







 本文深入分析了LinkedList的数据结构和核心操作实现,包括节点追加、删除、查询等关键方法,并探讨了其高效的迭代器实现。
本文深入分析了LinkedList的数据结构和核心操作实现,包括节点追加、删除、查询等关键方法,并探讨了其高效的迭代器实现。
LinkedList 源码解析
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
提示:以下是本篇文章正文内容,下面案例可供参考
一、引导语
LinkedList适用于集合元素先进先出和先入后出的场景。
二、整体构架
LinkedList底层数据结构是一个双向链表,整体结构如下如图:
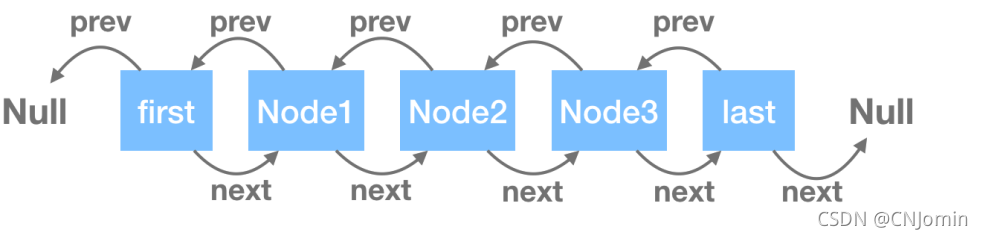
- 链表中每个节点叫Node,Node有Pre属性,代表前一个节点的位置,next属性代表后一个节点的属性。
- first是双向链表的头结点,他的前一个节点是null
- last是双向链表的尾结点,后一个节点是null
- 当链表中没有数据时,first和last是同一个节点,前后都是指向null
- 双向链表,没有存储限制
1.Node的组成部分
Node<E> next; // 指向的下一个节点
Node<E> prev; // 指向的前一个节点
// 初始化参数顺序分别是:前一个节点、本身节点值、后一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
二、源码分析
1.追加(新增)
追加节点时,可以向投不添加也可以向尾部添加。add()方法是向默认向尾部添加的,addfirst方法是向头部开始添加的,我们看看两种不同的添加方式
1.1 从尾部开始添加
// 从尾部开始追加节点
void linkLast(E e) {
// 把尾节点数据暂存
final Node<E> l = last;
// 新建新的节点,初始化入参含义:
// l 是新节点的前一个节点,当前值是尾节点值
// e 表示当前新增节点,当前新增节点后一个节点是 null
final Node<E> newNode = new Node<>(l, e, null);
// 新建节点追加到尾部
last = newNode;
//如果链表为空(l 是尾节点,尾节点为空,链表即空),头部和尾部是同一个节点,都是新建的节
if (l == null)
first = newNode;
//否则把前尾节点的下一个节点,指向当前尾节点。
else
l.next = newNode;
//大小和版本更改
size++;
modCount++;
}
1.2 从头部开始添加
代码如下(示例):
头部追加节点和尾部和加上节点非常相似,只是移动头结点的prev指向,后者是移动尾结点的next指向。
// 头节点赋值给临时变量
final Node<E> f = first;
// 新建节点,前一个节点指向null,e 是新建节点,f 是新建节点的下一个节点,目前值是头节点的
final Node<E> newNode = new Node<>(null, e, f);
// 新建节点成为头节点
first = newNode;
// 头节点为空,就是链表为空,头尾节点是一个节点
if (f == null)
last = newNode;
//上一个头节点的前一个节点指向当前节点
else
f.prev = newNode;
size++;
modCount++;
}
2 节点删除
节点删除和节点添加方法类似,我们可以选择从头部开始删除,也可以选择从尾部删除,删除操作会把节点的值,前后指向节点都置为null,帮助GC回收
1.1从头部删除
//从头删除节点 f 是链表头节点
private E unlinkFirst(Node<E> f) {
// 拿出头节点的值,作为方法的返回值
final E element = f.item;
// 拿出头节点的下一个节点
final Node<E> next = f.next;
//帮助 GC 回收头节点
f.item = null;
f.next = null;
// 头节点的下一个节点成为头节点
first = next;
//如果 next 为空,表明链表为空
if (next == null)
last = null;
//链表不为空,头节点的前一个节点指向 null
else
next.prev = null;
//修改链表大小和版本
size--;
modCount++;
return element;
}
从源码中我们可以了解到,链表结构的节点新增、删除都非常简单,仅仅把前后节点的指向修改
下就好了,所以 LinkedList 新增和删除速度很快。
3 节点查询
// 根据链表索引位置查询节点
Node<E> node(int index) {
// 如果 index 处于队列的前半部分,从头开始找,size >> 1 是 size 除以 2 的意思。
if (index < (size >> 1)) {
Node<E> x = first;
// 直到 for 循环到 index 的前一个 node 停止
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {// 如果 index 处于队列的后半部分,从尾开始找
Node<E> x = last;
// 直到 for 循环到 index 的后一个 node 停止
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
从源码中可以看到,LinkedList并没有采用从头到尾的做法,而是采用了简单的二分法的方式,首先看看index是在链表的前半部分还是后半部分,通过遍历找到对应节点的下一个元素或者上一个元素。这样循环次数至少减少了一半。
4 迭代器
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









