







ArraryList源码研究
ArraryList是我学过和用过的最早的集合之一,但却很少涉及它的源码。前几天看了一部分源码,了解了一些东西。
继承结构
先上一张图从大概上了解它的继承结构:
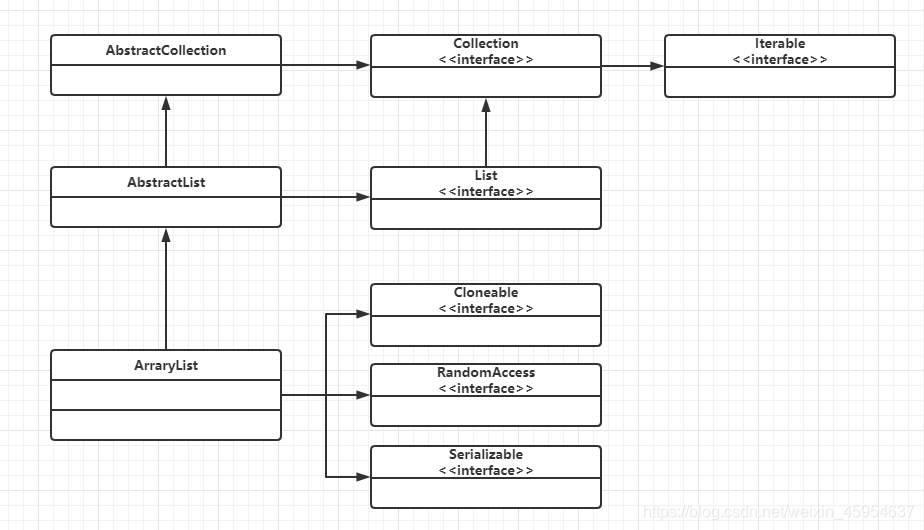
从上图可以看出ArrayList继承了虚拟类AbstaractList,并且最终继承List,List是一个单列且有序的集合接口,所以根据接口的规范,ArrayList集合必须是单列且有序的集合,同时实现了Cloneable,RandomAccess,Serializable这三个能力接口,这几个接口一会讲解,看下面的代码。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
Cloneable接口
一个类实现该Cloneable接口,以向该Object.clone()方法指示该方法对该类的实例进行克隆是合法的。在没有实现Cloneable接口的实例上调用Object的clone方法会 导致 CloneNotSupportedException引发异常。按照约定,实现此接口的类应使用公共方法重写 Object.clone(受保护的)。
上面是jdk1.8官方文档中的描述,简单点来说及一个对象需要覆写Object类中的clone方法并且实现cloneabe接口才能完成克隆,否则就报CloneNotSupportedException,并且在object源码中也可以看到如下代码:
protected native Object clone() throws CloneNotSupportedException;
但是进入cloneable接口之后发现什么都没有,只是一个标记:
public interface Cloneable {
}
那Object类如何判断是否实现了Cloneabe接口呢?
问题就在native关键字这里,这个关键字代表的是java的原生方法,并不会调用java中的方法,而是JVM中的实现方法,具体可以从这里看:https://baike.baidu.com/item/native/13128691?fr=aladdin
在ArraryList中也有相对应的clone方法实现:
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
RandomAccess
List实现使用的标记接口,指示它们支持快速(通常为恒定时间)随机访问。该接口的主要目的是允许通用算法更改其行为,以便在应用于随机访问或顺序访问列表时提供良好的性能。
应用于随机访问列表(例如ArrayList)的最佳算法 在应用于顺序访问列表(例如LinkedList)时会产生二次行为。鼓励使用通用列表算法,然后再应用给定列表(如果将其应用于顺序访问列表则性能较差),然后检查给定列表是否为该接口的 实例,并在必要时更改其行为以保证可接受的性能。
这同样是一个标记接口,里面什么也没有。简单点说这个接口就是用来提升for循环遍历性能的,同时这个接口在LinkedList中是没有的,这也是ArraryList查询快的一个原因之一。
public interface RandomAccess {
}
Serializable
通过实现java.io.Serializable接口的类,可以启用类的可序列化性。未实现此接口的类将不会对其状态进行序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
这同样是一个标记接口,如官方文档所说,这就是用来做序列化的标记用的。
ArraryList属性
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
DEFAULT_CAPACITY这是定义的ArraryList的初始容量(即默认空间大小)。EMPTY_ELEMENTDATA 空的元素数组,用来实例化数组保存数据。DEFAULTCAPACITY_EMPTY_ELEMENTDATA 同样是空的实例,但是与EMPTY_ELEMENTDATA有些区别,是空参实例化时使用或者与EMPTY_ELEMENTDATA 进行比对。elementData 用来存放集合的数据。size 用来记录集合的大小。从这些变量可以看出ArraryList的底层是基于数组实现的。
ArraryList构造即实例化
无参构造
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
从上面代码可以看出ArraryList的空参创建,只是实例化了一个空的数组,且没有指定长度,数组的长度将会在添加元素时,赋予默认长度(集合空间大小),或者进行扩容,这里后面会详细说明。
有参构造
指定集合初始容量
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
代码逻辑也非常简单,通过对初始容量值得判断走不同的逻辑,如果大于0,以初始化参数作为数组的长度初始化数组,用来作为集合的存放数据的容器。如果等于0,则通过预先在属性中设置的空数组来初始化参数,如果类型不符或者为负数则抛出IllegalArgumentException异常。
传入Collection接口的子类实现
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
代码逻辑依然简单,先把传入的数组转化为数组,对集合的长度进行校验,如果为空则直接赋予空的数组,不为空的情况下,对集合类型进行判断,如果同为ArraryList就把数组的地址值指向传入的数组地址,如果不同类型,则需要进行一次数组拷贝。
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
这是数组拷贝的代码。
可以看出是先实例化一个数组,然后在吧原来的数组,通过 System.arraycopy() 方法复制到新的数组上。为了保证专一性,这里不做深入的讲解了。
ArraryList扩容机制
扩容顾名思义就是把容量扩充,而ArraryList的底层是基于数组实现的,那么问题来啦,数组都是固定长度,如果在长度为0的数组上在添加那莫将会报ArrayIndexOutOfBoundsException异常。那么ArraryList是如何实现的呢?请听我慢慢道来。。。
扩容一般是在添加元素时,容量不足才产生的所以我们从ArraryList的add()方法开始入手。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
这就时我们最常使用的add方法,添加完成返回boolean类型的值。这里也还看不到是如何进行扩容的,但是这里ensureCapacityInternal(size + 1)这个方法调用应该会有一点线索,那么进去看看:
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
这里貌似也没有,但我到这里突然想起一件事情,那就是在无参构造和有参构造参数为0的时候初始化貌似没有为集合初始化默认大小,不信的同学可以翻回看看。
calculateCapacity 这个方法会不会做容器空间赋予默认大小呢?进去看看
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
从这里可以看出来,通过比对确认了一个空间的大小,如果集合为空的则赋予空间默认大小值,如果不为空,则看空间是否满足现在数组长度+1的大小。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
ensureExplicitCapacity 正好需要一个集合的空间大小值。来判断集合是否需要扩容,如果空间不足,则进行扩容grow 方法,那么接下来就是扩容机制的重点了:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
这就是进行扩容的方法,从代码中可以看出真正的扩容是通过这行代码实现的int newCapacity = oldCapacity + (oldCapacity >> 1); 代码中的>> 为二进制中的位移符,表示向右移动几位,这里可以简单的理解为oldCapacity/2但是代码中的性能要高n+n/一些。所以从这里可以看到ArraryList的数组扩容后为n+n/2。
同时在代码最后进行了数组拷贝,也就是说在数组扩容其实就是利用的两个不容的数组,把长度小的数组,拷贝到了长度大的数组中。
但这也意味着产生了一些垃圾空间,如果ArraryList在初始化时不能确定数据量大小,且后期经常不停的插入数据,那么将会又大量的垃圾空间产生造成性能下降,这也是ArraryList增删慢的原因之一
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
这是删除的代码,在删除后也利用到了数组拷贝,并对索引重新排序。所以速度也是相对与LinkedList的链表结构要慢许多。
小验证
由于前面说过了RandomAccess 这个接口是用来提升ArraryList的for循环遍历性能的,现在验证一下,同时还会加上LinkedList做一点比对。
private static void getLinkedIteratorTime(LinkedList<String> stringsLinked) {
long AF_frist = System.currentTimeMillis();
Iterator<String> iterator = stringsLinked.iterator();
while (iterator.hasNext()){
String next = iterator.next();
}
long AF_end =System.currentTimeMillis();
System.out.println("linkedIterator "+ (AF_end-AF_frist) +"秒");
}
private static void getLinkedForTime(LinkedList<String> stringsLinked) {
long AF_frist = System.currentTimeMillis();
for (int i = 0; i < stringsLinked.size(); i++) {
stringsLinked.get(i);
}
long AF_end =System.currentTimeMillis();
System.out.println("LinkedFor "+ (AF_end-AF_frist) +"秒");
}
private static void getArrayIterorTime(ArrayList<String> strings) {
long AF_frist = System.currentTimeMillis();
Iterator<String> iterator = strings.iterator();
while (iterator.hasNext()){
String next = iterator.next();
}
long AF_end =System.currentTimeMillis();
System.out.println("ArraryListIterator"+ (AF_end-AF_frist) +"秒");
}
private static void getArrayForTime(ArrayList<String> strings) {
long AF_frist = System.currentTimeMillis();
for (int i = 0; i < strings.size(); i++) {
strings.get(i);
}
long AF_end =System.currentTimeMillis();
System.out.println("ArraryListFor"+ (AF_end-AF_frist) +"秒");
}
写了四个方法,分别有ArraryList的for循环遍历,Iterator遍历,LinkedList的for循环遍历,Iterator遍历
下面插入数据
ArrayList<String> strings = new ArrayList<>();
LinkedList<String> stringsLinked = new LinkedList<>();
for (int i = 0; i < 50000; i++) {
strings.add(""+i+1);
stringsLinked.add(""+i+1);
}
getArrayForTime(strings);
getArrayIterorTime(strings);
getLinkedForTime(stringsLinked);
getLinkedIteratorTime(stringsLinked);
分别在两个集合中插入5万条数据,测试结果如下:
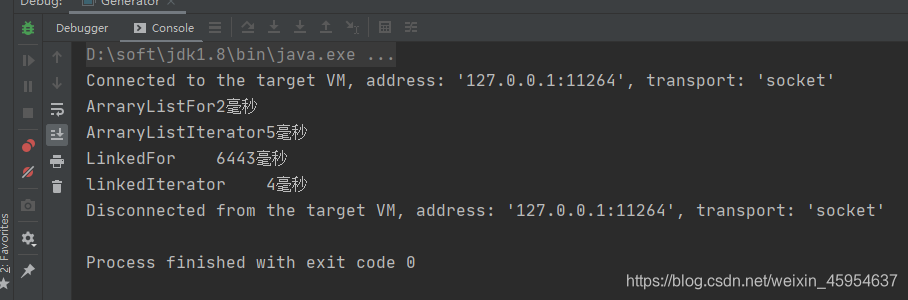
总体来说遍历速度:
当数据量在5万左右时
ArrayList for > LinkedList Iterator > ArraryList Iterator > LinkedList for
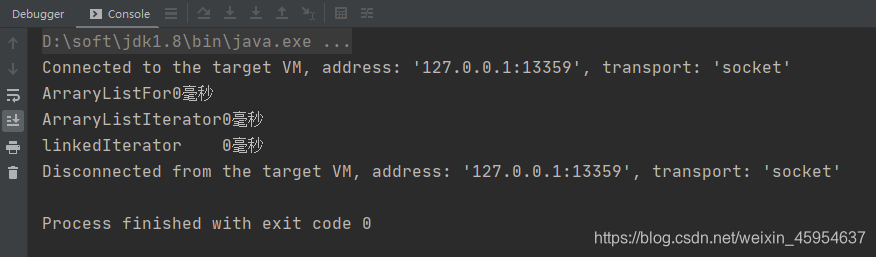
但当数据量小于1000时,则前三个性能差异并不大,
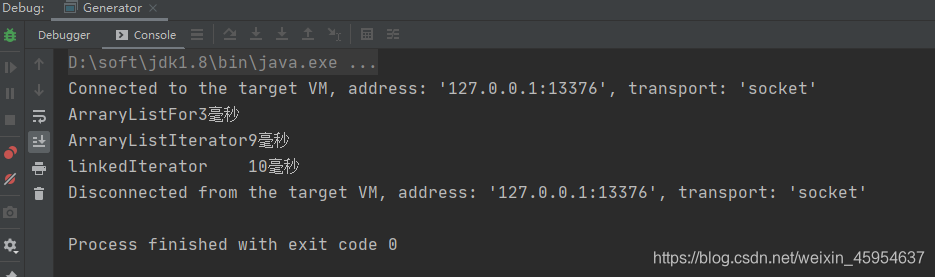
当数据量大于50万的时候,
则ArraryList for > ArraryList Iterator > LinkedList Iterator > LinkedList for
从测试结果来看,ArraryList的for循环遍历确实优于Iterator遍历。
注:测试数据性能与机器也有关联,所以数据并不一定很准确。

















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









