




1什么是pandas
- pandas是一个可编程的ETL框架(支持多种数据源的导入)非常nb!
- 一般用来做数据的处理,比较常见运行在jupyter做数据处理
- 主要类型为DataFrame,Series
- DataFrame 包含index,values,column
- Series 只包含 index,values 他有点像一个列表
2.pandas基本操作
2.1增
我们一般把一个DataFrame 数据 写作一个df
column =["周1","周2","周4","周5"]
index= ["语文","数学","外语","魔法"]
values = [[1,0,1,0],[0,0,1,0],[1,0,1,0],[0,0,1,0]]
df = pd.DataFrame(data=values,index=index,columns=column)
df
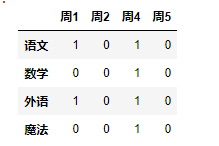
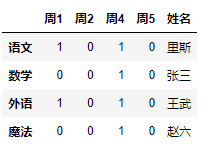
如果你想加入一列
我比较常用的写法是
df["姓名"]=["里斯","张三","王武","赵六"]
df
"__________________如果你要指定位置的话__________________"
"这里的 4 指的是indxe(索引) 实际情况根据你的需要自己写"
df.insert(4,column="姓名",value=["里斯","张三","王武","赵六"])
如果你觉得column 不是你想要的效果
"通过给变量重新赋值的方式 达到你的目的"
df = df[["姓名","周1","周2","周4","周5"]]
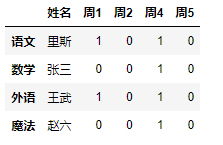
增加行数据通过创建 pd.Series
_ = pd.DataFrame(
data= [["王武",0,1,1,0]],
index=["物理"],
columns=["姓名","周1","周4","周5","性别"]
)
df.append(_)
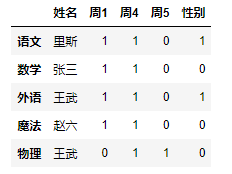
2.2删
删除某一列数据
del df["周2"]
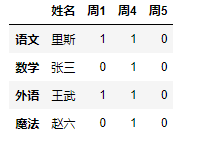
删除某一行数据
"根据索引删除"
df.drop(index=?,inplace=True)
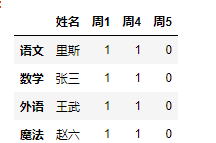
2.3改
通常可以通过给字段重新赋值的方式 重置掉字段
df["周1"]=[1,1,1,1]
2.4查
"单列查询"
df.column
df[column]
"多列查询"
df[[column1,column2,column3,column4.....,column N]]
# 条件查询语句 他有点类似 mysql 的 sql 语句同样他也可以在结果最后分组group by聚合和sql的一样
"loc[筛选条件,数据项] 值得一提的是 or在这里用 |表示 and 用 &表四"
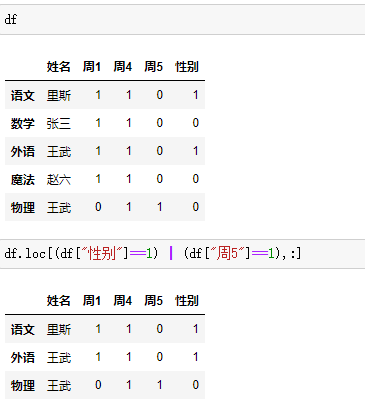
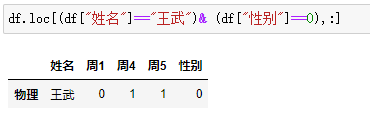
2.4.1 模糊查询条件
df[“字段”].str.contains("包含的字“),[数据项]
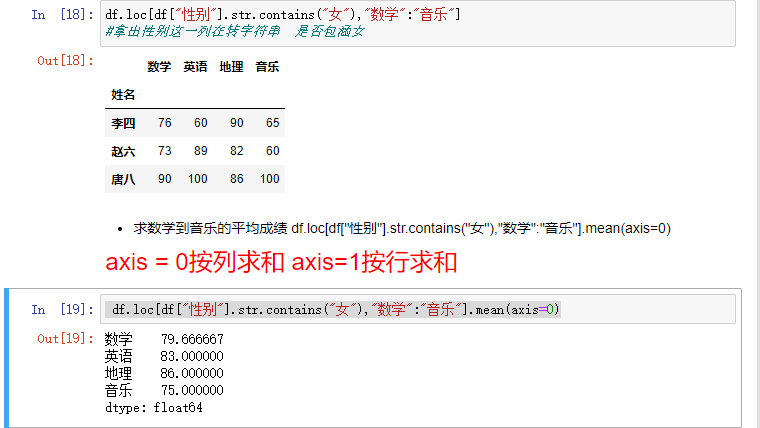
2.4.2统计
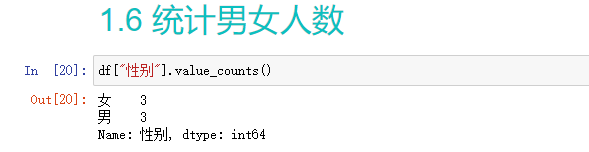
- mean() 平均值
- idxmax()返回最大的索引
- meadian()中位数
- value_counts()统计 出现的个数
- .sort_values(by=“支付金额/¥”,ascending=False)
pandas基础数据类型
- numpy 存在信息损失 但是pandas 可以弥补这一缺陷
import sqlite3 as sq3
import pandas as pd
conne = sq3.connect("10万条照招聘数据/10万条招聘数据/recruit.db")
df = pd.read_sql("select * from recruit",conne)
df.info()
直方图
pandas
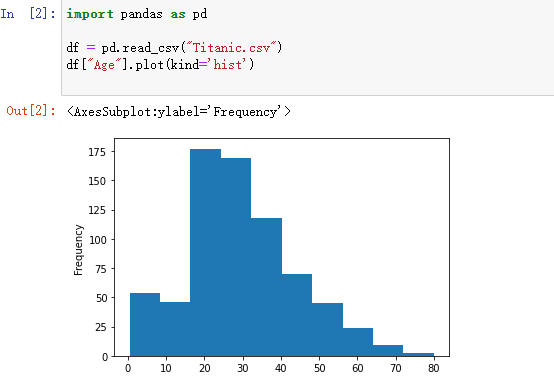
import pandas as pd
df = pd.read_csv("Titanic.csv")
# 年龄分布
df["Age"].plot(kind='hist')
#黄色各个年龄段存活人数
df[df["Survived"] ==1]["Age"].plot(kind="hist")
#绿色代表各个年龄段的死亡人数
df[df["Survived"] ==0]["Age"].plot(kind="hist")
请在命令台或者notebook中执行
plot
plot
- kind 图标类型
- bins 分成多少断
- normed 是否否和正态分布
- 对于脱敏数据的通过直方图可以预测,
直方图的中心点分离的越多,重合越少代表这个特征越好



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









