










 本文介绍Python数据处理相关内容,涉及pandas、numpy和matplotlib模块。pandas用于数据处理,如读取、筛选、聚合等;numpy用于数组处理与计算;matplotlib用于绘制曲线。文中还通过实例讲解了pandas的使用方法,包括数据读取、筛选、缺失值处理等。
本文介绍Python数据处理相关内容,涉及pandas、numpy和matplotlib模块。pandas用于数据处理,如读取、筛选、聚合等;numpy用于数组处理与计算;matplotlib用于绘制曲线。文中还通过实例讲解了pandas的使用方法,包括数据读取、筛选、缺失值处理等。
#python数据处理-pandas,numpy,matplotlib:
对于数据来说,有数据爬取-爬虫,数据处理-就是今天学习的,以及数据分析-sklearn,tensoflow机器学习及深度学习;
因为我们步入了新的时代了,互联网实际环境数据量都是很大的,所以仅仅会小数据量的处理,对于非互联网职位足矣,但是想进入互联网公司恐怕就要学习大数据了;
在这个过程我们总担心我们我们不会敲代码,但其实更应该担心的是我们是否形成了一个思考问题解决办法的思维及视野,这才是我们需要不断努力的;代码熟练也没啥捷径,就是敲,用的多了也就会了记住了,也许记不住但是也知道去哪查找了,讲真的从我学习的经验看,反反复复就是那几个函数,但是参数的选择确实需要一定的思考。
1.言归正传,先说说各个模块的是什么及作用:
a.pandas:pandas主要用于数据处理,比如读取数据、筛选数据、缺失值处理、聚合函数(max,min,mean,sum等),分组,排序,数据表合并拆分,数据透视等,特别的是提供了日期处理函数,让日期更加灵活,慢慢体会,你需要的他基本都可以实现;
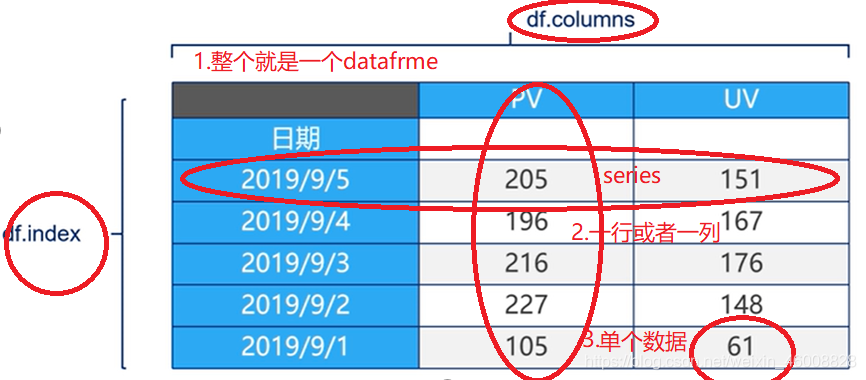
数据格式(和excle一样,行列都有索引便于查找):
①.单个数据
②.seties:一行或者一列;
③.dataframe:多行或者多列。
b.numpy:主要用于数组处理及一些计算,以及进行数组的变化及计算;其他模块对numpy也是有依赖的,数据处理时安装导入;
c.matplotlib:主要是绘制曲线的,用作制作曲线,已经算是比较强大了,基本上我们工作中会遇到的曲线他都可以绘制出来。
2.pandas模块通过实例讲解:
爬取数据: 一个北京的温度信息:源码(不好用自己修修,实在不行自己编几个数据也行,以上都不满意,留言咱们聊聊):
#数据爬取模块requests及数据清洗模块lxml引入
import requests
from lxml import etree
#数据存储进mysql数据库,引入操作的驱动模块
import pymysql
#=============================数据存储======================================
#年月日日期
ymd1 = []
#最高温度
Tmax = []
#最低温度
Tmin = []
#天气
TQ = []
#风向-风力
fengxiang_li = []
#===============================结束==========================================
def main():
year = int(input("输入查询的year:"))
for A in range(12):
# 获北京天气网页的信息
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"}
if A <= 8:
url = "http://lishi.tianqi.com/beijing/"+str(year) + "0" + str(A+1) + ".html"
else:
url = "http://lishi.tianqi.com/beijing/"+ str(year) + str(A+1) + ".html"
#获取北京天气网页网页信息
html = requests.get(url,headers = header).content.decode()
data = etree.HTML(html)
#正则表达式进行数据筛选
ymd = data.xpath('//li/div[@class="th200"]')
Tmax = data.xpath('//li//div[@class="th140"]')
Tmin = data.xpath('//li//div[@class="th140"]')
TQ = data.xpath('//li//div[@class="th140"]')
fengxiang_li = data.xpath('//li//div[@class="th140"]')
#收集到的信息进行合并-列表
ymd.extend(ymd)
Tmax.extend(Tmax)
Tmin.extend(Tmin)
TQ.extend(Tmin)
fengxiang_li.extend(fengxiang_li)
#保存数据到MySQL:留下的疑问:为什么不能加入列表,统一入库。。。。。。。。。
sql_TQ = data_mysql()
sql_TQ.save_mysql(ymd,Tmax,Tmin,TQ,fengxiang_li)
# 保存到本地
# with open("tianqi.txt", "a") as f:
# for i in range(len(ymd)):
# print(ymd[i].text)
# f.write('{:},{:},{:},{:},{:}\n'.format(ymd[i].text,Tmax[4*i].text,Tmin[4*i+1].text,TQ[4*i+2].text,fengxiang_li[4*i+3].text))
# f.close()
class data_mysql():
def __init__(self): # 定义需要初始化的参数(可省略)
# 1.创建数据库链接,给cursor添加一个参数,让其的到数据是一个字典
self.db = pymysql.connect(host='localhost', port=3306, user='root', password='f199506', db='TQ_MYSQL',charset='utf8')
self.cursor = self.db.cursor(cursor=pymysql.cursors.DictCursor)
def save_mysql(self,ymd,Tmax,Tmin,TQ,fengxiang_li):
# 1.保存数据到数据库:
# a.创建表格
# self.sql = 'create table TQ_MYSQL(id int auto_increment key ,ymd varchar(50),Tmax varchar(10),Tmin varchar(10),TQ varchar(10),fengxiang_li varchar(50)) '
# self.cursor.execute(self.sql) # 执行mysql语句
# self.db.commit() # 提交事务
# b.插入数据
self.sql = 'INSERT INTO tq_mysql(ymd,Tmax,Tmin,TQ,fengxiang_li) VALUES("%s","%s","%s","%s","%s")'
for i in range(len(ymd)//2):
self.cursor.execute(self.sql%(ymd[i].text,Tmax[4*i].text,Tmin[4*i+1].text,TQ[4*i+2].text,fengxiang_li[4*i+3].text) ) # 执行mysql语句
self.db.commit() # 提交事务
# c.删除数据
# self.sql = 'TRUNCATE table tq_mysql'
# self.cursor.execute(self.sql) # 执行mysql语句
# self.db.commit() # 提交事务
# d.关闭数据库链接
self.cursor.close()
self.db.close()
#爬取北京的天气情况,按年进行爬取
if __name__ == '__main__':
main()
以上就获得了到了数据;
a.读取数据:
要想处理数据肯定要拿到数据,用read函数很好理解吧:
# coding=gb2312 #加入编码格式,否则会报错,这个东西真的有用,不骗人
import pandas as pd
import pymysql
import numpy as np
#======================================读取表格数据查询====
#1.读取本地CSV数据
df = pd.read_csv(r"D:\\python\\pandas\\data\\tq_mysql.csv")
#2.读取.txt文件
df = pd.read_csv(
"D:\\python\\pandas\\data\\tq_mysql.csv",
sep = "\t",
header = None,
names = ['ymd','Tmax','Tmin','TQ','fengxiang_li']
)
#3.读取excel数据
'''
参数:
#header=0 定义是否存在头,可以是数字及None,如果头部上有空格这个参数有意义;
inplace=True:更改后直接替换原文件;
skiprows=0:跳过多少行数;
usecols="C:D":选取几列;
index_col 默认值(index_col = None)——重新设置一列成为index值;
index_col=False——重新设置一列成为index值;index_col=0——第一列为index值
dtype={"ID":str}:设置某一列数据类型;
'''
df = pd.read_excel(r"D:\\python\\pandas\\data\\tq_mysql.xlsx")
#4.读取MySQL数据库数据
db = pymysql.connect(host='localhost', port=3306, user='root', password='f199506', db='tq_mysql',charset='utf8')
df = pd.read_sql("select * from tq_mysql;",con = db)
db.close()
b.查看数据 (可以查看读取到的信息是否正确):
#======================================基础查询================
#1.打印数据
print(df)
#2.打印前五行,规定是显示几行
print(df.head())
#3.打印后五行,也可以加入n,规定是显示几行
print(df.tail())
#4.打印列名,行名
print(df.columns,df.index)
#5.打印维度:行列个数
print(df.shape)
# 6.打印数据类型
print(df.dtypes)
#7.打印统计信息:
print(df.describe)
#8.打印dataframe的详细信息:
print(df.info())
c.筛选数据:
①.筛选数据常用的就是loc函数(按标签查询筛选,常用),很强大,不信你看:
#========================loc======================
#1.按行列标签查询
print(df.loc[['2019-01-01 ','2019-01-02 ','2019-01-03 '],'Tmin'])
print(df.loc[['2019-01-01 ','2019-01-02 ','2019-01-03 '],['Tmin','Tmax']])
#2.按区间进行查询
print(df.loc['2019-01-01 ':'2019-01-03 ','Tmin'])
print(df.loc['2019-01-01 ','ymd':'Tmin'])
print(df.loc['2019-01-01 ':'2019-01-03 ','ymd':'Tmin'])
#3.按判断情况查询
# 把温度数据℃去掉,并转换成int类型,方便后续处理
df.loc[:,"Tmax"] = df["Tmax"].str.replace("℃","").astype("int32")
df.loc[:,"Tmin"] = df["Tmin"].str.replace("℃","").astype("int32")
#最高温度大于35 ℃
print(df.loc[df['Tmax']>35,:]) #这个会把满足条件的设置成Ture,不满足的设置成False,然后进行筛选
#筛选出自认为舒适的生存环境
print(df.loc[(df['Tmax']>35)&(df['Tmin']<25) &(df['TQ']=='晴'),:])
#4.调用函数进行查询,看着很高大上
#lambda简单函数用这个
print(df.loc[lambda df:(df['Tmax']>35)&(df['Tmin']<25) &(df['TQ']=='晴'),:])
#复杂的用这个
def my_fun(df):
return df.index.str.startswith('2019-09')&(df['Tmin']>=17)
print(df.loc[my_fun,:])
②.筛选数据也可以用iloc函数(按数字区间查询),没兴趣可以先不看:
#======================================查询数据iloc========
#df.iloc根据行列数字位置进行查询
#1.打印规定的行列:#打印10~20行前三列数据
print(df.iloc[10:20,0:3])
#2.提取不连续行和列的数据,这个例子提取的是第1,3,5行,第2,4列的数据
print(df.iloc[[1,3,5],[2,4]])
#3.专门提取某一个数据,这个例子提取的是第三行,第二列数据(默认从0开始算哈)
print(df.iloc[2,1])
#4.选取第0行1列的元素
print(df.iloc[0,1])
#5.选取第2到第3行
print(df.iloc[2:4])
#6.选取第3行
print(df.iloc[3])
③.筛选数据也可以不加函数,神奇吧,也是科普,感兴趣看不感兴趣往下(里面有一些我觉的好的方法,可以学习一下):
#===================字段筛选================================
#1.数据转换,不喜欢空格,逗号,横杠都可以替换掉:
df.loc[:,"ymd"] = df["ymd"].str.replace(" 星期一","")
df.loc[:,"ymd"] = df["ymd"].str.replace(" 星期二","")
df.loc[:,"ymd"] = df["ymd"].str.replace(" 星期三","")
df.loc[:,"ymd"] = df["ymd"].str.replace(" 星期四","")
df.loc[:,"ymd"] = df["ymd"].str.replace(" 星期五","")
df.loc[:,"ymd"] = df["ymd"].str.replace(" 星期六","")
df.loc[:,"ymd"] = df["ymd"].str.replace(" 星期日","")
# 2.设置索引为日期,方便后续的数据筛选(没设置可能就是0-xxx,很重要)
df.set_index('ymd',inplace=True)
print(df.index)
#3.把温度数据℃去掉,并转换成int类型,方便后续处理
df.loc[:,"Tmax"] = df["Tmax"].str.replace("℃","").astype("int32")
df.loc[:,"Tmin"] = df["Tmin"].str.replace("℃","").astype("int32")
# 筛选数据:
#1.筛选最高温度大于20的数据
print(df[df.Tmax>20])
#2.筛选最高温度大于20且最低温度小于4的数据
print(df[(df.Tmax>20)&(df.Tmin<5)])
#3.筛选最高温度大于20或最低温度小于4的数据
print(df[(df.Tmax>20)|(df.Tmin<5)])
#4.控制显示的字段
print(df[['Tmax','Tmin']][(df.Tmax>7)|(df.Tmin<5)])
#5.描述性统计
print(df.describe())
d.聚合函数:
聚合函数也是挺常用的,最大最小,求和,平均等等:
#======聚合函数=====================用作统计===
#1. 一下子提取所有数据统计结果:对数字有效果
print(df.describe())
#2.读取数据的均值,最大值,最小值
print(df["Tmax"].mean())
print(df["Tmax"].max())
print(df["Tmax"].min())
#3.唯一去重和按值计数==========
print(df["TQ"].unique()) #去重
print(df["TQ"].value_counts())#计数
#4.数据排序:升序排列
print(df.sort_values(by='Tmax'))#排序
print(df.T)# 数据转置
#5.相关系数和协方差=========
# ①.协方差矩阵:判断同向反向程度
print(df["Tmax"].cov(df["Tmin"]))
# ②.相关系数矩阵:判断两个指标相关性,相似性
print(df["Tmax"].corr(df["Tmin"]))
e.新增数据:
当我们用完聚合函数的时候就会想加入自己的数据表里面,那新增数据就不得不接触一下,别害怕,不难:
#==================新增数据=======新增加列,用作数据分析=======
# 1.直接添加数据:
df.loc[:,"wencha"]= df["Tmax"]-df["Tmin"]
print(df)
# 2.apply方法加入数据:
def get_wendu_type(df):
if df["Tmax"] > 33:
return "高温"
elif df["Tmin"] < -10:
return "低温"
else:
return "常温"
df.loc[:,"wendu_type"] = df.apply(get_wendu_type,axis=1)
print(df["wendu_type"].value_counts())
#3.assign一次添加多列========(他并不会自动修改原df,需要重新赋值):
df=df.assign(
Tmax_huashi = lambda x:df["Tmax"]*9/5+32,
Tmin_huashi=lambda x: df["Tmin"]*9/5+32
)
print(df)
#4.按条件选择分组分别赋值:
df["wendu_type"] = ''
df.loc[df["Tmax"] - df["Tmin"] >10,"wendu_type"] = "温差大"
df.loc[df["Tmax"] - df["Tmin"] <=10,"wendu_type"] = "温差小"
print(df["wendu_type"].value_counts())
print(df)
学完上面的就能解决工作中的一部分问题了,比如以前数据需要手动处理,自从学完上面的知识,悟道了,效率噌噌的:
f.缺失值的处理 方法,包含删除操作呦:
有时候我们拿到的数据并不会那么完美,有异常值,缺失值等等,这时候为了分析没有杂波,就需要稍微处理一下,不多的话,删除不影响那就删除,波动不大的可以插入个平均值,或者按照自己想法插入等等:
# ======================================缺失值的处理办法======
#1.增加一列空数据:空格并不是空值*********************
df.loc[:,"type"]= np.nan
df.loc["type",:] = np.nan
df.loc["2019-01-05 ","type"] = 2
print(df)
#2.第一步是判断
print(df["type"].isnull())
print(df["type"].notnull())
#筛选出非空的所有值
print(df.loc[df["type"].notnull(),:])
# 2.第二步处理:删除dropna或者增加/替换:fillna
# 删除全是空值的列
df.dropna(axis='columns',how = 'any',inplace=True)
print(df)
# 删除全是空值的行
print(df.dropna(axis='index',how = 'all',inplace=True))
print(df)
#删除某一行或者列
#行删除:
print(df.drop(['ymd']))
#列删除:
print(df.drop(['ymd'], axis = 1))#drop函数默认删除行,列需要加axis = 1
df.drop('ymd',axis=1, inplace=True) #inplace 就是不必赋值,直接替换
df.drop([df.columns[[0,1,3]]], axis=1, inplace=True)
#3.用自己选定的值进行补充,也可以是平均值:都是对列进行修改的
df.fillna({"type":0})
df.loc[:,"type"] = df.fillna(0)
print(df.fillna({"type":0}))
# 用前面的有效值进行填充
df.loc[:,"type"] = df["type"].fillna(method="ffill")
print(df)
#用后一个数据代替缺失值
print (df["type"].fillna(method='bfill'))
来个实例帮助理解一下:
#一个实际的例子,帮助理解============================
#创建一个6*4的数据框,randn函数用于创建随机数
czf_data = pd.DataFrame(np.random.randn(6,4),columns=list('ABCD'))
#把第二行数据设置为缺失值
czf_data.iloc[2,:]=np.nan #czf_data.ix[2,:]=np.nan ix已经被弃用
print(czf_data)
#接着就可以利用插值法填补空缺值了~
print (czf_data.interpolate())
g.数据分组: 分组真的很重要,当我们要看下相同类别的个数的时候,就可以分组,很多场景都是适用的:
#==================================数据分组:先分组再聚合============================================================
# #把温度数据℃去掉,并转换成int类型,方便后续处理
#1.按TQ这一列进行分组:数值列会进行求和,做数据分析还是有用的
group1 = df.groupby('TQ').sum()
group2 = df.groupby('TQ').mean()
group3 = df.groupby('TQ').max()
group4 = df.groupby('TQ').min()
print(group1,group2,group3,group4)
#2,多个参数查询:
group=df.groupby("TQ").agg([np.sum,np.mean,np.max,np.min,np.std])
print(group)
group=df.groupby("TQ").agg([np.sum,np.mean,np.max,np.min,np.std])["Tmax"]
print(group)
group=df.groupby("TQ").agg({"Tmax":np.sum,"Tmin":np.sum})
print(group)
h.数据合并:
当我们数据记录在两个不同表格中,有时候需要合并观察或者分析的时候就用到了合并,只要数据对应,非常方便:
#========================怎么实现dataframe:合并呀========
#1,merge:
#merge:left,right:左右的数据,待合并数据;left_on,right_on:合并的依据,左右最好相同,没有就自己插入一个1列或者0列,相同即可;how:后面跟的就是合并方式,左右链接,外连接,内连接。
df_data = pd.merge(left,reight,left_on = "",right_on="",how = left/right/outer/inner)
#2.concat:批量合并相同格式的数据:
pd.concat(objs = libiao,axis = 0/1,join = "outer/inner",ignore_index=False/True)
#3.append()
df.append(other,ignore_index = False) #只有按行合并,还是比较常用的
i.数据转换函数:
有时候数据记录的并不直观,我们需要转换成我们熟悉的样子,那么就需要数据转换了:
#========================pandas的数据转换函数=======================
# map:只用于series的处理;
# apply:用于series实现单个值的处理,用于dataframe实现series的处理;
# applymap:用于实现dataframe单个值的处理
dict_duiying = {"雨":"不开心","晴":"开心","多云":1,"阴":2,"雾":np.nan,"雨夹雪":1,"扬沙":2,"小雨":np.nan,"浮尘":1,"小雪":2,"霾":np.nan} #想要转换的数据
a=df["TQ"].map(dict_duiying)
print(a)
group=df.apply(lambda df:dict_duiying[df["TQ"]],axis=1)
print(group)
sun = df[["Tmax","Tmin"]]
print(sun.applymap(lambda x:x+100))
注:lambda用法详解:
lambda
j.日期处理函数:贼强大:
#====日期数据的一些方法to_datetime========变更格式后有利于利用时间函数=======
date_cc=df.set_index(pd.to_datetime(df["ymd"]),inplace=True) #转换函数:日期转换to_datetime
#1.loc函数可以随便使用,年月日怎么喜欢怎么来,机动性更强
print(df.loc["2019-01-19"])
print(df.loc["2019-01-19":"2019-03-09"])
print(df.loc["2019-01"])
print(df.loc["2019-01":"2019-03"])
print(df.loc["2019"])
#2.年月日筛选函数:
print(df.index.week)
print(df.index.month)
print(df.index.quarter)
# a=df.groupby(df.index.week)["Tmax"].sum()
a=df.groupby(df.index.month)["Tmax"].sum()
a.plot()
plt.show()
#日期索引不连续了怎么办?
#1.将df的索引变成日期索引:
date_cc=df.set_index(pd.to_datetime(df["ymd"]),inplace=True)
#2.生成完整的日期序列,并执行填充
pdatas = pd.date_range(start = "****",end="****")
df_data_new = date_cc.reindex(pdatas,fill_value=0)
#还有办法:(后续验证)
#1.将df的索引变成日期索引:改变采样频率,实现缺失值的忽略
date_cc=df.set_index(pd.to_datetime(df["ymd"]),inplace=True).drop(pdatas,axis=1)
date_cc.resample("2D").mean
k.数据透视::
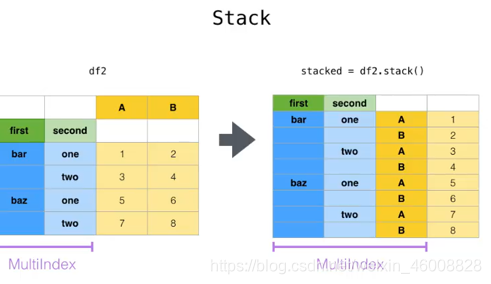
#1.stack(堆叠) :旋转或将列中的数据透视到行;column变成index
import pandas as pd
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
print(df)
'''
结果:
foo bar baz zoo
0 one A 1 x
1 one B 2 y
2 one C 3 z
3 two A 4 q
4 two B 5 w
5 two C 6 t
'''
#1.stack(堆叠) :旋转或将列中的数据透视到行;column变成index
# df.set_index(df["bar"],inplace=True)
print(df.stack(level=-1,dropna=True)) #level=-1代表多层索引的最后一层
示意图:
#2.unstack(拆堆):将行中的数据透视到列;index变成column
import pandas as pd
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
print(df)
'''
结果:
foo bar baz zoo
0 one A 1 x
1 one B 2 y
2 one C 3 z
3 two A 4 q
4 two B 5 w
5 two C 6 t
'''
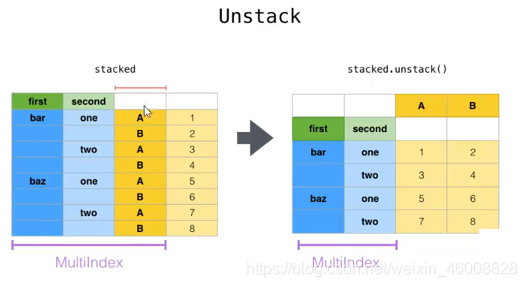
#2.unstack(拆堆):将行中的数据透视到列;index变成column
print(df.unstack(level=-1,fill_value=True)) #level=-1代表多层索引的最后一层
示意图:
#3.pivot()方法是指定相应的列分别作为行标签和列标签,并指定相应的列作为值:
import pandas as pd
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
print(df)
'''
结果:
foo bar baz zoo
0 one A 1 x
1 one B 2 y
2 one C 3 z
3 two A 4 q
4 two B 5 w
5 two C 6 t
'''
#3.pivot()方法是指定相应的列分别作为行标签和列标签,并指定相应的列作为值,
# 然后重新生成一个新的DataFrame对象,这样的好处是使得数据更加的直观和容易分析,俗称数据透视;
# "bar","foo","baz":参数:分别为行索引,列索引,透视的值;
'''
这里有三个参数,作用分别是:
index:新 df 的索引行,用于分组,如果为None,则使用现有索引
columns:新 df 的列,如果透视后有重复值会报错
values:用于填充 df 的列。 如果未指定,将使用所有剩余的列,并且结果将具有按层次结构索引的列
'''
print(df.pivot("bar","foo","baz"))
示意图:
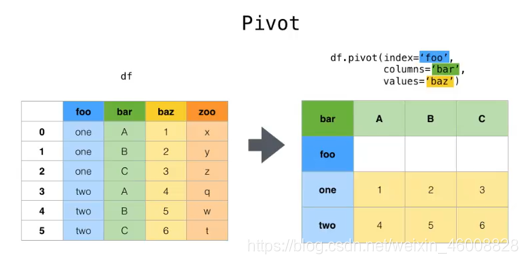
#4.pd.pivot_table()与pivot()基本类似,只是增加了聚合功能。
import pandas as pd
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
print(df)
'''
结果:
foo bar baz zoo
0 one A 1 x
1 one B 2 y
2 one C 3 z
3 two A 4 q
4 two B 5 w
5 two C 6 t
'''
#4.df.pivot()只能将数据进行整理,如果遇到重复值要进行聚合计算;
# 就要用到pd.pivot_table()。它可以实现类似 Excel 那样的高级数据透视功能。
import numpy as np
'''
一些参数介绍:
df: 要透视的 DataFrame 对象
index: 在数据透视表索引上进行分组的键
values: 要聚合的列或者多个列
columns: 在数据透视表列上进行分组的键
aggfunc: 用于聚合的函数, 默认是 numpy.mean
'''
#汇总边际,给列的每层加一个 all 列进行汇总,计算方式与 aggfunc 相同。
result1 = pd.pivot_table(df,index="bar",columns="foo",values="baz",aggfunc=np.sum,margins=True)
#相同及不同值使用不同的聚合计算方式:
result2 = pd.pivot_table(df, values=['baz'], index=['bar'],columns=["foo"],aggfunc={'baz':[min,max,np.mean]})
print(result1,result2)
l.工作中的实例:
数据:模组循环寿命数据(excle数据很大需要分割,要不处理很慢,很容易卡死,四五百兆那种):
数据位置:模组循环数据

代码实例:
#coding = gb2312
'''
#E442 Module循环测试数据整理
'''
import pandas as pd
import os
import numpy
dfs = []
#1.打开文件:\
path = "G:\\2.循环性能测试\\M02\\9.161-180圈\\" #路径根据自己的实例来
for frame in os.listdir(path):
if frame.endswith(".xlsx"): #查找后缀是这个的文件,可变,加上更灵活了
# print(path + frame)
df = pd.read_excel(path+frame,sheet_name="TestData")
df.loc[:,"Tmax"] = df.loc[:,"Channel1_T01":"Channel1_T15"].max(axis=1)
df.loc[:,"Tmin"] = df.loc[:,"Channel1_T01":"Channel1_T15"].min(axis=1)
df.loc[:,"Vmax"] = df.loc[:,"Channel1_V01":"Channel1_V15"].max(axis=1)
df.loc[:,"Vmin"] = df.loc[:,"Channel1_V01":"Channel1_V15"].min(axis=1)
df = df[["循环号", "工步名称","功率(kW)","工步充电容量(Ah)","工步充电能量(kWh)", "工步放电容量(Ah)","工步放电能量(kWh)","Tmax", "Tmin","Vmax", "Vmin"]]
# df.set_index("循环号",inplace=True,drop=False) #inplace = True:不创建新的对象,直接对原始对象进行修改;inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果
cc_data = df.sort_values(by = ["Vmax"],ascending=False,axis=0) #ascending=True升序,axis=0纵向排列;注意
cc_data = cc_data.iloc[0:20,:]
cc_data = cc_data.sort_values(by = ["循环号"],ascending=True)
cc_data = cc_data[["循环号", "工步名称","工步充电容量(Ah)","工步充电能量(kWh)","Tmax", "Tmin","Vmax", "Vmin"]]
dc_data = df.sort_values(by=["Vmin"], ascending=True,axis=0)
dc_data = dc_data.iloc[0:20, :]
dc_data = dc_data.sort_values(by=["循环号"], ascending=True)
dc_data = dc_data[["循环号", "工步名称","工步放电容量(Ah)","工步放电能量(kWh)","Tmax", "Tmin","Vmax","Vmin"]]
result = pd.merge(left=cc_data,right=dc_data,left_on="循环号",right_on="循环号")
# print(cc_data)
# print(dc_data)
result.to_excel("./final1.xlsx",index=False)
print(result)
以上包含了pandas大部分的使用方法,虽然我代码已经放在这了,但是你想学会至少仔细学习一遍,仔细打一遍,再仔细分析一边,前路漫漫,前方等你。
增加的pandas分析层次的一些知识,做备忘,不想看可以直接numpy:
'''
BI:商业智能(Business Intelligence,简称:BI),又称商业智慧或商务智能,指用现代数据仓库技术、线上分析处理技术、
数据挖掘和数据展现技术进行数据分析以实现商业价值。
BI选型:整体功能模块、数据管理模式和分析结果分析模块;
数据分析的层次:
1.描述性分析(了解业务场景:报表/BI:嵌入各种系统中:CRM,SRM,ERR,WMS,MES);、
对已经发生的事用数据准确的描述,不要带有主观臆测;
2.诊断性分析(形成初步思路及目标,收集数据,选择相应方式:);要弄清楚为什么会发生;
(a.对数据位置探索:包括最大值,最小值,均值,中位数,分位数;
b.对数据分布探索:包括偏差,方差,标准差,茎叶图,直方图,箱型图(盒图),密度图等;
c.对数据趋势探索:包括:同比,环比,趋势图,条形图;
)
3.预测性分析;发现规律后,我们要预测这个事情的发生会产生的影响;
(定性分析:寻找相关特征,相关性分析:包括二维散点图,矩阵散点图
定量分析:特征选择,建立模型:回归,分类;
)
4.处方性分析;根据之前找到的原因,给出解决办法,防止情况再次发生,事前采取措施;
(预测性分析给出方案,仿真:建模,验证不同参数的影响,最优化结果)
数据分析的几个方法:
1.行业分析:PEST分析方法;
2.公司整体经营情况:4P营销理论;
3.财务分析:杜邦分析方法;
4.用户行为分析/产品运营:AARRR漏斗模型或者FRM模型;
5.业务面试题:逻辑树分析方法;
excle单表行列限制:行数1048576,列数16384;
'''
#1.pandas 的基本操作
import pandas as pd
df = pd.DataFrame({"ID":[1,2,3],"Name":["Tim","Victor","Nick"]})
##df.set_index(df["ID"],inplace=True)
df.to_excel("./test.xlsx")
# print(df.shape,"\n"
# ,df.columns,"\n"
# ,df.index,"\n"
# ,df.info(),"\n"
# ,df.describe(),"\n"
# ,df.head(n=2),"\n"
# ,df.tail(n=1))
#读取文件:
'''
参数:
#header=0 定义是否存在头,可以是数字及None,如果头部上有空格这个参数有意义;
inplace=True:更改后直接替换原文件;
'''
df1 = pd.read_excel("./test.xlsx")
df1.set_index("ID",inplace=True)
df1.columns = ['ID','Name']
print(df1)
d = {"x":100,"y":200}
# S1 = pd.Series(d)
S1 = pd.Series([100,200],index=[1,2],name="A")
print(S1)
L1 = [100,200]
L2 = ["x","y"]
# S2 = pd.Series(L1,index=L2)
S2 = pd.Series(L1,index=[1,2],name="B")
df2 = pd.DataFrame({S1.name:S1,S2.name:S2})
# print(S2)
print(df2)
#使用excle的特点进行数据选择
'''
skiprows=0:跳过多少行数;
usecols="C:D":选取几列;
#header=0 定义是否存在头;
index_col 默认值(index_col = None)——重新设置一列成为index值;index_col=False——重新设置一列成为index值;index_col=0——第一列为index值
dtype={"ID":str}:设置某一列数据类型;
'''
#日期月份更新数据:填充日期序列
def add_month(d,md):
yd = md//12
m = d.month + md%12
if m != 12:
yd += m//12
m = m%12
return date(d.year+yd,m,d.day)
from datetime import date,timedelta
df3 = pd.read_excel("./test.xlsx",skiprows=0,usecols="B:D",index_col=None,dtype={"ID":str})
start = date(2018,1,1)
for i in df3.index:
df3["ID"].at[i] = i+2
df3["Name"].at[i] = df3["Name"][i]if i%2 == 0 else df3["Name"][i]+"Y"
df3["ID"].at[i] = start+timedelta(days=i)
df3["ID"].at[i] = add_month(start,i)
print(df3)
#数据计算:
df4 = pd.read_excel("./test.xlsx",skiprows=0,usecols="B:D",index_col=None)
# for i in range(3):
# df4["Name"].at[i] = df4["ID"].at[i]*df4["ID"].at[i]
df4["kk"] = df4["ID"] + 2
def add_2(x):
return x+2
df4["kk"] = df4["kk"].apply(add_2)
df4["kk"] = df4["ID"].apply(lambda x:x+3)
#sort_values:ascending=[True,False]:True升序,False降序;
df4.sort_values(by=["ID","kk"],inplace=True,ascending=[False,True])
#去重:
# df4.loc[:,"kk"] = [1,2,2]
# df4.drop_duplicates(subset="kk",inplace=True,keep="last")
# print(df4.any())
#数据透视:
df5 = pd.read_excel("./test.xlsx",index_col="ID")
table = df5.transpose()
print(table)
#pivot_table:
import numpy as np
table1 = df4.pivot_table(index="Name",columns="ID",values="kk",aggfunc=np.sum)
print(table1)
#合并表格:
dfa = df4.append(df5,ignore_index=True).reset_index(drop = True)
print(dfa)
3.numpy模块:(用到再看也来的及)
a.创建一个数组:
#1.一维数组建立===================================================
a = np.array([1,2,3,4,5]) #创建一维数组
b = np.array(range(1,6))
c = np.arange(2,6)
d = np.arange(12)
print(type(a)) #查看数组数据类型
print(a.dtype)
print(a,b,c,d)
##################################################
#增加一些创建数据的方法:
import numpy as np
'''
1.
numpy.random.randint(low, high=None, size=None, dtype=’l’)
返回随机整数,范围区间为[low,high),包含low,不包含high
参数:low为最小值,high为最大值,size为数组维度大小,dtype为数据类型,默认的数据类型是np.int
high没有填写时,默认生成随机数的范围是[0,low)
'''
y1 = np.random.randint(1,45,20).reshape(4,5)
y2 = np.sin(np.arange(1,20,2))
'''
2.
np.linspace主要用来创建等差数列。
linspace(参数):start : 序列的起始点.stop : 序列的结束点;num : 生成的样本数,默认是50。必须是非负。
endpoint : 如果True,'stop'是最后一个样本。否则,它不包括在内。默认为True。retstep : 如果True,返回 (`samples`, `step`)
'''
y3 = np.linspace(-10,10,num=100)
print(y3)
'''
3.
numpy.random.randn(d0, d1, …, dn)是从标准正态分布中返回一个或多个样本值。
numpy.random.rand(d0, d1, …, dn)的随机样本位于[0, 1)中。
numpy.random.randn(d0,d1,…,dn)
randn函数返回一个或一组样本,具有标准正态分布。
dn表格每个维度
返回值为指定维度的array
'''
y4 = np.random.randn(1000)+2
y5 = np.random.randn(1000)+3
'''
4.
numpy.random.rand(d0,d1,…,dn);rand函数根据给定维度生成[0,1)之间的数据,
包含0,不包含1;dn表格每个维度;返回值为指定维度的array
'''
y6 = np.random.rand()
'''
5.
np.random.normal()的意思是一个正态分布,numpy.random.normal(loc=0,scale=1e-2,size=shape)
参数loc(float):正态分布的均值,对应着这个分布的中心。loc=0说明这一个以Y轴为对称轴的正态分布,
参数scale(float):正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线越高瘦。
参数size(int 或者整数元组):输出的值赋在shape里,默认为None。
'''
y7 = np.random.normal(1,0,2)
print(y7)
'''
6.
生成[0,1)之间的浮点数
numpy.random.random_sample(size=None)
numpy.random.random(size=None)
numpy.random.ranf(size=None)
numpy.random.sample(size=None)
'''
y8 = np.random.random_sample(20)
print(y8)
'''
7.
numpy.random.choice(a, size=None, replace=True, p=None)
从给定的一维数组中生成随机数
参数: a为一维数组类似数据或整数;size为数组维度;p为数组中的数据出现的概率
a为整数时,对应的一维数组为np.arange(a)
'''
y9 = np.random.choice(np.arange(10), size=10, replace=True, p=None)
y9 = np.sort(y9)
print(y9)
'''
8.
随机种子:
np.random.seed()的作用:使得随机数据可预测。
当我们设置相同的seed,每次生成的随机数相同。如果不设置seed,则每次会生成不同的随机数
'''
np.random.seed(0)
y10 = np.random.randint(1,45,5)
print(y10)
#2.二维数组建立===================================================
a = np.array([[1,2,3],[4,5,6]]) #建立二维数组
b = np.array([[[1,2,3],[4,5,6],[7,8,9]],[[2,2,2],[3,3,3],[4,4,4]]])
c = np.array([random.random() for i in range(10)]) # random.randint(1,10) 产生 1 到 10 的一个整数型随机数 #random.random() # 产生 0 到 1 之间的随机浮点数
d = np.round(c,2) #可以截取数组中小数的位数
print(c,d)
e = np.arange(24).reshape(2,3,4) #改变数组的形状
# f= b.reshape(18)
# f= b.flatten()
f = b.reshape((b.shape[0]*b.shape[1]*b.shape[2],))
print(a.shape, "\n",b.shape)
print(a,"\n",b,"\n",c,d,e,f)
b.数组计算:
#3.数组计算:
#一维数组计算:
a = np.array(range(12))
print(a,a+2,a*2,a-2,a/2,a/0)
b = a*2
print(b,a+b,a*b,a-b,a/b)
#二维数组计算:
t = np.array([1,2,3])
a = np.array([[1,2,3],[4,5,6]]) #建立二维数组
b = a +2
print(a,b,a+b,a-t)
c.数组的切片操作:
#4.数组的切片计算:二维数组,就是对行列的操作
a = np.arange(24).reshape(4,6)
print(a,a[2],a[1,2],a[[1,3,2]],a[0:2,2:4])
#5.改变数组的数值:
a = np.arange(24).reshape(4,6)
#查找到特定数据后赋值:
print(a)
a[:,0] = 3
print(a)
#根据范围查找进行赋值:
a[a<=3] = 0
print(a)
a=np.where(a<11,0,10) #小于11替换为0,否则替换为10
print(a)
a = a.clip(11,13) #小于11替换为11,大于13的替换为13
print(a)
a.astype(float) #可以改变数据类型,nan就是float类型,替换时候数组要更新一下类型
d.数组的切割及行列交换:
#6.数组的拼接及行列的交换:
a = np.arange(24).reshape(4,6)
b = np.arange(20,44).reshape(4,6)
#垂直拼接:
c = np.vstack((a,b))
print(c)
#水平拼接:
d = np.hstack((a,b))
print(d)
#垂直切割:
e = np.vsplit(a,2)
print(e)
#水平切割:
f = np.hsplit(b,2)
print(f)
#数据交换:
print(a)
a[[1,2],:] = a[[2,1],:] #行交换
print(a)
a[:,[1,2]] = a[:,[2,1]] #列交换
print(a)
e.数组的统计学方法:
#8.一些有用的统计学方法:
#inf表示的是无穷大,nan不代表一个数字。
#注意:
#两个nan是不相等的,np.nan != np.nan,利用这个特性可以查看到数组中nan的个数。
#np.count_nonzero(t != t)
#查询,替换:t[np.isnan] = 0,nan和任何值计算都得nan
#创建一个数组:
a = np.arange(24).reshape(4,6)
print(a)
a= a.astype(float)
a[[a==22]] = np.nan
print(a)
#各种统计方法
print(a.max(axis = None)) #min mean
print(a.sum())
print(np.median(a,axis = 0)) #中值
print(np.ptp(a,axis = 0)) #极值
print(a.std(axis = 0)) #标准差
f.密不外传的方法:
#7.一些好用的数组方法:
#首先我们创建一个数组:
a= np.eye(3) #创建对角线为1的正方形数组
print(a)
print(np.argmax(a,axis=0)) #取出行的最大值的列
a[[a==1]] = -1
print(a)
print(np.argmin(a,axis=0)) #取出行的最小值的列
a = np.zeros((3,4))
print(a)
b = np.ones((3,4))
print(b)
c = b[:] #视图操作,c改变,b也会被改变的
c = b #完全不复制操作,改变c b也会随之改变
c = b.copy()
print(c)
c[[c==1]] =-1
4.matplotlib模块:(用到再看也来的及)
设置画布的几种方式(自己试一下,感受感受)
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(16)
y = x*x
#1.直接创建画布:
fig1 = plt.figure(figsize=(10,4),dpi=100) #设置曲线大小及分辨率
plt.plot(x,y)
#2.添加子图的方式:add_subplot
fig3 = plt.figure(figsize=(15,8))
axx1 = fig3.add_subplot(221)
axx2 = fig3.add_subplot(222)
axx3 = fig3.add_subplot(223)
axx4 = fig3.add_subplot(224)
axx1.plot(x,y,color="g")
#3.添加子图的方式:
plt.figure(4)
ax_1 = plt.subplot(121)
ax_2 = plt.subplot(122)
ax_1.plot(x,y,color="r")
#4.创建带子图的画布:subplots
fig2,axes = plt.subplots(ncols=2,nrows=2)
ax1,ax2,ax3,ax4 = axes.ravel()
ax1.plot(x,y)
ax2.plot(x,y)
plt.show()
**plt.plot()实际上会通过plt.gca()获得当前的Axes对象ax,然后再调用ax.plot()方法实现真正的绘图。**
a.折线图plot:不要浮躁,挨个敲一遍,运行一下,有兴趣再改改数据,自己换个花样玩一下
# coding=gb2312 #加入编码格式,否则会报错,这个东西真的有用,不骗人
import matplotlib.pyplot as plt
#设置中文字体
font = {"family":"MicroSoft YaHei","weight":"bold","size":8}
matplotlib.rc("font",**font)
# matplotlib.rc("font",family="MicroSoft YaHei",weight = "bold")
# #1.设置曲线大小:
fig = plt.figure(figsize=(10,4),dpi=100) #设置曲线大小及分辨率
#2.导入数据
x_data = range(12)
y_data = range(10,22)
#3.设置曲线刻度:
plt.xticks(x_data[::1])
plt.yticks(y_data[::1])
#4.绘制曲线:
plt.plot(x_data,y_data)
#5.保存曲线:
plt.savefig("C:\\Users\\86150\\Desktop\\a.png")
#6.显示曲线
plt.show()
#7.刻度调整:=======================================
x = range(2,28,2)
y = [15,13,14,5,17,20,25,26,26,27,22,18,15]
plt.figure(figsize=(10,4),dpi=80)
plt.plot(x,y)
#刻度:
_xtick_labels = [i/2 for i in range(4,49)]
# plt.xticks(range(25,50))
plt.xticks(_xtick_labels)
plt.yticks((range(min(y),max(y)+1)))
plt.show()
#温度显示实例:========================================
import random
x = range(0,120)
y= [random.randint(20,35) for i in range(120)]
plt.figure(figsize=(10,4),dpi=80)
plt.plot(x,y)
#调整x轴的刻度:
_x = list(x)[::10]
_xtick_labels = ["hello,{}".format(i)for i in _x]
plt.xticks(_x,_xtick_labels)
plt.show()
#==========================
import random
import matplotlib
#设置中文字体
font = {"family":"MicroSoft YaHei","weight":"bold","size":8}
matplotlib.rc("font",**font)
# matplotlib.rc("font",family="MicroSoft YaHei",weight = "bold")
#1.数据构建:
x = range(0,120)
y= [random.randint(20,35) for i in range(120)]
#2.设置曲线大小:
plt.figure(figsize=(10,4),dpi=80)
#3.绘制曲线:
plt.plot(x,y)
#4.调整x轴的刻度:
_xtick_labels = ["10点{}分".format(i)for i in range(60) ]
_xtick_labels += ["11点{}分".format(i)for i in range(60)]
plt.xticks(list(x)[::10],_xtick_labels[::10],rotation = 45) #rotation = 45旋转45℃
#5.添加描述信息:
plt.xlabel("时间")
plt.ylabel("温度 单位(℃)")
plt.title("10点到12点每分钟的气温变化情况")
#6.显示曲线:
plt.show()
来个实例:
#统计11-30女朋友个数:
from matplotlib import pyplot as plt
import matplotlib
from matplotlib import font_manager
font = {"family":"MicroSoft YaHei","weight":"bold","size":8}
matplotlib.rc("font",**font)
# my_font = font_manager.FontProperties(fname="C:\\Windows\\Fonts\\Sitka Banner\\Sitka Banner常规")
y = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
x = range(11,31)
#设置图形大小:
plt.figure(figsize=(10,4),dpi = 80)
plt.plot(x,y)
#设置x轴刻度:
_xtick_lables = ["{}岁".format(i) for i in x]
plt.xticks(x,_xtick_lables)
plt.yticks(range(0,9))
#绘制网格:
plt.grid(alpha=0.1)
#展示:
plt.show()
#统计11-30女朋友个数,同桌和你的(一个画布,两条曲线)
from matplotlib import pyplot as plt
import matplotlib
#设置中文显示:
font = {"family":"MicroSoft YaHei","weight":"bold","size":8}
matplotlib.rc("font",**font)
#1.构建数据:
y_1 = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
y_2 = [2,0,3,5,2,4,3,4,3,5,4,1,2,1,2,1,2,1,2,1]
x = range(11,31)
#2.设置图形大小:
plt.figure(figsize=(10,4),dpi = 80)
plt.plot(x,y_1,label="自己",color="#F08080",linestyle="--",linewidth=5,alpha=0.5) #label="自己",color="r",linestyle="--",linewidth=5,alpha=0.5
#3.图例,颜色,线型,线宽,透明度
plt.plot(x,y_2,label="同桌")
#4.设置x轴刻度:
_xtick_lables = ["{}岁".format(i) for i in x]
plt.xticks(x,_xtick_lables)
plt.yticks(range(0,9))
#5.绘制网格:
plt.grid(alpha=0.4)
#6.添加图例:
plt.legend(loc = "upper left")
#7.展示:
plt.show()
b.散点图scatter:可以查看数据的分布情况
# coding=gb2312 #加入编码格式,否则会报错,这个东西真的有用,不骗人
from matplotlib import pyplot as plt
import matplotlib
#设置中文显示:
font = {"family":"MicroSoft YaHei","weight":"bold","size":8}
matplotlib.rc("font",**font)
#1.构建数据:
y_1 = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,23,21]
y_2 = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,22,21,22,21]
x_1 = range(1,32)
x_2 = range(51,82)
#2.设置图形大小:
plt.figure(figsize=(10,4),dpi = 80)
plt.scatter(x_1,y_1,label="3月份") #3.图例,颜色,线型,线宽,透明度
plt.scatter(x_2,y_2,label="10月份")
#4.设置x轴刻度:
_x = list(x_1)+list(x_2)
_xtick_lables = ["3月{}日".format(i) for i in x_1]
_xtick_lables += ["10月{}日".format(i-50) for i in x_2]
plt.xticks(_x[::3],_xtick_lables[::3],rotation=45)
plt.yticks(range(4,30))
#5.绘制网格:
plt.grid(alpha=0.4)
#6.添加图例:
plt.legend(loc = "upper left")
#7.添加描述信息:
plt.xlabel("时间")
plt.ylabel("温度 单位(℃)")
plt.title("3月及10月的气温变化情况")
#8.展示:
plt.show()
c.条形图:横条、竖条,用作对比非常明显
# coding=gb2312 #加入编码格式,否则会报错,这个东西真的有用,不骗人
from matplotlib import pyplot as plt
import matplotlib
#设置中文显示:
font = {"family":"MicroSoft YaHei","weight":"bold","size":8}
matplotlib.rc("font",**font)
#1.构建数据:
a = ["战狼2","速度与激情","功夫瑜伽","西游伏妖篇","变形金刚"]
b = [56.1,26.84,17.53,16.49,15.45]
#2.设置图形大小:
plt.figure(figsize=(10,4),dpi = 80)
#3.绘制曲线:
# plt.bar(range(len(a)),b,width=0.2)
#3.设置x轴刻度:
# plt.xticks(range(len(a)),a,rotation=45)
#4.绘制曲线:
plt.barh(range(len(a)),b,height=0.3,color="orange")
plt.yticks(range(len(a)),a)
#5.绘制网格:
plt.grid(alpha=0.4)
#6.添加描述信息:
plt.xlabel("影片名字")
plt.ylabel("票房")
plt.title("电影票房分布")
#7.展示:
plt.show()
#========================
#1.构建数据:
a = ["猩球崛起3","敦刻尔克","蜘蛛侠","战狼2"]
b_1 = [15746,312,4487,319]
b_2 = [12357,156,2045,168]
b_3 = [2358,399,2358,362]
bar_width = 0.2
x_1 = list(range(len(a)))
x_2 = [i+bar_width for i in x_1]
x_3 = [i+bar_width*2 for i in x_1]
#2.设置图形大小:
plt.figure(figsize=(10,4),dpi = 80)
#3.绘制柱形图:
plt.bar(range(len(a)),b_3,width=bar_width,label="9月14日")
plt.bar(x_2,b_2,width=bar_width,label="9月15日")
plt.bar(x_3,b_3,width=bar_width,label="9月16日")
#4.设置图例:
plt.legend()
#5.设置x轴刻度:
plt.xticks(x_2,a)
plt.show()
d:直方图:
和前面几种绘图最大的区别就是,绘图使用plt.hist(原始数据a,组数[,density=True])函数,并且简单绘图时不需要传x、y轴坐标,只需要传进待绘图的原始连续数据,设置好分组数量,函数会自动将每组数据的个数计算出来,并且绘制到图上。如果使用density=True,则y轴坐标则会由数量变为频率。
1.连续数据绘制直方图时:plt.hist()
2.如果原始数据经过初步整理,组织成不连续的数据,想要仍然达到直方图的目的,则使用条形图绘制,达到与直方图相似的效果
# coding=gb2312 #加入编码格式,否则会报错,这个东西真的有用,不骗人
from matplotlib import pyplot as plt
import matplotlib
#设置中文显示:
font = {"family":"MicroSoft YaHei","weight":"bold","size":8}
matplotlib.rc("font",**font)
#1.构建数据:
a = [131,98,125,131,124,139,131,117,128,108,135,138,131,102,107,114,119,128,121,114,156,132,34,45,32,76,112,34,89,78,97,58,55,124,145,57,90]
#2.计算组数:
d = 3 #组距
num_bins = (max(a)-min(a))//d+1
print(num_bins)
#3.设置图形大小:
plt.figure(figsize=(20,8),dpi=80)
plt.hist(a,num_bins)
#4.设置x轴刻度:
plt.xticks(range(min(a),max(a)+d,d))
#5.绘制网格:
plt.grid()
plt.show()
#数据汇总好的就只能用条形图来做了
#1.数据:
interval = [0,5,10,15,20,25,30,35,40,45,60,90]
width = [5,5,5,5,5,5,5,5,5,15,30,60]
quantity =[836,2737,3723,3926,3596,1438,3273,642,824,613,215,47]
print(len(interval),len(width),len(quantity))
#2.设置画布:
plt.figure(figsize=(20,8),dpi=80)
#3。绘制柱形图:(模拟直方图)
plt.bar(range(12),quantity,width=1)
#4.设置X轴刻度:
_x = [i-0.5 for i in range(13)]
_xtick_labels = interval+[150]
plt.xticks(_x,_xtick_labels)
#5.绘制网格:
plt.grid()
#6.显示:
plt.show()
e:饼图
import matplotlib.pyplot as plt
'''
饼图的绘制:pie
'''
#1.构建数据:
labels = ["A","B","C","D"]
fracs = [15,30,45,10]
#说是调整比例的:
# plt.axes(aspect=2)
#2.绘制饼图:
explode = [0,0.05,0.08,0]
#autopct='%.0f%%'调整显示比例;explode可以让某一块凸显出来;
plt.pie(x=fracs,labels=labels,autopct='%.0f%%',explode=explode)
#3.显示:
plt.show()
f:盒图
'''
箱型图的绘制(又叫盒型图):显示的分别是 上边缘,上四分位数,中位数,下四分位数,下边缘,异常值
'''
import numpy as np
import matplotlib.pyplot as plt
'''
seed( ) 是用于指定随机数生成时所用算法开始的整数值,
代码中每执行一次都使用了相同的随机数种子28,所以生成的随机数是相同的。
'''
np.random.seed(100)
'''
np.random.normal()的意思是一个正态分布;
参数loc(float):正态分布的均值,对应着这个分布的中心。loc=0说明这一个以Y轴为对称轴的正态分布,
参数scale(float):正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线越高瘦。
参数size(int 或者整数元组):输出的值赋在shape里,默认为None。
'''
#1.构建数据:
data = np.random.normal(size=10000,loc=0,scale=0.1)
plt.boxplot(data,sym="o",widths=1.5)
#2.建立多个盒图:
plt.figure(figsize=(15,8),dpi=80)
np.random.seed(100)
data = np.random.normal(size=(10000,4),loc=0,scale=1)
labels = ["A","B","C","D"]
#3.绘制盒图:
plt.boxplot(data,labels=labels)
#4.显示:
plt.show()
g:雷达图
#雷达图:
import numpy as np
import matplotlib.pyplot as plt
# r = np.arange(1,6,1)
#########:
'''
a = np.empty(2)
a.fill(1)
array([1., 1.])
'''
r = np.empty(5)
r.fill(5)
theta = [0,np.pi/2,np.pi,3*np.pi/2,2*np.pi]
ax = plt.subplot(111,projection="polar")
ax.plot(theta,r,color="r",linewidth=3)
ax.grid(True)
plt.show()
h:颜色及形状的探索:
#1.对于颜色的探索:
'''
八种内建默认颜色:b:blue;g:green;r:red;c:cyan;m:magenta;y:yellow;k:black;w:white;
其他方式:灰色阴影,十六进制:#FF00FF RGB(元组):(0.1,0.2,0.3)
'''
import numpy as np
import matplotlib.pyplot as plt
y = np.arange(1,5)
plt.plot(y,color="g")
plt.plot(y+1,color="0.1")
plt.plot(y+2,color="#FF00FF")
plt.plot(y+3,color=(0.3,0.2,0.3))
plt.show()
#2.对点线的样式的探索:
'''
点的形状:. , o v ^ < > 1 2 3 4 8 s p * h H + x D d | _
线的形状:- -- -. :
'''
import numpy as np
import matplotlib.pyplot as plt
y = np.arange(1,5)
plt.plot(y,color="g",marker="o",linestyle="--",linewidth=5,alpha=0.5)
plt.plot(y+1,color="0.1",marker="D",linestyle="-",linewidth=5,alpha=0.5)
plt.plot(y+2,color="#FF00FF",marker="*",linestyle="-.",linewidth=5,alpha=0.5)
plt.plot(y+3,color=(0.3,0.2,0.3),marker="p",linestyle=":",linewidth=5,alpha=0.5)
plt.show()
i:曲线的深入探索:
#1.一图双轴:
import numpy as np
import matplotlib.pyplot as plt
# 创建模拟数据
t = np.arange(0.01, 10.0, 0.01)
#高等数学里以自然常数e为底的指数函数
data1 = np.exp(t)
data2 = np.sin(2 * np.pi * t)
fig, ax1 = plt.subplots()
color = 'tab:red'
ax1.set_xlabel('time (s)')
ax1.set_ylabel('exp', color=color)
ax1.plot(t, data1, color=color)
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx() # 创建共用x轴的第二个y轴
color = 'tab:blue'
ax2.set_ylabel('sin', color=color)
ax2.plot(t, data2, color=color)
ax2.tick_params(axis='y', labelcolor=color)
#tight_layout会自动调整子图参数,使之填充整个图像区域。
fig.tight_layout()
plt.show()
#2.添加注释及文字:
'''
annotate:添加注释
text:可以添加文字及公式(很智能的)
'''
import matplotlib.pyplot as plt
import numpy as np
plt.style.use("ggplot") #智能美化
a = np.linspace(-10,10,num=100)
b = a**2
plt.plot(a,b)
#添加注释:
plt.annotate("this is the bottom",xy=(0,1),xytext=(0,20),arrowprops=dict(facecolor="r",frac=0.2,headwidth=30,width=20))
#添加文字:
plt.text(-2,40,"function:y=x*x",family="serif",style="oblique",weight="black")
plt.text(-2,30,"function:y=x*x",family="sans-serif",size=20,color="r",style="italic",weight="light")
plt.show()
#3.颜色填充演示:
import matplotlib.pyplot as plt
import numpy as np
# x = np.arange(0,17,0.1)
# y1 = np.sin(x)
# y2 = np.sin(2*x)
#
# plt.plot(x,y1)
# plt.plot(x,y2)
#
# #填充:
# plt.fill(x,y1,"b",alpha=0.3)
# plt.fill(x,y2,"r",alpha=0.3)
# plt.show()
x = np.arange(0,17,0.1)
y1 = np.sin(x)
y2 = np.sin(2*x)
fig = plt.figure()
ax = fig.gca()
ax.plot(x,y1,x,y2,color="black")
# ax.fill_between(x,y1,y2,facecolor="blue")
ax.fill_between(x,y1,y2,where=y1>y2,facecolor="blue",interpolate=True)
ax.fill_between(x,y1,y2,where=y1<y2,facecolor="red",interpolate=True)
plt.show()
#4.生成形状:
import matplotlib.patches as mpatches
import matplotlib.pyplot as plt
import numpy as np
fig,ax = plt.subplots()
xy1 = np.array([0.2,0.2])
xy2 = np.array([0.2,0.8])
xy3 = np.array([0.8,0.2])
xy4 = np.array([0.8,0.8])
circle = mpatches.Circle(xy1,0.1,color="b")
ax.add_patch(circle)
rect = mpatches.Rectangle(xy2,0.2,0.1,color="r")
ax.add_patch(rect)
polygon = mpatches.RegularPolygon(xy3,5,0.1,color="g")
ax.add_patch(polygon)
ellipse = mpatches.Ellipse(xy4,0.4,0.2,color="y")
ax.add_patch(ellipse)
plt.axis("equal")
plt.grid()
plt.show()
#5.图形美化:
import matplotlib.pyplot as plt
import numpy as np
#图形美化:开头加入这个语句
plt.style.use("ggplot") #可以用plt.style.available查出可用样式列表
以上就是对matplotlib的简单介绍,如果绘图要求不复杂,以上知识点足矣,学无止境,不断的实战才能锤炼出好的本领,没有捷径,就是敲敲敲,,,,,,,,,,,,,
拖延症有时候真的是能毁掉一个人的人生,为什么拖延,因为改变往往是充满着未知,在我们心中也是充满着困难与恐惧;虽然我曾心中坚定过要坚持,但是塞尔达真的比看学习视频安逸的多,我不保证不沉迷,但是要懂得停下。
有些事你真的去做的时候发现,没那么轻松,但也不至于害怕。很多人劝我不要异想天开,涉足未知的领域有多困难,但是只有我真正知道我需要什么,虽然前人有前人的经验,但我们也应该有我们的坚持。生命的尽头不会觉得因为没有尝试而悔恨,那就够了,毕竟你的人生你能保证的只有脑子驱动身体,身体追逐灵魂。
就这样吧,
#持续更新,,,,,,,,,,,


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









