







 这篇博客探讨了数据结构中的二叉树特性,包括完全二叉树的叶节点数量,二叉树的线索化,以及非叶节点与下层节点权值的关系。此外,还讨论了哈夫曼树的构建和编码性质,指出哈夫曼编码的最优性和不唯一性。同时,涉及图的存储方式,如邻接矩阵,并举例说明了无向图的边检测。最后,阐述了树转换为二叉树的规则及其特点。
这篇博客探讨了数据结构中的二叉树特性,包括完全二叉树的叶节点数量,二叉树的线索化,以及非叶节点与下层节点权值的关系。此外,还讨论了哈夫曼树的构建和编码性质,指出哈夫曼编码的最优性和不唯一性。同时,涉及图的存储方式,如邻接矩阵,并举例说明了无向图的边检测。最后,阐述了树转换为二叉树的规则及其特点。
1-1 一棵有124个结点的完全二叉树,其叶结点个数是确定的。
T
1-2 二叉树中序线索化后,不存在空指针域。
F第一个节点无前驱,最后一个节点无后继,左前右后
1-3 对N(≥2)个权值均不相同的字符构造哈夫曼树,则树中任一非叶结点的权值一定不小于下一层任一结点的权值。
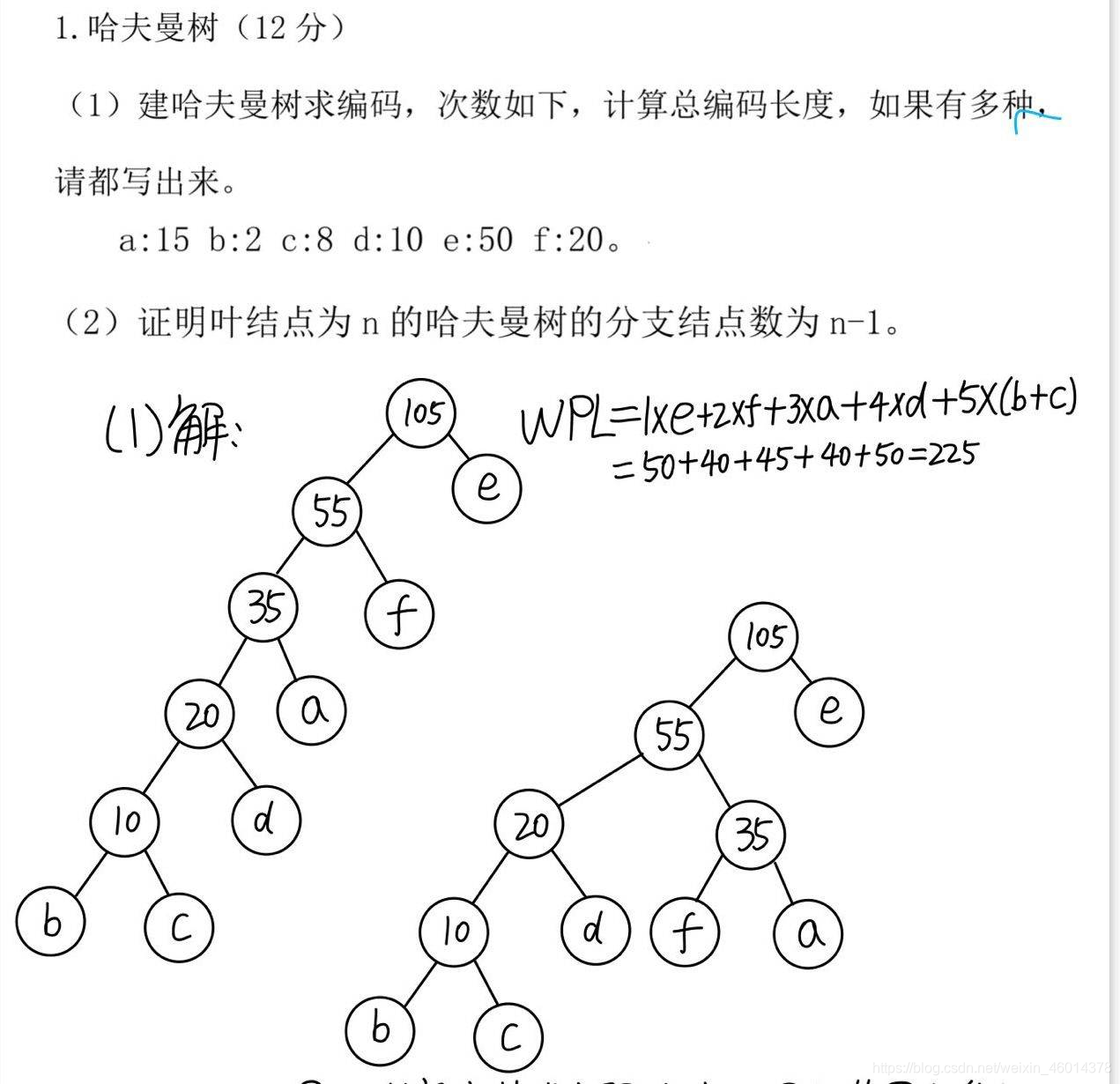
T权值越大编码长度越短,权值越小编码长度越长。节点所在层数越小编码长度越短,权值就越大
1-4 哈夫曼编码是一种最优的前缀码。对一个给定的字符集及其字符频率,其哈夫曼编码不一定是唯一的,但是每个字符的哈夫曼码的长度一定是唯一的。
F,如图哈夫曼编码不唯一,长度也不唯一
1-5 对于一个有N个结点、K条边的森林,不能确定它共有几棵树。
F,如果不看根节点的话,每条边都连着一个儿子,所以一棵树中 节点数=边数+1;在森林中判断几棵树,只要判断有几个根节点就行了,也就是N-K;
1-6 树的后根序遍历序列等同于它所对应二叉树的中序遍历序列。
T
1-7 二叉树可以用二叉链表存储,树无法用二叉链表存储。
F,二叉树也是树的一种啊,二叉树可以存;树可以转换为二叉树
1-8 将一棵树转成二叉树,根结点没有左子树。
F,没有右子树,有左子树
1-9 用邻接矩阵法存储图,占用的存储空间数只与图中结点个数有关,而与边数无关。
T,邻接矩阵是二维矩阵,大小为vnum*vnum
1-10 用一维数组G[]存储有4个顶点的无向图如下:G[] = { 0, 1, 0, 1, 1, 0, 0, 0, 1, 0 },则顶点2和顶点0之间是有边的。
T,其实二维数组本质上也是一维数组,一般来说为了方便使用邻接矩阵存储图,但对于无向图来说,邻接矩阵是上下对称的,所以就造成了空间的浪费。所以就用一维数组存储无向图。但注意是下三角形。如下图
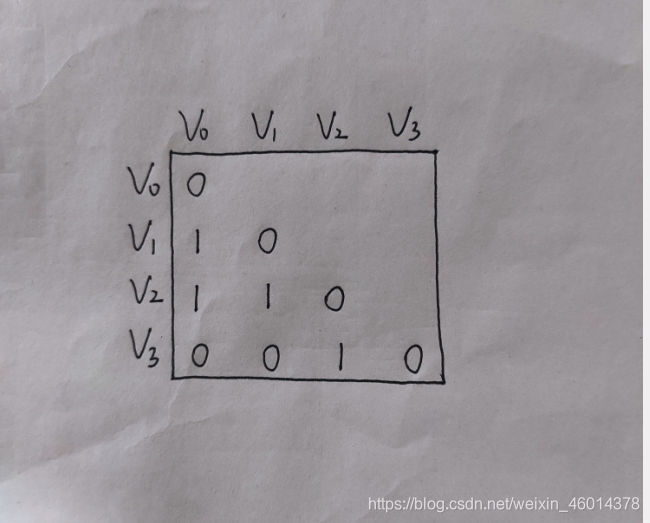


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









