



1.安装Blast
wget https://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/LATEST/ncbi-blast-2.16.0+-x64-linux.tar.gztar -zxvf ncbi-blast-2.16.0+-x64-linux.tar.gz #解压
mv ncbi-blast-2.16.0+ blast #重命名
cd blast #进入安装路径
pwd #获取路径,下面要用
/mnt/rna01/shangtt/blast需要将blast的路径加入到环境变量中,方便以后的调取
可以用 vim 编辑器,在 ~/.bashrc文件 输入如下所示:
按 i 进入输入模式,在最后加入以下行:
export PATH=/mnt/rna01/shangtt/blast(替换成自己的路径):$PATH按 esc 退出输入模式,进入命令模式。输入 :wq 保存并退出
source ~/.bashrc验证:
blastn -version2.下载数据库
网址:Index of /blast/db/FASTA (nih.gov)![]() https://ftp.ncbi.nlm.nih.gov/blast/db/FASTA/由于nr太大,这里只使用swissprot
https://ftp.ncbi.nlm.nih.gov/blast/db/FASTA/由于nr太大,这里只使用swissprot
mkdir db
cd db
# 执行bin文件夹下的 makeblastdb
/mnt/rna01/shangtt/blast/bin/makeblastdb -in swissprot -dbtype prot -title “swissprot” -out lsxp会生成lsxp的数据库
3.生成PSSM矩阵
3.1目标序列
test.fasta
>test
EVQLVESGGGVVQPGGSLRLSCAASGFTFNSYGMHWVRQAPGKGLEWVAFIRYDGGNKYYADSVKGRFTISRDNSKNTLYLQMKSLRAEDTAVYYCANLKDSRYSGSYYDYWGQGTLVTVS
3.2运行psiblast
命令行:
/mnt/rna01/shangtt/blast/bin/psiblast \
-query test.fasta \
-db /mnt/rna01/shangtt/blast/db/lxsp \
-num_iterations 3 \
-out test.out \
-out_ascii_pssm test.pssm-query 查找蛋白质文件
-db 后面是数据库
-num_iterations 迭代次数
-out 日志文件
-out_ascii_pssm 生成文件
3.3运行结果
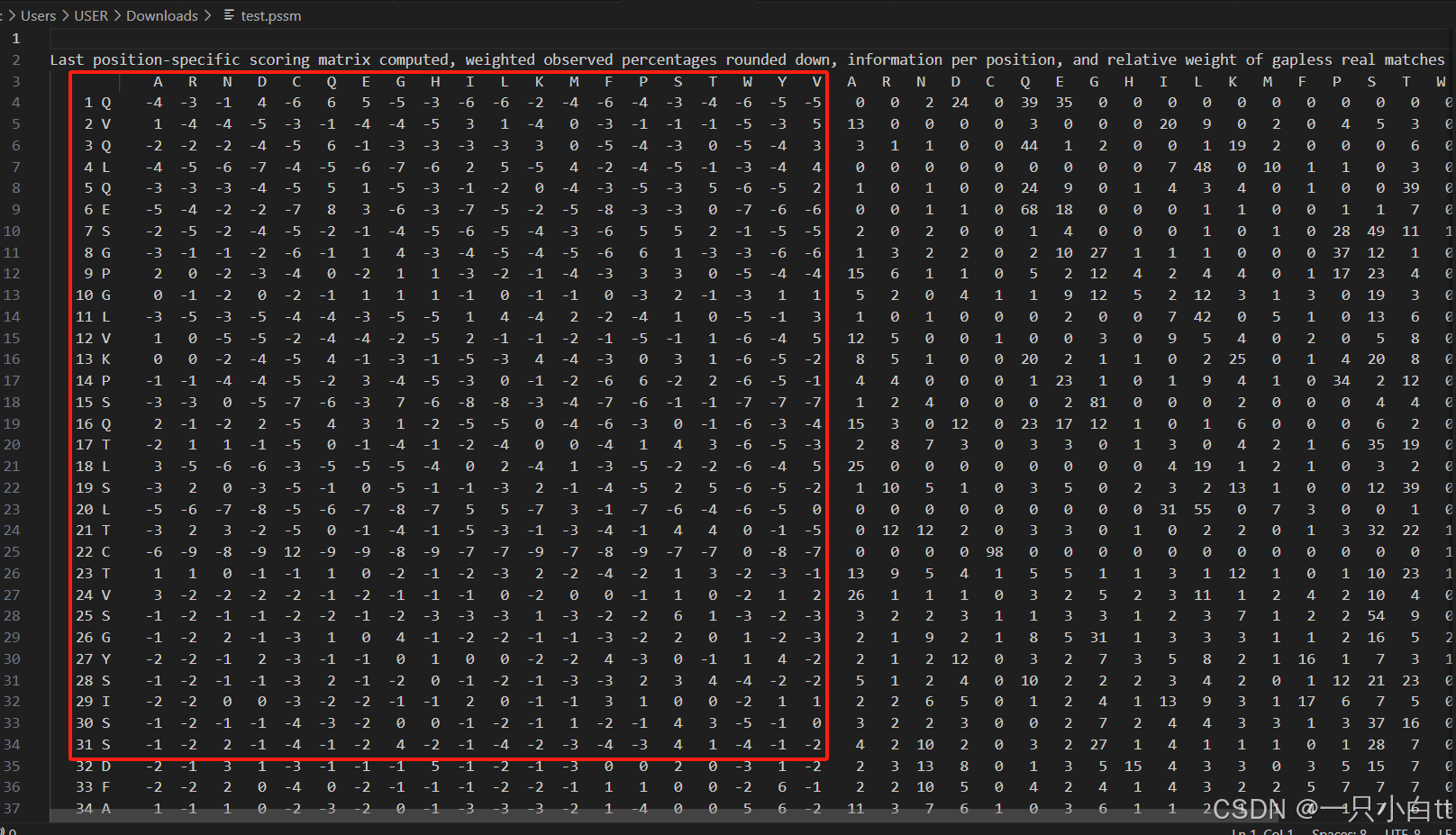
前20列就是PSSM矩阵。
4.批量生成pssm矩阵
输入是包含多条序列的fasta文件。
输出是/pssm目录
import os
def command_pssm(content, output_file, pssm_file):
os.system('/mnt/rna01/shangtt/blast/bin/psiblast \
-query %s \
-db /mnt/rna01/shangtt/blast/db/lxsp \
-num_iterations 3 \
-out %s \
-out_ascii_pssm %s &' % (content, output_file, pssm_file))
# 对每个序列进行 PSSM 打分
def pssm(proseq, outdir):
# 确保输出目录和子目录存在
fasta_dir = os.path.join(outdir, 'fasta')
os.makedirs(fasta_dir, exist_ok=True)
outpssmdir = os.path.join(outdir, 'pssm')
os.makedirs(outpssmdir, exist_ok=True)
inputfile = open(proseq, 'r')
content = ''
chain_name = ''
for eachline in inputfile:
if '>' in eachline:
if len(content):
temp_file = open(os.path.join(fasta_dir, chain_name), 'w')
temp_file.write(content)
temp_file.close()
input_file = os.path.join(fasta_dir, chain_name)
output_file = os.path.join(outdir, chain_name + '.out')
pssm_file = os.path.join(outpssmdir, chain_name + '.pssm')
command_pssm(input_file, output_file, pssm_file)
content = ''
chain_name = eachline[1:5] + eachline[6:7]
content += eachline
if len(content):
temp_file = open(os.path.join(fasta_dir, chain_name), 'w')
temp_file.write(content)
temp_file.close()
input_file = os.path.join(fasta_dir, chain_name)
output_file = os.path.join(outdir, chain_name + '.out')
pssm_file = os.path.join(outpssmdir, chain_name + '.pssm')
command_pssm(input_file, output_file, pssm_file)
inputfile.close()
proseq = '/mnt/rna01/shangtt/blast/predict/test.fasta'
outdir = '/mnt/rna01/shangtt/blast/predict/pssm'
pssm(proseq, outdir)
我们也可以从pkl文件中得到序列,并将pssm矩阵处理成我们想要的前20列,保存起来。
import os
import pandas as pd
import pickle
import numpy as np
# 生成 PSSM 矩阵的命令函数
def command_pssm(content, output_file, pssm_file):
os.system('/mnt/rna01/shangtt/blast/bin/psiblast \
-query %s \
-db /mnt/rna01/shangtt/blast/db/lxsp \
-num_iterations 3 \
-out %s \
-out_ascii_pssm %s' % (content, output_file, pssm_file))
# 生成 PSSM 矩阵的函数
def pssm(sequence, chain_name, outdir):
# 确保输出目录和子目录存在
fasta_dir = os.path.join(outdir, 'fasta')
os.makedirs(fasta_dir, exist_ok=True)
outpssmdir = os.path.join(outdir, 'oldpssm')
os.makedirs(outpssmdir, exist_ok=True)
# 写入临时 fasta 文件
fasta_file = os.path.join(fasta_dir, f'{chain_name}.fasta')
with open(fasta_file, 'w') as temp_file:
temp_file.write(f'>{chain_name}\n{sequence}\n')
# 定义输出文件路径
output_file = os.path.join(outdir, f'{chain_name}.out')
pssm_file = os.path.join(outpssmdir, f'{chain_name}.pssm')
# 生成 PSSM
command_pssm(fasta_file, output_file, pssm_file)
# 读取 PSSM 文件
pssm_data = []
with open(pssm_file, 'r') as pf:
for line in pf:
if line[0].isdigit(): # 检查行是否以数字开头
pssm_data.append(line.split()[2:22]) # 提取有效数据
return np.array(pssm_data, dtype=int)
# 加载数据集
with open('combined_data_processed.pkl', 'rb') as file:
dataset = pickle.load(file)
# 对每个条目生成 PSSM 矩阵并添加到数据集中
outdir = '/mnt/rna01/shangtt/project/TAP/data/pssm'
window_size = 5
for index, row in dataset.iterrows():
antibody_name = row['Antibody_Name']
h_sequence = row['H_S']
l_sequence = row['L_S']
# 生成重链 PSSM
pssm_H = pssm(h_sequence, f'{antibody_name}_H', outdir)
# features_H = extract_features_from_pssm(pssm_H, window_size)
dataset.at[index, 'pssm_H'] = str(pssm_H)
# 生成轻链 PSSM
pssm_L = pssm(l_sequence, f'{antibody_name}_L', outdir)
# features_L = extract_features_from_pssm(pssm_L, window_size)
dataset.at[index, 'pssm_L'] = str(pssm_L)
#
# # 保存更新后的数据集
with open('with_pssm_dataset.pkl', 'wb') as file:
pickle.dump(dataset, file)
print("PSSM 矩阵生成并保存到 with_pssm_dataset.pkl 文件中。")这里我的数据集中是包含两种序列,H_S和L_S,根据自己的数据集进行修改。最后得到的简化PSSM保存在【'pssm_H'】和【'pssm_L'】中。
解析和提取PSSM特征,需要先解析PSSM文件并提取特征。这可以通过滑动窗口技术来实现。
import numpy as np
import pickle
import pandas as pd
import ast
def pad_or_truncate_pssm(pssm, fixed_length):
"""
对PSSM矩阵进行填充或截断,使其长度为fixed_length。
参数:
pssm (np.ndarray): 原始PSSM矩阵,形状为 (L, 20)。
fixed_length (int): 固定长度。
返回:
np.ndarray: 填充或截断后的PSSM矩阵,形状为 (fixed_length, 20)。
"""
L, num_features = pssm.shape
if L < fixed_length:
# 对PSSM矩阵进行填充
padded_pssm = np.pad(pssm, ((0, fixed_length - L), (0, 0)), mode='constant', constant_values=0)
return padded_pssm
else:
# 对PSSM矩阵进行截断
truncated_pssm = pssm[:fixed_length, :]
return truncated_pssm
def extract_window_features(pssm_matrices, window_size, fixed_length):
"""
提取多个PSSM矩阵的滑动窗口特征,并保证所有特征矩阵具有相同的维度。
参数:
pssm_matrices (list of np.ndarray): 包含多个PSSM矩阵的列表,每个矩阵形状为 (L, 20)。
window_size (int): 滑动窗口大小。
fixed_length (int): 固定长度。
返回:
np.ndarray: 所有PSSM矩阵对应的滑动窗口特征矩阵,形状为 (num_samples, feature_dim)。
"""
half_window = window_size // 2
feature_list = []
for pssm in pssm_matrices:
# 对PSSM矩阵进行填充或截断
pssm = pad_or_truncate_pssm(pssm, fixed_length)
# 使用零填充对PSSM矩阵进行填充
padded_pssm = np.pad(pssm, ((half_window, half_window), (0, 0)), mode='constant', constant_values=0)
# 提取滑动窗口特征
features = []
for i in range(fixed_length):
window = padded_pssm[i:i+window_size].flatten()
features.append(window)
feature_matrix = np.array(features)
feature_list.append(feature_matrix)
return feature_list
# 加载数据
with open('with_pssm_dataset.pkl', 'rb') as file:
data = pickle.load(file)
# 确保pssm_H是一个Pandas Series对象
pssm_H_series = pd.Series(data['pssm_H'])
pssm_L_series = pd.Series(data['pssm_L'])
# 将Series转换为列表并解析每个元素,移除第一行
pssm_matrices_H = [np.array(ast.literal_eval(pssm_str)[1:], dtype='int') for pssm_str in pssm_H_series]
pssm_matrices_L = [np.array(ast.literal_eval(pssm_str)[1:], dtype='int') for pssm_str in pssm_L_series]
# 计算所有PSSM矩阵的平均长度
average_length_H = int(np.mean([pssm.shape[0] for pssm in pssm_matrices_H]))
average_length_L = int(np.mean([pssm.shape[0] for pssm in pssm_matrices_L]))
# 设置滑动窗口大小
window_size = 3
# 提取滑动窗口特征
feature_lists_H = extract_window_features(pssm_matrices_H, window_size, average_length_H)
feature_lists_L = extract_window_features(pssm_matrices_L, window_size, average_length_L)
# 保存feature_lists到dataset.pkl的feature_pssm_H中
data['feature_pssm_H'] = feature_lists_H
data['feature_pssm_L'] = feature_lists_L
with open('dataset.pkl', 'wb') as file:
pickle.dump(data, file)最后我们得到了一个dataset.pkl文件,里面包含了经过滑动窗口处理过的pssm特征。
最后可以输入到随机森林中或者其他模型中(注意,我的例子是回归任务)。
import numpy as np
import pickle
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
import ast
import matplotlib.pyplot as plt
# 加载数据
with open('data/dataset.pkl', 'rb') as file:
data = pickle.load(file)
feature_lists_H = data['feature_pssm_H']
feature_lists_L = data['feature_pssm_L']
# 展平特征矩阵并转换为适合模型输入的格式
flattened_features_H = [features.flatten() for features in feature_lists_H]
flattened_features_L = [features.flatten() for features in feature_lists_L]
flattened_features = np.hstack((flattened_features_H, flattened_features_L))
X = np.array(flattened_features)
targets = data['label']
y = np.array(targets)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化随机森林回归模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
# 训练模型
rf_model.fit(X_train, y_train)
# 预测
y_pred = rf_model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse:.4f}')
print(f'R^2 Score: {r2:.4f}')
plt.figure(figsize=(10, 6))
plt.plot(y_test, label='True Values', marker='o', linestyle='-', color='blue', markersize=5)
plt.plot(y_pred, label='Predicted Values', marker='x', linestyle='--', color='red', markersize=5)
plt.title('True vs Predicted Values')
plt.xlabel('Sample Index')
plt.ylabel('Value')
plt.legend()
plt.grid()
plt.show()

















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









