







文章目录
前言
论文题目:Adv-Diffusion: Imperceptible Adversarial Face Identity Attack via Latent
Diffusion Model
论文原文:https://arxiv.org/abs/2312.11285
论文来源:AAAI 二区
发表时间:2023

摘要
对抗性攻击包括在源图像上添加扰动,从而导致目标模型的错误分类,这表明了攻击人脸识别模型的潜力。现有的对抗人脸图像生成方法由于可移植性低、可检测性高,仍然不能达到令人满意的效果。在本文中,我们提出了一个统一的Adv-Diffusion框架,它可以在潜在空间而不是原始像素空间中产生难以察觉的对抗性身份扰动,利用潜在扩散模型的强大的绘画能力来生成真实的对抗性图像。具体来说,我们提出了身份敏感的条件扩散生成模型来产生周围环境中的语义扰动。设计的基于强度的自适应对抗摄动算法能够保证攻击的可转移性和隐身性。在公共FFHQ和CelebA-HQ数据集上进行的大量定性和定量实验证明,与最先进的方法相比,该方法在没有额外的生成模型训练过程的情况下取得了更好的性能。
一、引言
本节主要介绍了人脸识别系统的安全性问题以及对抗攻击的概念,并指出了现有对抗攻击方法的局限性。
1. 人脸识别系统的安全性问题
随着深度学习技术的发展,人脸识别系统在各个领域得到广泛应用,例如身份验证、安全监控等。然而,人脸识别系统也面临着安全风险,例如对抗攻击。对抗攻击是指通过在图像中添加微小的扰动,使得人脸识别系统产生错误的识别结果。
2. 对抗攻击的概念
对抗攻击的目标是生成对抗样本,即添加了微扰的图像,使得人脸识别系统将对抗样本错误地识别为目标身份。对抗攻击可以有效地评估人脸识别系统的鲁棒性和安全性。
3. 现有对抗攻击方法的局限性
现有的对抗攻击方法主要分为三类:
- 基于梯度的方法: 这类方法直接在原始像素空间中添加 Lp 范数约束的扰动,例如 FGSM 和 PGD。这类方法生成速度快,但是容易受到光照条件变化的影响,且在黑盒攻击场景下表现不佳。
- 基于补丁的方法: 这类方法生成局部的人脸补丁,例如眼镜、帽子等,并将其粘贴到原始图像上。这类方法在物理场景中更容易实现,但是生成的对抗样本容易被察觉。
- 基于隐秘性的方法: 这类方法生成视觉上难以察觉的对抗样本,例如化妆攻击和属性编辑攻击。这类方法更具隐蔽性,但是需要额外的训练数据和复杂的网络结构。
4. 本文工作的意义
为了解决现有对抗攻击方法的局限性,本文提出了一个基于潜在扩散模型的隐秘对抗性人脸攻击框架 Adv-Diffusion。该框架能够在潜在空间中生成对抗性扰动,并利用潜在扩散模型的强大图像生成能力,生成视觉上难以察觉的对抗样本。
5. 本文的主要贡献
本文的主要贡献包括:
- 提出了一个基于潜在扩散模型的隐秘对抗性人脸攻击框架 Adv-Diffusion。
- 设计了身份敏感的条件扩散生成模块,可以保证对抗性扰动主要集中在身份敏感区域周围。
- 提出了基于自适应强度的语义对抗扰动算法,可以确保攻击的转移性和隐秘性。
- 在公共数据集上进行了大量实验,验证了所提出方法的有效性和优越性。

二、相关工作
本节主要回顾了人脸识别领域的对抗攻击方法,并对现有方法的局限性进行了分析。
1. 基于梯度的方法
基于梯度的方法是最早的对抗攻击方法,其核心思想是直接在原始像素空间中添加 Lp 范数约束的扰动,例如 FGSM 和 PGD。这类方法的优点是生成速度快,但是也存在以下局限性:
易受光照条件变化的影响: 这类方法生成的对抗样本容易受到光照条件变化的影响,例如不同的光照强度和光照方向,从而影响攻击效果。
黑盒攻击场景下表现不佳: 这类方法需要知道目标模型的梯度信息,因此在黑盒攻击场景下表现不佳。
2. 基于补丁的方法
基于补丁的方法生成局部的人脸补丁,例如眼镜、帽子等,并将其粘贴到原始图像上。这类方法的优点是在物理场景中更容易实现,但是也存在以下局限性:
生成的对抗样本容易被察觉: 这类方法生成的对抗样本通常具有特定的颜色和纹理模式,容易被察觉。
攻击范围有限: 这类方法的攻击范围有限,只能针对特定的区域进行攻击。
3. 基于隐秘性的方法
基于隐秘性的方法生成视觉上难以察觉的对抗样本,例如化妆攻击和属性编辑攻击。这类方法的优点是更具隐蔽性,但是也存在以下局限性:
需要额外的训练数据或复杂的网络结构: 这类方法需要额外的训练数据或复杂的网络结构,例如生成对抗网络 (GAN)。
攻击效果有限: 这类方法的攻击效果有限,可能无法欺骗所有的人脸识别系统。
4. 本文工作的意义
为了解决现有对抗攻击方法的局限性,本文提出了一个基于潜在扩散模型的隐秘对抗性人脸攻击框架 Adv-Diffusion。该框架能够在潜在空间中生成对抗性扰动,并利用潜在扩散模型的强大图像生成能力,生成视觉上难以察觉的对抗样本。
三、方法
1. 问题定义
对抗性人脸身份攻击的目标是通过生成对抗样本误导人脸识别系统,使其将源图像误识别为目标身份。作者将目标形式化为最大化目标图像与对抗样本之间的身份相似性:
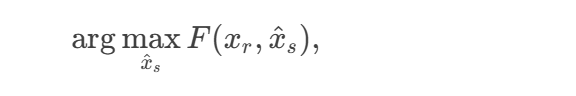
其中,F(⋅) 表示身份相似性度量函数,xs是源图像,xr是目标图像,x^s是生成的对抗样本。
核心要求: 生成的对抗样本需同时满足高迁移性(攻击多种模型)和 低可察觉性(人类难以察觉扰动)。
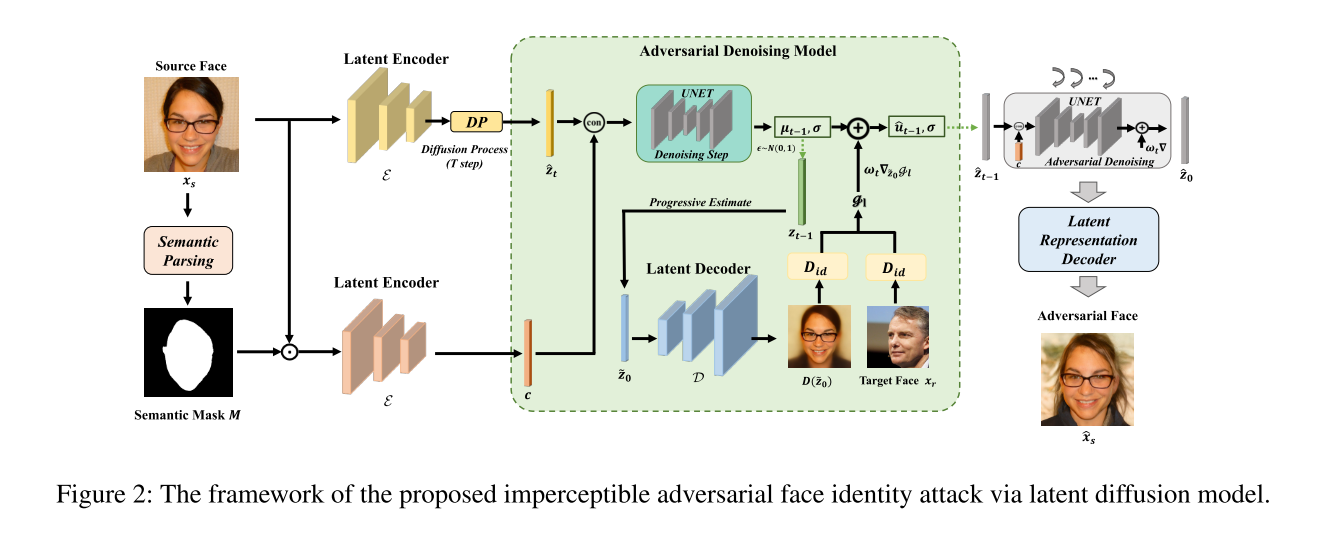
2. 潜在扩散模型(Latent Diffusion Model, LDM)
LDM 是生成对抗样本的基础框架,其核心优势在于 潜在空间的高效性 和 感知等价性(与像素空间语义对齐)。
步骤:
- 编码器 ε ε ε 将图像 x 压缩为潜在编码 z= ε ε ε(x)。
- 扩散过程: 通过 T 步逐步添加噪声,将 z 0 z_{0} z0扩散为高斯噪声 z T z_{T} zT ∼N(0,I)。
- 逆扩散过程: 从
z
T
z_{T}
zT逐步去噪,重建潜在编码
z
0
z_{0}
z0,最终通过解码器 D 生成图像
x 0 x_{0} x0 = D D D( z 0 z_{0} z0)。
数学形式:
前向扩散: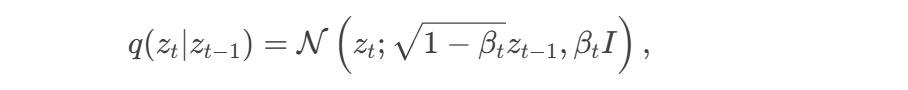
其中 βt 控制噪声强度。
逆扩散:
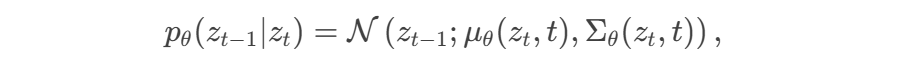
其中μθ和Σθ由神经网络预测。
3. 身份敏感条件扩散生成模型
动机: 人类身份判别主要依赖 敏感区域(如眼睛、鼻子),而无关区域(如发型、背景)对模型攻击更隐蔽。
实现步骤:
人脸解析: 使用预训练模型生成掩码 M,分离敏感区域
x
m
x_{m}
xm=
x
s
x_{s}
xs⊙(1−M)。
条件编码: 将
x
m
x_{m}
xm编码为潜在条件 c=
ε
ε
ε(
x
m
x_{m}
xm)。
条件逆扩散: 在逆扩散过程中,以c 为条件生成对抗样本:
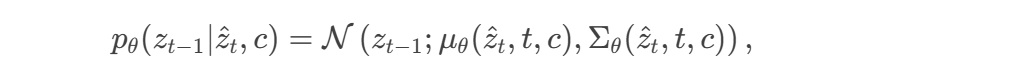
其中 z^t为添加扰动后的潜在编码
优势: 通过条件控制,扰动集中在身份无关区域,既保持敏感区域真实性,又提升隐蔽性。
4. 自适应强度的语义对抗扰动
目标:在潜在空间中添加扰动 Gt,平衡攻击效果与图像质量。
扰动生成公式:
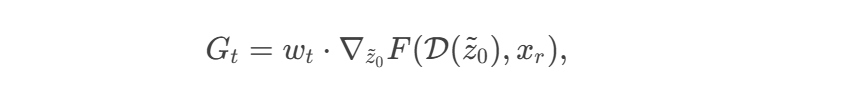
其中:z~0是当前逆扩散步骤的潜在编码估计。wt =s⋅Σθ(z^t,t,c) 是自适应强度系数,s 为超参数。
动态调整:
逆扩散早期(t较大),Σθ值较大,允许强扰动以提升攻击性。
逆扩散后期(t较小),Σθ值减小,减弱扰动以保证图像质量。
5. 算法流程
- 初始化:加载预训练 LDM 和解析模型。
- 潜在编码:编码源图像 x s x_s xs得到 z 0 z_0 z0,生成掩码 M M M并提取条件 c c c。
- 扩散初始化:通过前向扩散生成初始噪声潜在 z ^ T \hat{z}_T z^T。
- 逆扩散迭代:
- 逐步去噪生成 z t − 1 z_{t - 1} zt−1。
- 计算梯度扰动 G t G_t Gt并更新潜在编码: z ^ t − 1 = z t − 1 + G t \hat{z}_{t - 1}=z_{t - 1}+G_t z^t−1=zt−1+Gt。
- 解码输出:最终解码 z ^ 0 \hat{z}_0 z^0得到对抗样本 x ^ s = D ( z ^ 0 ) \hat{x}_s = \mathcal{D}(\hat{z}_0) x^s=D(z^0)。
6. 关键创新点
- 潜在空间攻击:相比像素空间,潜在空间的扰动更隐蔽且语义丰富。
- 条件生成控制:通过掩码分离敏感区域,确保扰动集中在身份无关区域。
- 自适应强度:动态调整扰动强度,平衡攻击性与图像质量。

四、实验
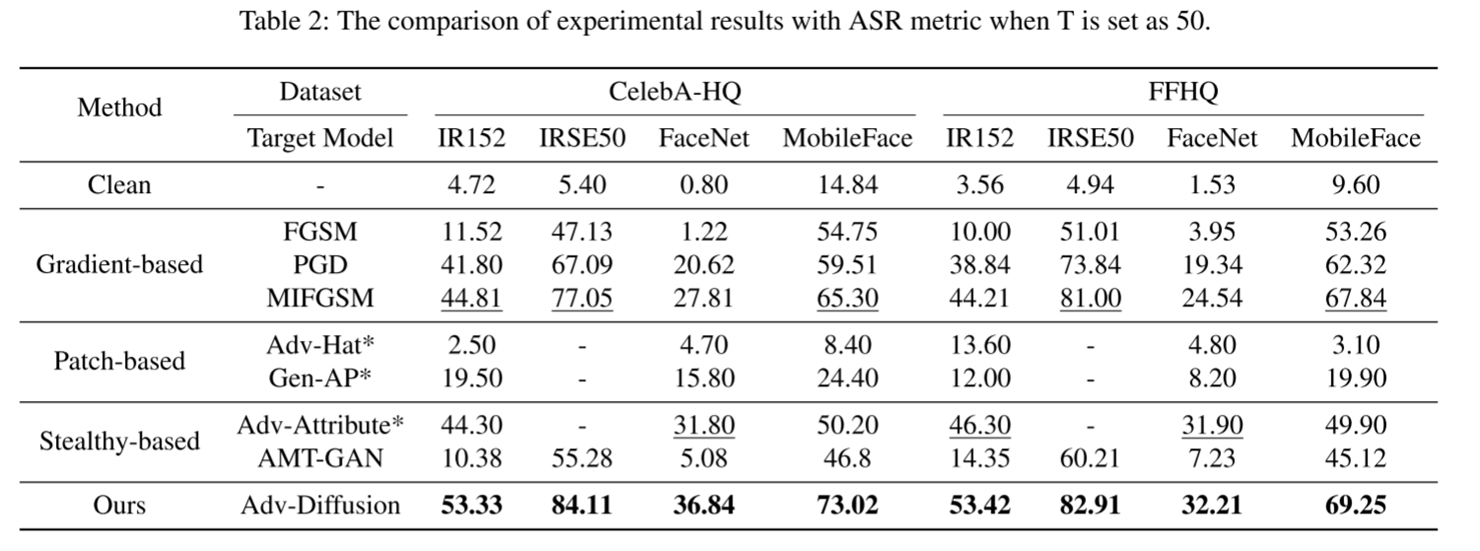
1、对比本方法与其他三类(基于梯度、基于补丁、基于隐形)攻击方法在不同数据集上的效果:
视觉效果:

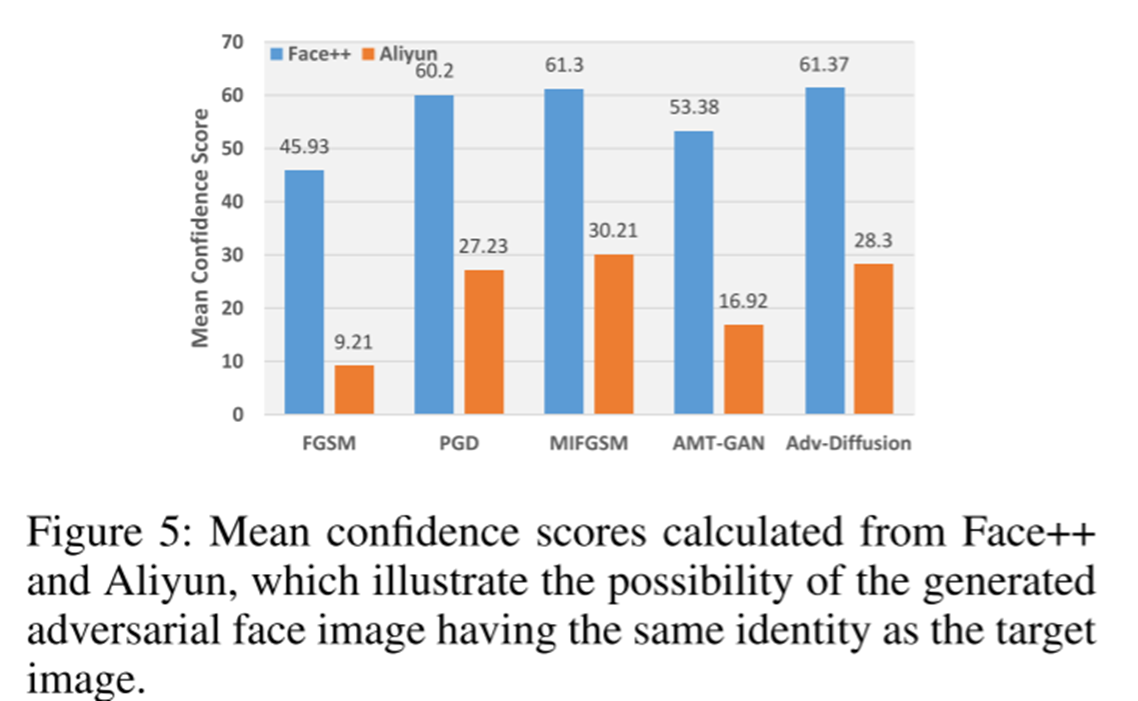
2、实际场景下的应用(face++与阿里云)
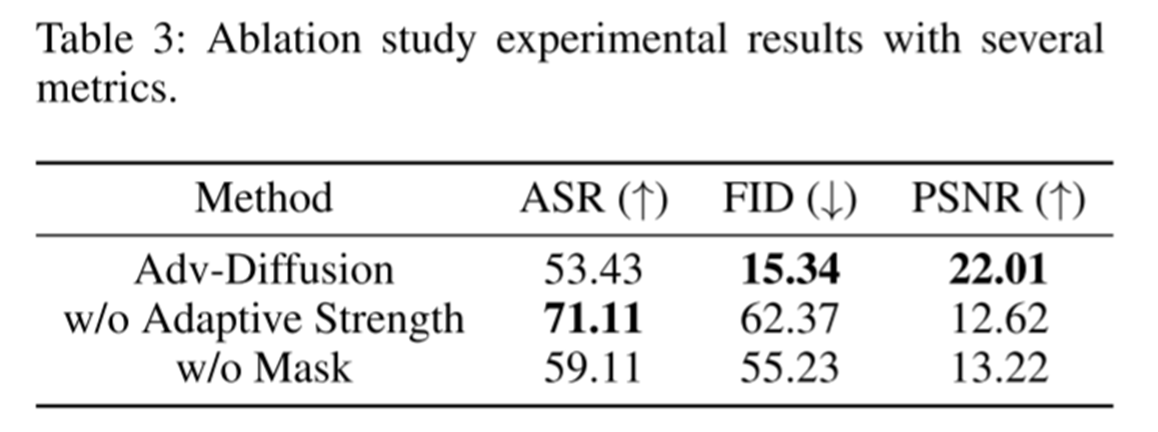
3、消融实验(有无适应强度、有无敏感区域掩码)
总结
- 在潜在空间中生成对抗性扰动
背景:
传统的对抗攻击方法(如FGSM、PGD)通常在原始像素空间中添加扰动,通过限制扰动的幅度(如Lp范数)来减少可察觉性。然而,像素空间的扰动容易被人类察觉,且在黑盒攻击中的迁移性有限。此外,这些方法忽略了图像的高层语义信息,导致生成的对抗样本不够自然。
创新点:
Adv-Diffusion 提出在 潜在空间(Latent Space) 中生成对抗性扰动,而非直接在像素空间中操作。潜在空间通过预训练的自动编码器(如Stable Diffusion的VAE)压缩图像为低维表示,保留了语义信息且计算效率更高。在潜在空间中扰动更具语义意义(如修改发型、背景),而非像素级的噪声,从而提升隐蔽性。
- 身份敏感的扩散生成模型
背景:
人类身份识别主要依赖敏感区域(如眼睛、鼻子、嘴巴),而无关区域(如发型、背景)对身份判别贡献较小。传统对抗攻击方法未显式区分这些区域,导致扰动可能破坏敏感区域,降低图像自然性。
创新点:
Adv-Diffusion 设计 身份敏感的条件扩散生成模块,通过预训练的人脸解析模型(如EHANet)分割敏感区域,并将敏感区域作为条件输入扩散模型,确保扰动集中在无关区域。
- 自适应强度的对抗性扰动算法
背景:
传统对抗攻击的扰动强度通常固定,难以平衡攻击性与隐蔽性。在扩散模型中,不同逆扩散步骤的噪声强度不同,需要动态调整扰动以适配生成过程。
创新点:
Adv-Diffusion 提出 自适应强度扰动策略,基于逆扩散步骤的噪声方差动态调整扰动强度。早期步骤(噪声多)允许强扰动以增强攻击性,后期步骤(噪声少)减弱扰动以保持图像质量。

















 3553
3553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









