







创建一个形状为(2,3,4)的张量,所有元素设置为1

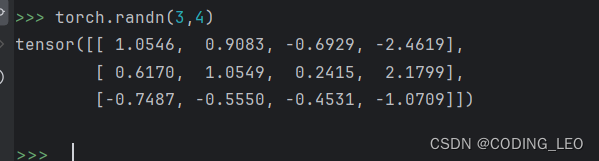
一个形状为(3 ,4)的张量,其中每个元素从均值为0,标准差为1的标准高斯分布(正态分布)中随机采样
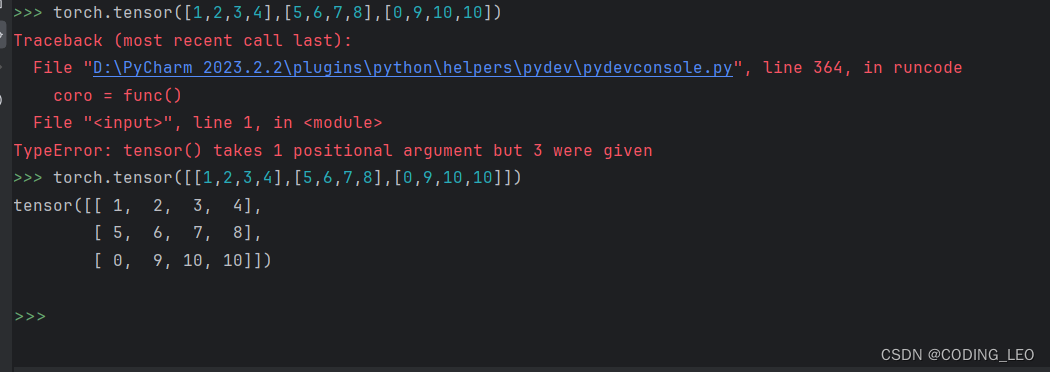
还可以通过提供保函数值的python列表(或嵌套列表),来为张量赋值,外侧列表对应轴0,内侧列表对应轴1
运算符计算
**运算符是求幂运算
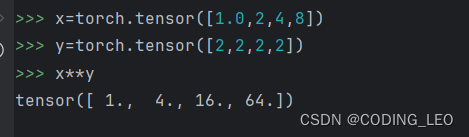
按元素方式可以应用更多运算,包括求幂这样的一元运算符

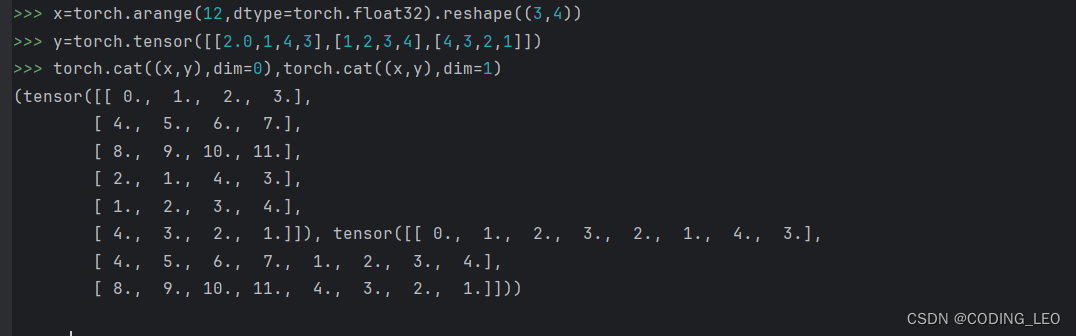
把多个张量连接在一起
dim轴为0是按行,轴为1是按列
张量中元素可以通过索引来访问,第一个元素索引为0,最后一个索引为-1,【1:3】是选择第二个和第三个元素

还可以通过指定索引来将元素写入矩阵
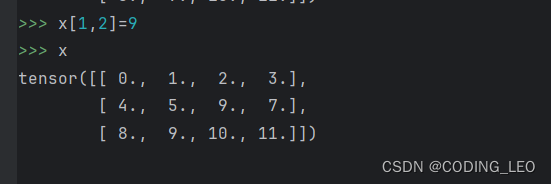
为多个元素赋予相同的值,【0:2,:】表示访问第一行和第二行,其中:表示沿轴1(列)的所有元素

节省内存,执行原地操作, 可以使用切片表示法将操作的结果分配给先前分配的数组,例如
我们创建一个新矩阵z,其形状和y相同,使用zeros_like来分配个全0的块
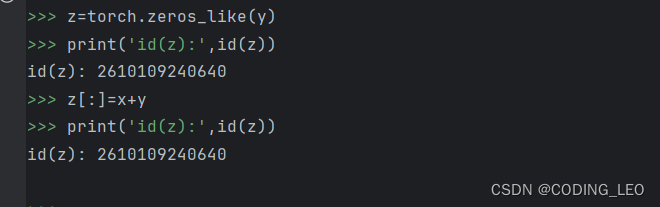
如果在后续计算中没有用到x,我们可以使用x【:】=x+y或x+=用来减少操作的内存开销

举一个例子,我们首先创建一个人工数据集,并存储在CSV(逗号分隔值)文件 ../data/house_tiny.csv中。 以其他格式存储的数据也可以通过类似的方式进行处理。 下面我们将数据集按行写入CSV文件中。
要从创建的CSV文件中加载原始数据集,我们导入pandas包并调用read_csv函数。该数据集有四行三列。其中每行描述了房间数量(“NumRooms”)、巷子类型(“Alley”)和房屋价格(“Price”)。
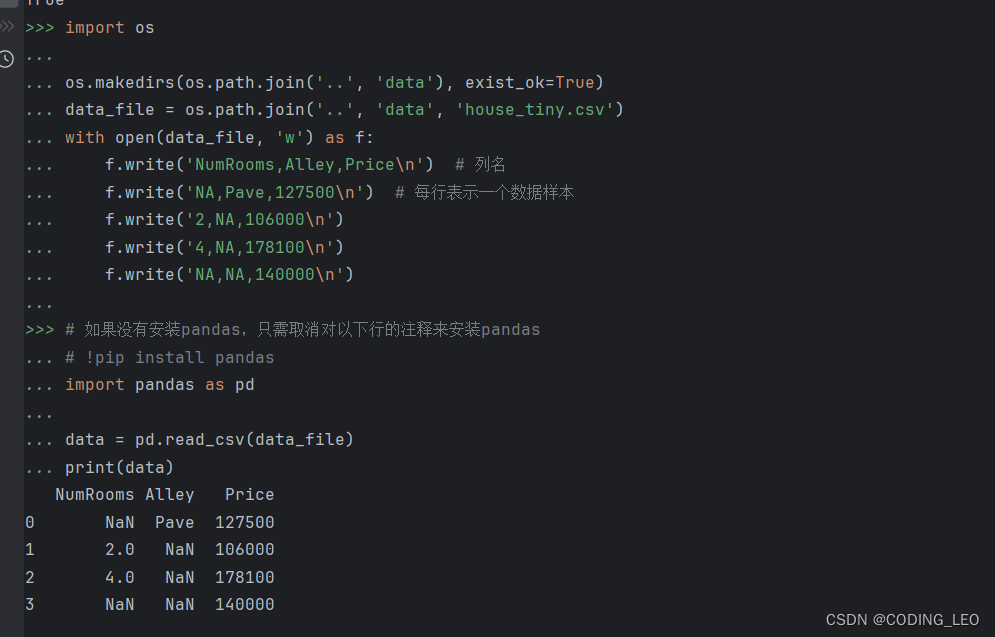
“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在这里,我们将考虑插值法。
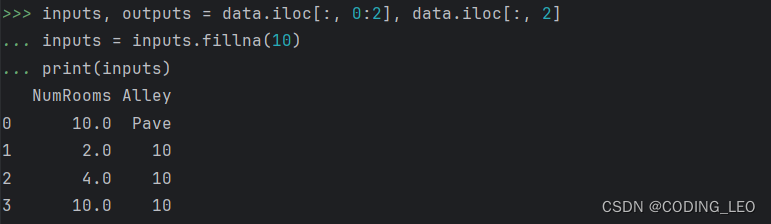
通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
报错

后将缺少值改为10可以
 查找后:
查找后:
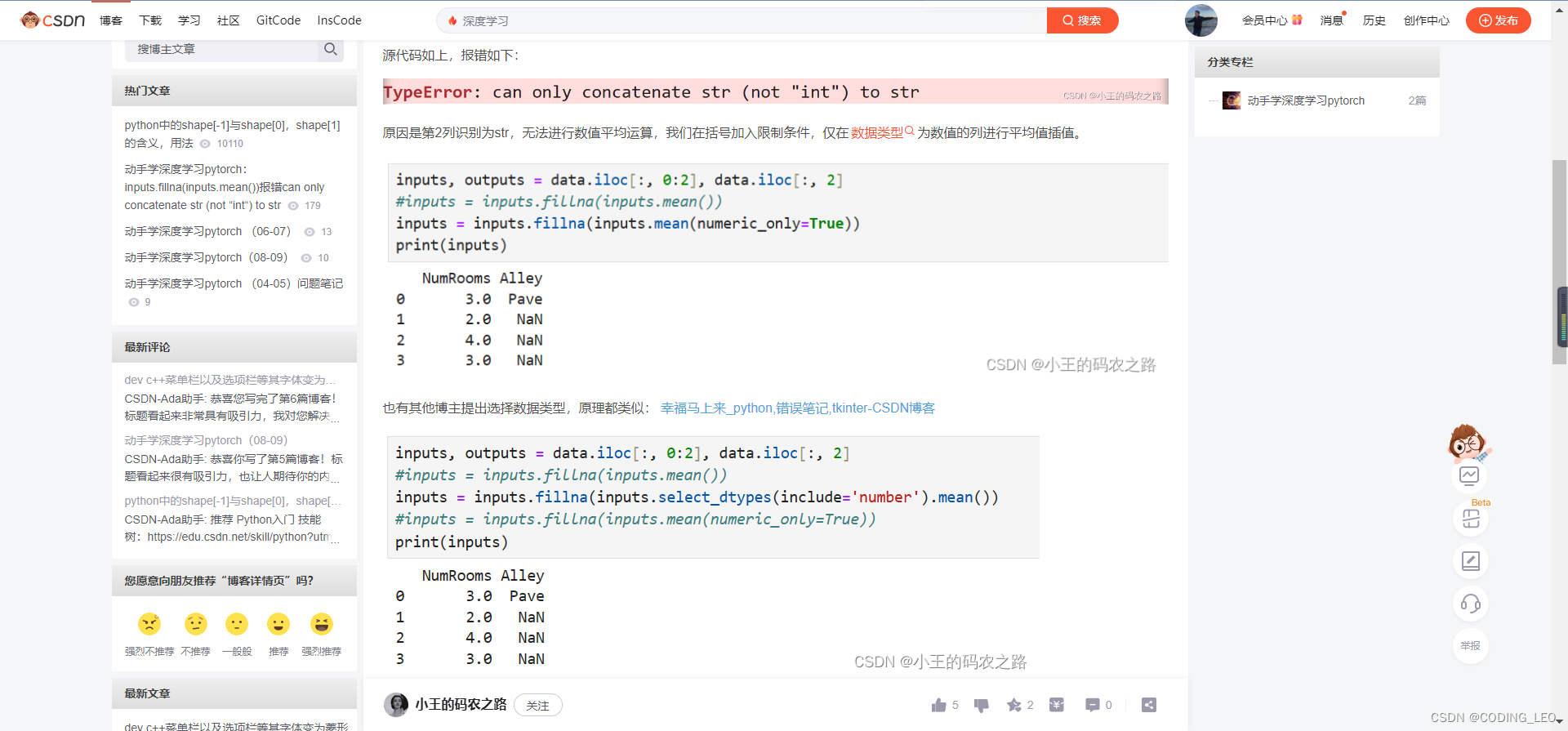
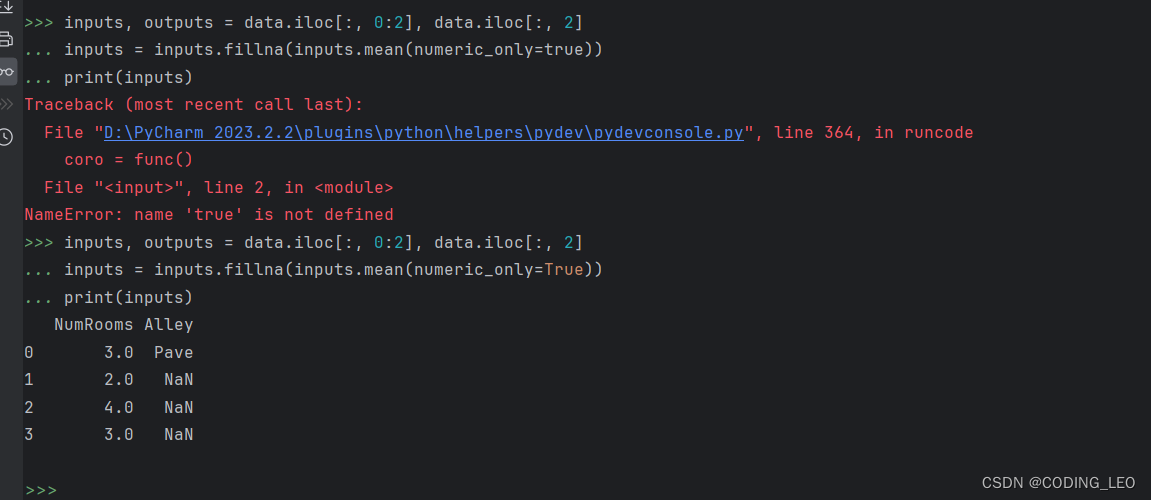
解决:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









