







 本文详细介绍了机器学习中的高维数据降维方法,包括主成分分析(PCA)、奇异值分解(SVD)、线性判别分析(LDA)、局部线性嵌入(LLE)和拉普拉斯特征映射(LE)。通过Iris数据集实例展示了这些方法如何将数据从高维降至低维,同时保持数据的分类特性,以提高数据可视化和分析效率。
本文详细介绍了机器学习中的高维数据降维方法,包括主成分分析(PCA)、奇异值分解(SVD)、线性判别分析(LDA)、局部线性嵌入(LLE)和拉普拉斯特征映射(LE)。通过Iris数据集实例展示了这些方法如何将数据从高维降至低维,同时保持数据的分类特性,以提高数据可视化和分析效率。
文章目录
前言
高维数据降维是指采用某种映射方法,降低随机变量的数量,例如将数据点从高维空间映射到低维空间中,从而实现维度减少。降维分为特征选择和特征提取两类,前者是从含有冗余信息以及噪声信息的数据中找出主要变量,后者是去掉原来数据,生成新的变量,可以寻找数据内部的本质结构特征。
降维的过程是通过对输入的原始数据特征进行学习,得到一个映射函数,实现将输入样本映射后到低维空间中之后,原始数据的特征并没有明显损失,通常情况下新空间的维度要小于原空间的维度。且前大部分降维算法是处理向量形式的数据。
本文列举了常用的一些降维方法,包括:无监督线性降维方法PCA;协助PCA的奇异值分解;有监督的线性降维算法LDA;非线性流形算法LLE与LE。
1.主成分分析(PCA)
2.奇异值分解(SVD)
3.线性判别分析(LDA)
4.局部线性嵌入(LLE)
5.拉普拉斯特征映射(LE)
一、主成分分析(PCA)
1.说明
主成分分析( Principal Component Analysis, PCA)是最常用的线性降维方法,在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。PCA是不考虑样本类别输出的无监督降维技术,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的方差最大,以此使用较少的维度,同时保留较多原数据的维度。
举个例子,如下图,将数据从二维降维到一维。希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,u1和u2,从直观上可以看出,u1比u2好,可以解释为一是样本点到这个直线的距离足够近,2二是样本点在这个直线上的投影能尽可能的分开。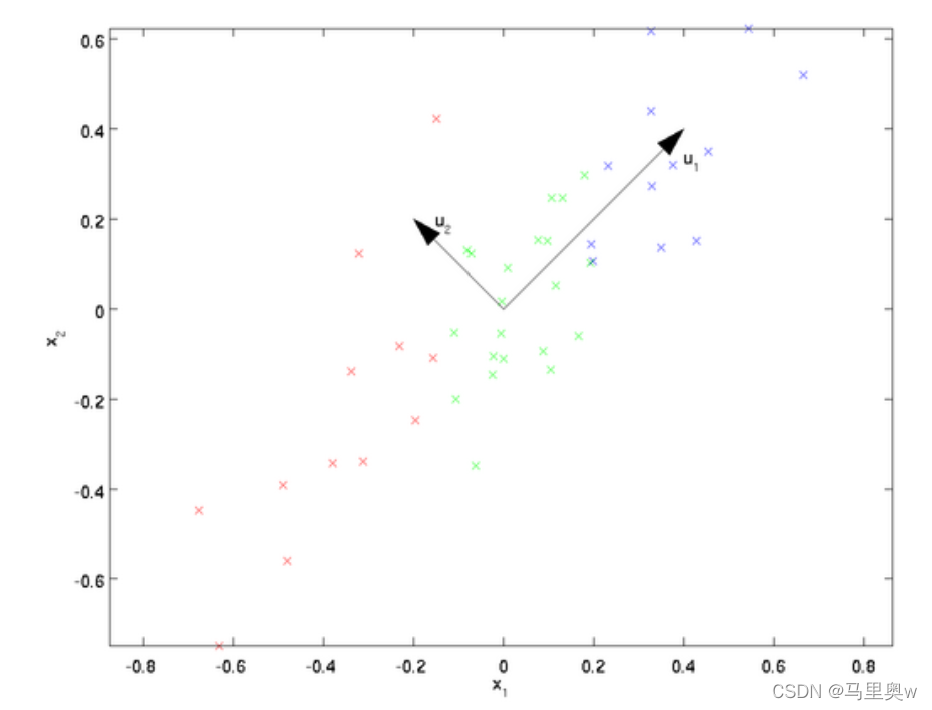
所以可以解释希降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。
PCA 算法目标是求出样本数据的协方差矩阵的特征值和特征向量,而协方差矩阵的特征向量的方向就是PCA 需要投影的方向。使样本数据向低维投影后,能尽可能表征原始的数据。
2.【例1】基于主成分分析对 Iris 数据集降维:
本文章使用sklearn库中的Iris 数据集来进行数据降维实验。
该数据集特征包括鸢尾花的花萼长度、花萼宽度、花辦长度和花瓣觉度 4 个属性,还有列保存了鸢尾花的类型结果。
a.先查看数据的分布情况
#查看数据的分布情况:
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn import datasets
data = datasets.load_iris()
X =data['data']
y =data['target']
ax = Axes3D(plt.figure())
for c, i, target_name in zip('rgb', [0, 1, 2], data.target_names):
ax.scatter(X[y==i, 0], X[y==i, 3], c=c, label=target_name)
ax.set_xlabel(data.feature_names[0])
ax.set_xlabel(data.feature_names[1])
ax.set_xlabel(data.feature_names[2])
ax.set_xlabel(data.feature_names[3])
ax.set_title('Iris')
plt.legend()
plt.show()
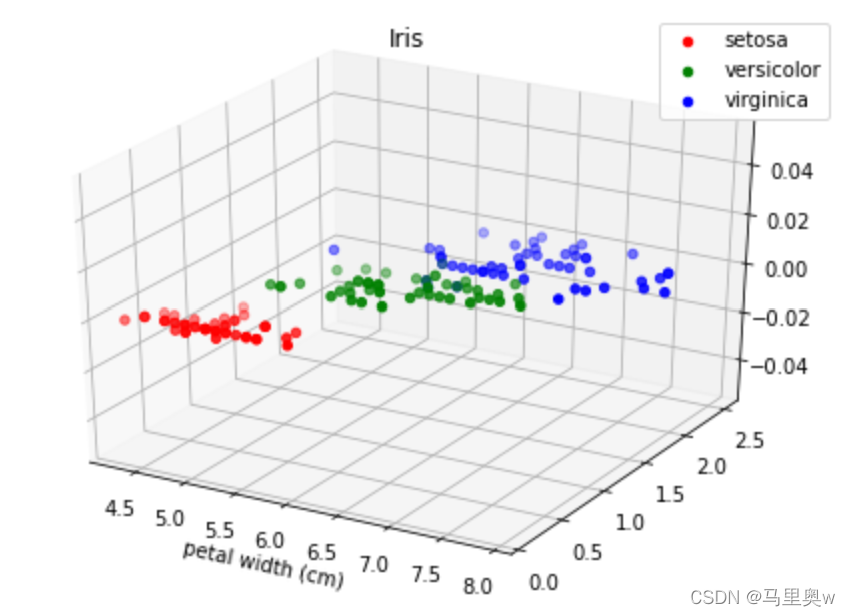
可以发现红色数据点,也就是Setosa距离其他数据较远。
b.用pca将原本的数据降为二维,并在平面中画出样本点的分布。
#利用PCA将数据降到二维:
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
data=load_iris()
y=data.target
x=data.data
pca=PCA(n_components=2) #设置降维后的主成分数目为2。
reduced_x=pca.fit_transform(x)
red_x,red_y=[],[]
blue_x,blue_y=[],[]
green_x,green_y=[],[]
for i in range(len(reduced_x)):
if y[i] ==0:
red_x.append(reduced_x[i][0])
red_y.append(reduced_x[i][1])
elif y[i]==1:
blue_x.append(reduced_x[i][0])
blue_y.append(reduced_x[i][1])
else:
green_x.append(reduced_x[i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









