






 ElasticSearch是为了解决数据库查询非结构化数据效率低下的问题,提供全文检索功能。全文检索通过索引非结构化数据,实现高效搜索和相关度匹配。ElasticSearch作为NoSQL数据库,包含索引库、映射类型、文档和字段等概念,支持多种查询方式如term、match、fuzzy等,还具备地理定位搜索功能。
ElasticSearch是为了解决数据库查询非结构化数据效率低下的问题,提供全文检索功能。全文检索通过索引非结构化数据,实现高效搜索和相关度匹配。ElasticSearch作为NoSQL数据库,包含索引库、映射类型、文档和字段等概念,支持多种查询方式如term、match、fuzzy等,还具备地理定位搜索功能。
一、有了数据库查询为什么还要ElasticSearch?
数据库一般只适合保存搜索结构化的数据,对于非结构化的数据( 比如文章内容),只能通过like%%模糊查询,但是在大量的数据面前,like%%有两个弊端:
1)搜索效率会很差,因为是做一个全表扫描(like%%会让索引失效)
2)搜索没办法通过相关度匹配排序(可能返回的是用户不关心的结果)
ElasticSearch就可以解决这些问题
二、什么叫全文检索
全文检索 将非结构化数据中的一部分信息提取出来,重新组织,使其变得具有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
什么叫非结构化数据:列如一篇文章内容中,涵盖了中文英文等,无法从文章中找出能组织起文章的结构的具体实例。
索引:字典的拼音表和部首检字表就相当于字典的索引,通过查找拼音表或者部首检字表就可以快速的查找到我们要查的字。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
三、全文检索的流程
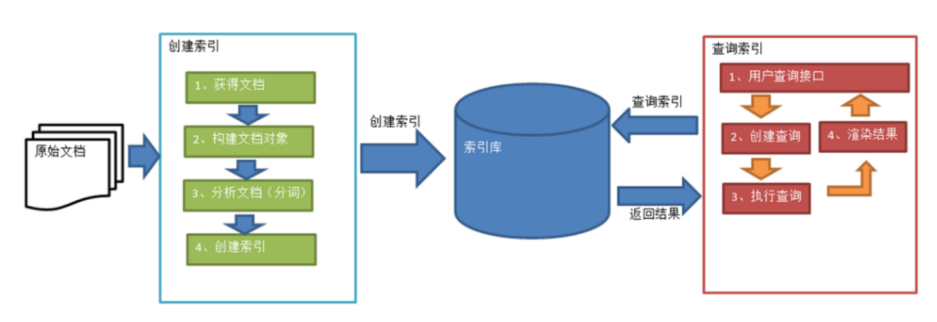
获取到原始文档之后,通过相关的处理,放入到索引库中(索引库主要用于存储索引),用户再通过索引库进行搜索,查询出结果
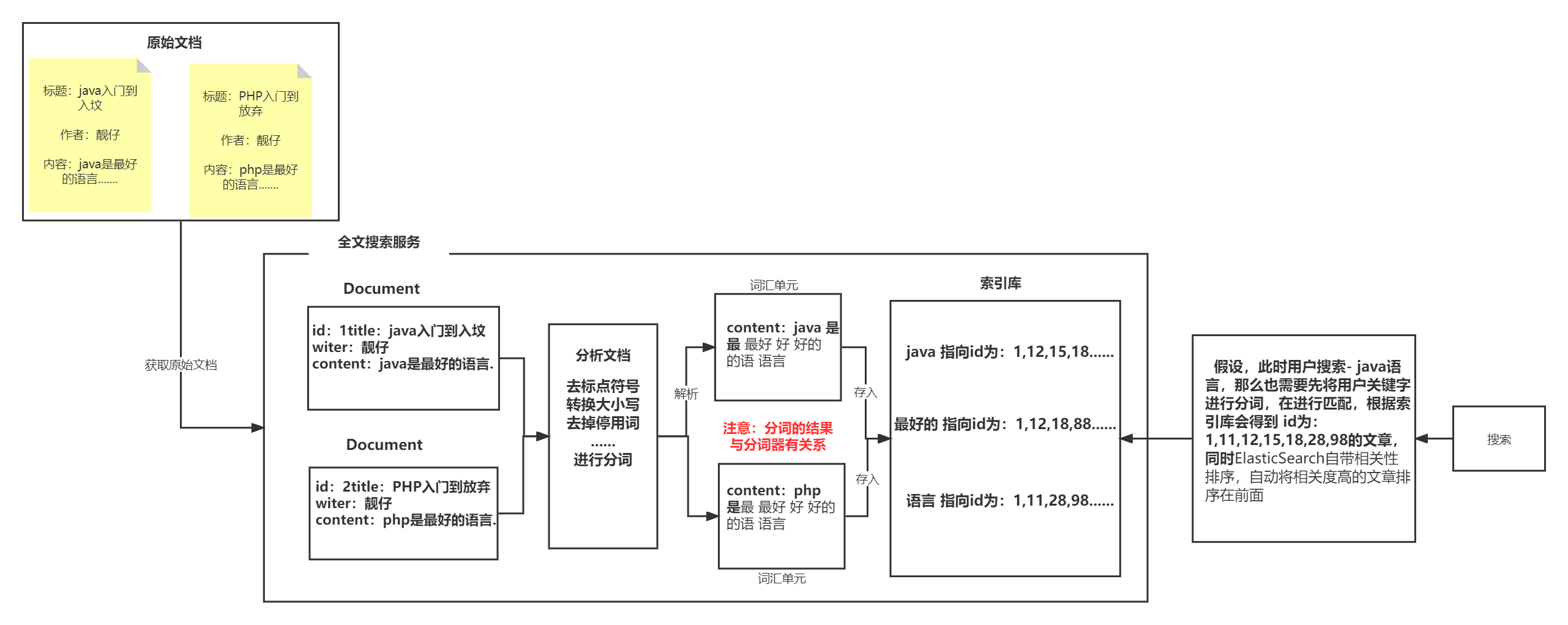
四、创建文档的过程
1.获得原始文档
原始文档是指要索引和搜索的内容,文档的来源不限。
2.创建文档对象(Document)
获取原始文档的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
3.分析文档(分词)
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元。
4.创建索引
创建索引是对语汇单元索引。
根据文字,与以下流程图一起理解
4.1正排排索引
简单来说,正向索引就是根据文件ID找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢
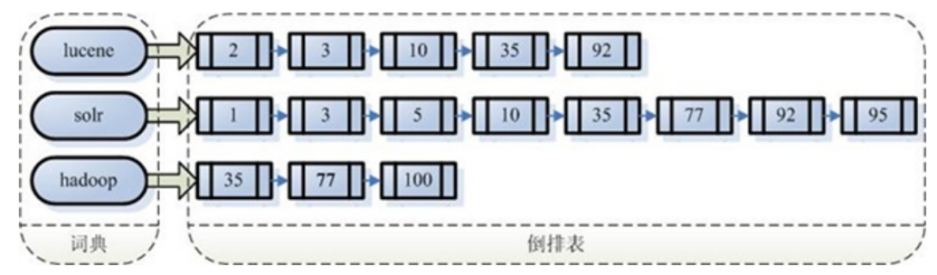
4.2倒排索引
倒排索引和正向索引刚好相反,是根据内容(词语)找文档
五、ElasticSearch(DB - NoSQL数据库 - 非关系型数据库)
5.1索引库(index)
索引库是ElasticSearch存放数据的地方,可以理解为关系型数据库中的一个数据库。我们操作的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。
5.2 映射类型(type)
映射类型用于区分同一个索引下不同的数据类型,相当于关系型数据库中的表。
注意:在 6.0 的index下是无法创建多个type,并且会在 7.0 中完全移除。
5.3 文档(documents)
文档是ElasticSearch中存储的实体,类比关系型数据库,每个文档相当于数据库表中的一行数据。
5.4 字段(fields)
文档由字段组成,相当于关系数据库中列的属性。
5.5 分片与副本
如果一个索引具有很大的数据量,它的数据量可能会超出单个节点的容量限制(硬盘容量),而且单个节点数据量过大,执行性能也会随之下降,每个搜索请求的执行效率都会降低。 为了解决上述问题, Elasticsearch 提出了分片的概念,索引将划分成多份,称为分片。每个分片都可以创建对应的副本,以便保证服务的高可用性。
5.6分词器
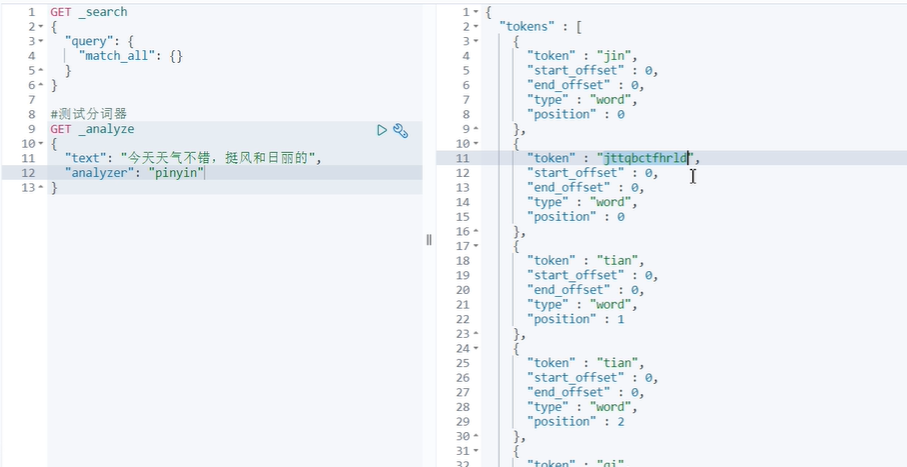
这里我使用的是中文分词器和拼音分词器
中文分词器:
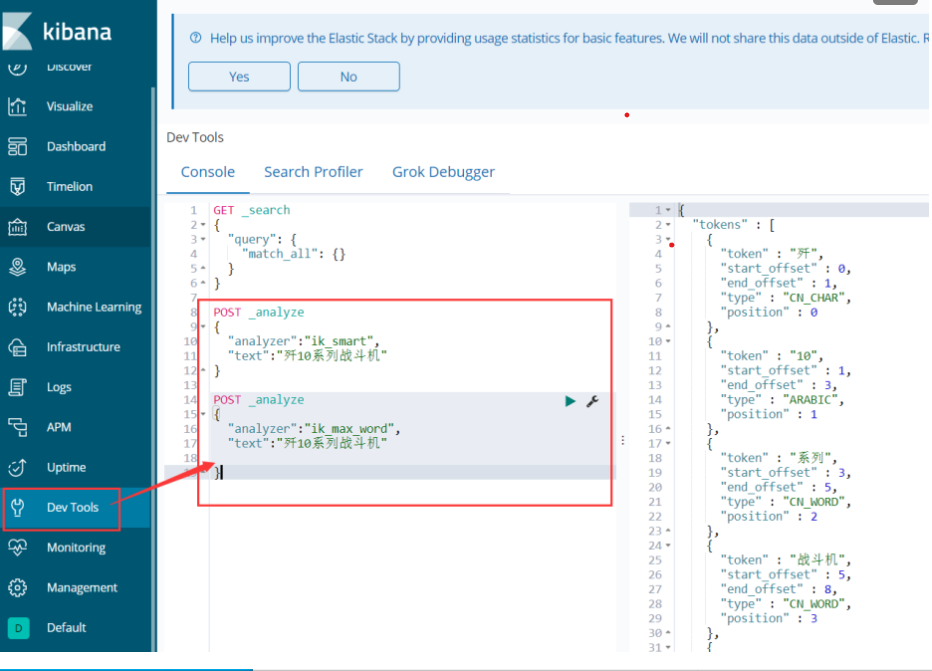
拼音分词器:
六、ElasticSearch相关操作
6.1索引库的操作
简单描述:
ElasticSearch采用Rest风格的API,因此其API就是一次Http请求
请求分为: PUT POST GET DELETE
GET:查询数据
PUT:插入数据
POST:更新数据,实际上很多情况下ElasticSearch不是很清晰你到底要作什么,有些时候POST也可用于新增或者查询
DELETE: 删除数据
6.1.1新增索引库语法
PUT /自定义的索引库名称
{
"settings":{
"number_of_shards": 3, #分片的数量
"number_of_replicas": 2 #副本的数量
}
}settings:表示索引库的设置
number_of_shards:表示分片的数量
number_of_replicas:副本数量
6.1.2查询索引信息
GET /想要索引库的名称6.1.3 判断索引库是否存在
HEAD /索引库名称6.1.4删除索引库
DELETE /索引库名称索引库 类似于 MySQL中数据库的概念
如果创建索引不指定settings,默认会有5个分片,1个副本(7.x之后的版本,默认是1个分片,1个副本)
6.2新增映射类型语法
PUT /索引库名/_mapping/类型名称
{
"properties": {
"字段名1": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
},
"字段名2": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}type:类型,可以是text、long、date、integer、object、keyword(表示关键字,不能被分词)
index:是否参与索引,默认为true
store:是否参与存储,默认为false
analyzer:分词器,可选 “ik_max_word”或者“ik_smart”,表示使用ik分词器
6.3字段属性详解
type :
String类型,又分两种:
text:可分词,不可参与聚合
keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
Numerical:数值类型,分两类
基本数据类型:long、interger、short、byte、double、float、half_flfloat
浮点数的高精度类型:scaled_float,需要指定一个精度因子,比如10或100,elasticsearch会把真实值乘以这个因子后存储,取出时再还原
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间
boolean: 设置字段类型为boolean后,可以填入的值为:true、false、"true"、"false"
binary: binary类型接受base64编码的字符串
geo_point: 地理点类型用于存储地理位置的经纬度对
index:
index影响字段的索引情况。
true:字段会被索引,则可以用来进行搜索。默认值就是true
false:字段不会被索引,不能用来搜索
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。
store 是否参与存储默认为false原因: (es会默认将数据进行备份,哪怕为false也可以进行搜索出结果)
是否将数据进行额外存储。在学习lucene和solr时,我们知道如果一个字段的store设置为false,那么在文档列表中就不会有这个字段的值,用户的搜索结果中不会显示出来。
但是在Elasticsearch中,即便store设置为false,也可以搜索到结果。
原因是Elasticsearch在创建文档索引时,会将文档中的原始数据备份,保存到一个叫做 source 的属性中。而且我们可以通过过滤 source 来选择哪些要显示,哪些不显示。而如果设置store为true,就会在 _source 以外额外存储一份数据,多余,因此一般我们都会将store设置为false,事实上,store的默认值就是false。
是否参与存储:考虑搜索结果是否需要展示出来进行判断
analyzer:
定义的是该字段的分析器,默认的分析器是 standard 标准分析器,这个地方可定义为自定义的分析器。
比如IK分词器为: ik_max_word 或者 ik_smart
boost:
激励因子。这个与lucene中一样,我们可以通过指定一个boost值来控制每个查询子句的相对权重。
该值默认为1。一个大于1的boost会增加该查询子句的相对权重
GET /_search {
"query": {
"bool": {
"must": {
"match": {
"content": {
"query": "full text search",
"operator": "and"
}
}
},
"should": [{
"match": {
"content": {
"query": "Elasticsearch",
"boost": 3
}
}
},
{
"match": {
"content": {
"query": "Lucene",
"boost": 2
}
}
}
]
}
}
}6.4文档相关(document)操作
6.4.1添加文档
#指定id的添加方式
PUT /索引库名/类型名称/id #id需要自己指定
{
"field1":"value1",
"field2":"value2",
...
}6.4.2更新文档
#全局更新,会将所有字段更新,没有指定的字段会自动删除
PUT /索引库名/类型名称/id #需要更新的id,id必须存在,如果不存在就变成了添加
{
"field1":"value1",
"field2":"value2",
...
}6.4.3删除文档
DELETE /索引库名/类型名称/id6.4.4查询文档
#查询索引库全部数据
GET /索引库名称/_search#批量查询
GET /_mget
{
"docs": [
{
"_index": "索引库名称1",
"_type": "映射类型1",
"_id":"查询文档id1"
},
{
"_index": "索引库名称2",
"_type": "映射类型2",
"_id":"查询文档id2"
}
]
}注意
文档(document)类似于 数据库中表的一条记录
当添加的文档中,设置的field,而type中没有时,type会自动的添加该field的映射记录,
这是elasticsearch的自动映射功能
7、基本查询
7.1 term、terms查询
term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个。 比如文档内容为:"小米电视机",被分词为"小米"和"电视机",term搜索的关键字必须为"小米"或者"电视机"才能搜索出这个文档,搜索"小米电视机"搜索不出来
#term查询
GET /索引库/映射类型/_search
{
"query": {
"term": {
"字段名称": {
"value": "搜索关键字"
}
}
}
}注意:terms查询 多个关键字之间是或者的关系,也就是说只要符合一个关键字的文档就会被查询出来
7.2 match查询
match 查询是高层查询,它们了解字段映射的信息:
1.如果查询 日期(date) 或 整数(integer) 字段,它们会将查询字符串分别作为日期或整数对待。
2.如果查询一个( not_analyzed )未分词的精确值字符串字段, 它们会将整个查询字符串作为单个词项对待。
3.但如果要查询一个( analyzed )已分析的全文字段, 它们会先将查询字符串传递到一个合适的分析器,然后生成一个供查询的词项列表。 一旦组成了词项列表,这个查询会对每个词项逐一执行底层的查询,再将结果合并,然后为每个文档生成一个最终的相关度评分。 match查询其实底层是多个term查询,最后将term的结果合并。
#match查询 - 根据关键字查询
GET /索引库/映射类型/_search
{
"query": {
"match": {
"字段名称": "搜索关键字"
}
}
}注意:operator值为
and表示关键词分词后的结果,必须全部匹配上
or表示需要一个分词匹配上即可,默认为or
7.3 Ids查询
ids查询是一类简单的查询,它过滤返回的文档只包含其中指定标识符的文档,
该查询默认指定作用在“_id”上面。
GET /索引库/映射类型/_search
{
"query": {
"ids": {
"values": ["1","3","6"...]
}
}
}7.4 prefix前缀查询
前缀查询的前提是 查询已经进行分词后的词语进行比对
GET /索引库/映射类型/_search
{
"query": {
"prefix": {
"字段名称": {
"value": "前缀"
}
}
}
}7.5 fuzzy查询
fuzzy(模糊)查询是一种模糊查询,term 查询的模糊等价。
GET /索引库/映射类型/_search
{
"query": {
"fuzzy": {
"字段名称": {
"value": "关键词",
"fuzziness": "2"
}
}
}
}注意:
1、fuzzy搜索以后,会自动尝试将你的搜索文本进行纠错,然后去跟文本进行匹配
2、fuzziness属性表示关键词最多纠正的次数
prefix_length属性表示不能被 “模糊化” 的初始字符数。 大部分的拼写错误发生在词的结尾,而不是词的开始。 例如通过将prefix_length 设置为 3 ,你可能够显著降低匹配的词项数量。
7.6 wildcard查询
wildcard(通配符)查询意为通配符查询
GET /索引库/映射类型/_search
{
"query": {
"wildcard": {
"字段名称": {
"value": "关键词? *"
}
}
}
}注意:
*表示匹配0或者多个字符
?表示匹配一个字符
wildcard查询不注意查询性能,应尽可能避免使用。
7.7 range查询
range查询既范围查询,可以对某个字段进行范围匹配
GET /索引库/映射类型/_search
{
"query": {
"range": {
"字段名称": {
"gte": 0,
"lte": 2000,
}
}
}
}注意:gte表示>=,lte表示<=,gt表示>,lt表示<
7.8 regexp查询
正则表达式查询,wildcard和regexp查询的工作方式和prefix查询完全一样。它们也需要遍历倒排索引中的词条列表来找到所有的匹配词条,然后逐个词条地收集对应的文档ID。它们和prefix查询的唯一区别在于它们能够支持更加复杂的模式。
GET /索引库/映射类型/_search
{
"query": {
"regexp": {
"字段名称": "正则表达式"
}
}
}注意:
1、prefix(前缀),wildcard(通配符)以及regexp(正则)查询基于词条进行操作。如果你在一个analyzed字段上使用了它们,它们会检查字段中的每个词条,而不是整个字段。
对一个含有很多不同词条的字段运行这类查询是非常消耗资源的。应该避免使用一个以通配符开头的模式(比如,*foo)
8、复合查询
8.1 bool查询
bool 过滤器。 这是个 复合过滤器(compound fifilter) ,它可以接受多个其他过滤器作为参数,并将这些过滤器结合成各式各样的布尔(逻辑)组合。
GET /索引库/映射类型/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"content": {
"value": "性价比"
}
}
},{
"match": {
"title": "电视机"
}
}
],
"must": [
{
"match": {
"content": "小米"
}
}
],
"must_not": [
{
"range": {
"price": {
"gte": 300,
"lte": 3000
}
}
}
],
"filter": {
"match": {
"title": "红米"
}
}
}
}
}属性含义
must: 返回的文档必须满足must子句的条件,并且参与计算分值,与 AND 等价
must_not:所有的语句都 不能(must not) 匹配,与 NOT 等价
should: 返回的文档可能满足should子句的条件。在一个Bool查询中,如果没有must或者filter,有一个或者多个should子句,那么只要满足一个就可以返回,与 OR 等价 可以满足,也可以不满足-
minimum_should_match:用来指定should至少需要匹配几个语句
filter:返回的文档必须满足filter子句的条件。但是不会像Must一样,参与计算分值
8.2 boosting查询
该查询用于将两个查询封装在一起,并改变其中一个查询所返回文档的分值。它接受一个positive查询和一个negative查询。只有匹配了positive查询的文档才会被包含到结果集中,但是同时匹配了negative查询的文档会被改变其相关度,通过将文档原本的score和negative_boost参数进行相乘来得到新的score。
GET /索引库/映射类型/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": "性价比"
}
},
"negative": {
"match": {
"content": "性价比"
}
},
"negative_boost": 0.1
}
}
}9、排序
ElasticSearch默认会有一套相关性分数计算,分数越高,说明文档相关性越大,也就越会排在前面。除了相关性排序之外,开发者也可以通过自己的需要,通过某些规则设置查询文档的排序
GET /索引库/映射类型/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"排序字段1": {
"order": "asc"
}
},
{
"排序字段2":{
"order": "desc"
}
}
]
}10、高亮
许多应用都倾向于在每个搜索结果中 高亮 显示搜索的关键词,比如字体的加粗,改变字体的颜色等.以便让用户知道为何该文档符合查询条件。在 Elasticsearch 中检索出高亮片段也很容易。高亮显示需要一个字段的实际内容。 如果该字段没有被存储(映射mapping没有将存储设置为 true),则加载实际的source,并从source中提取相关的字段。
GET /索引库/映射类型/_search
{
"query": {
....
},
"highlight": {
"fields": {
"待高亮字段1": {},
"待高亮字段2": {}
},
"post_tags": ["</font>"],
"pre_tags": ["<font color='red'>"],
"number_of_fragments": 5,
"fragment_size": 100
}
}参数含义
number_of_fragments: fragment 是指一段连续的文字。返回结果最多可以包含几段不连续的文字。
默认是5。
fragment_size: 某字段的值,长度是1万,但是我们一般不会在页面展示这么长,可能只是展示一部分。设置要显示出来的fragment文本判断的长度,默认是100
noMatchSize: 搜索出来的这个文档这个字段已经显示出高亮的情况,可是其它字段并没有任何显示,设置这个属性可以显示出来。
pre_tags: 标记 highlight 的开始标签。
post_tags: 标记 highlight 的结束标签。
11、 地理位置搜索
地理位置在ElasticSearch中的字段类型geo-point
#添加坐标点数据:
PUT /soufang/house/1
{
"name": "市民中心",
"location": {
"lat": 52.54737, #lat代表纬度
"lon": 120.067531 #lon代表经度
}
}11.1通过geo_distance过滤器搜索坐标
geo_distance:地理距离过滤器( geo_distance )以给定位置为圆心画一个圆,来找出那些地理坐标落在其中的文档
GET /soufang/house/_search
{
"query": {
"geo_distance":{
"location": {
"lat": 22.551013,
"lon": 114.065432
},
"distance": "1km",
"distance_type": "arc"
}
}
}distance:中心点的半径距离
distance_type:两点间的距离计算的精度算法
arc - 最慢但是最精确是弧形(arc)计算方式,这种方式把世界当作是球体来处理
plane - 平面(plane)计算方式,把地球当成是平坦的。 这种方式快一些但是精度略逊
11.2通过geo_bounding_box过滤器搜索坐标
geo_bounding_box: 查找某个长方形区域内的位置
GET /soufang/house/_search
{
"query": {
"geo_bounding_box":{
"location":{
"top_left": {
"lat": ,
"lon":
},
"bottom_right": {
"lat": ,
"lon":
}
}
}
}
}top_left:代表矩形左上角
bottom_right:代表矩形右下角
11.3通过geo_polygon过滤器搜索坐标
geo_polygon:查找位于多边形内的地点
GET /soufang/house/_search
{
"query": {
"geo_polygon": {
"location":{
"points": [
[123.908911, 22.613748],
[174.056952,22.634298],
[114.031368,22.575843],
[114.097196,22.500803],
[113.9,22.493591]
]
}
}
}
}11.4过滤结果通过距离排序
GET /soufang/house/_search
{
"query": {
"geo_distance":{
"location": {
"lat": 22.551013,
"lon": 114.065432
},
"distance": "1km",
"distance_type": "arc"
}
},
"sort": [
{
"_geo_distance": {
"order": "asc",
"location": {
"lat": 22.551013,
"lon": 114.065432
},
"unit": "km",
"distance_type": "arc"
}
}
]
}unit:以 公里(km)为单位,将距离设置到每个返回结果的 sort 键中


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









