs_mth != '2018-11-30'].reset_index().copy()
val = data[data.obs_mth == '2018-11-30'].reset_index().copy()
- 取出建模用到的特征
#info结尾的是自己做的无监督系统输出的个人表现,score结尾的是收费的外部征信数据
feature_lst = ['person_info','finance_info','credit_info','act_info','td_score','jxl_score','mj_score','rh_score']
- 训练模型
x = train[feature_lst]
y = train['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1)
lr_model.fit(x,y)
输出结果
LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
- 模型评价
- ROC曲线:描绘的是不同的截断点时,并以FPR和TPR为横纵坐标轴,描述随着截断点的变小,TPR随着FPR的变化
- 纵轴:TPR=正例分对的概率 = TP/(TP+FN),其实就是查全率 召回
- 横轴:FPR=负例分错的概率 = FP/(FP+TN) 原本是0被预测为1的样本在所有0的样本中的概率
- KS值
- 作图步骤:
- 根据学习器的预测结果(注意,是正例的概率值,非0/1变量)对样本进行排序(从大到小)-----这就是截断点依次选取的顺
序 按顺序选取截断点,并计算TPR和FPR —也可以只选取n个截断点,分别在1/n,2/n,3/n等位置 横轴为样本的占比百分
比(最大100%),纵轴分别为TPR和FPR,可以得到KS曲线max(TPR-FPR) - ks = max(TPR-FPR)TPR和FPR曲线分隔最开的位置就是最好的”截断点“,最大间隔距离就是KS值,通常>0.2即可认为模型有比较好偶的预测准确性
- ROC曲线:描绘的是不同的截断点时,并以FPR和TPR为横纵坐标轴,描述随着截断点的变小,TPR随着FPR的变化
- 绘制ROC计算KS
y_pred = lr_model.predict_proba(x)[:,1] #取出训练集预测值
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred) #计算TPR和FPR
train_ks = abs(fpr_lr_train - tpr_lr_train).max() #计算训练集KS
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1] #计算验证集预测值
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred) #计算验证集预测值
val_ks = abs(fpr_lr - tpr_lr).max() #计算验证集KS值
print('val_ks : ',val_ks)
from matplotlib
import pyplot as plt
plt.plot(fpr_lr_train 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









