







基于固定单词数量分割
任务:当我们需要数据预处理时,会把一篇文章比如pdf格式的,以每200 words为单位进行分割为样本数据,每个样本数据都是200个words。
缺点:很多样本数据上下文信息不完整。
基于句子切分
原理:首先每次添加一个句子,并判断添加句子后单词总数量是否超过了 200。若没有超过继续添加下一个句子,否则直接结束并保存到样本数据集里面。
优点:每个样本数据都是完整的几个句子,上下文信息保存得很完整。
pypdf2+nltk共同努力
使用pypdf2加载pdf数据,以nltk工具实现基于句子分割,而不是单纯的以200words分割导致的上下文信息不完整。
import csv
from tqdm import tqdm
from PyPDF2 import PdfReader
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize, word_tokenize
# PDF 文件路径
pdf_path = "./data/shakespeare.pdf"
# 输出文件路径
output_txt_path = "./data/shakespeare_samples_nltk.txt"
output_csv_path = "./data/shakespeare_samples_nltk.csv"
# 提取指定页码范围内的文本
def extract_text_from_pdf(pdf_path, start_page, end_page):
"""
从 PDF 提取指定页码范围的文本
"""
text = ""
reader = PdfReader(pdf_path)
for page_num in tqdm(range(start_page - 1, end_page), desc="提取指定页码范围内的文本"): # 页码从0开始
page = reader.pages[page_num]
text += page.extract_text() + " "
return text
# 按句子分割并生成样本
def split_by_sentences(text, words_per_sample=200):
"""
使用句子分割方法生成样本,每个样本约 200 个单词
"""
sentences = sent_tokenize(text)
samples = []
current_sample = []
current_word_count = 0
for sentence in sentences:
words_in_sentence = word_tokenize(sentence)
if current_word_count + len(words_in_sentence) <= words_per_sample:
current_sample.extend(words_in_sentence)
current_word_count += len(words_in_sentence)
else:
samples.append(" ".join(current_sample))
current_sample = words_in_sentence
current_word_count = len(words_in_sentence)
# 处理最后的样本
if current_sample:
samples.append(" ".join(current_sample))
return samples
# 保存样本数据到TXT文件
def save_samples_to_txt(samples, output_path):
"""
保存样本数据到 TXT 文件
"""
with open(output_path, "w", encoding="utf-8") as txt_file:
for sample in tqdm(samples, desc="保存样本数据到TXT文件"):
txt_file.write(sample + "\n")
# 保存样本数据到CSV文件
def save_samples_to_csv(samples, output_path):
"""
保存样本数据到 CSV 文件
"""
with open(output_path, "w", newline="", encoding="utf-8") as csv_file:
writer = csv.writer(csv_file)
writer.writerow(["id", "text"]) # 写入表头
for idx, sample in tqdm(enumerate(samples), desc="保存样本数据到CSV文件"):
writer.writerow([idx + 1, sample])
# 主流程
if __name__ == "__main__":
# 页码范围
start_page = 134
end_page = 140 # 示例页码,可根据实际需求调整
# 提取文本
extracted_text = extract_text_from_pdf(pdf_path, start_page, end_page)
# 按句子分割并生成样本
samples = split_by_sentences(extracted_text, words_per_sample=200)
# 保存到文件
save_samples_to_txt(samples, output_txt_path)
save_samples_to_csv(samples, output_csv_path)
print(f"样本数据已保存到:\nTXT文件: {output_txt_path}\nCSV文件: {output_csv_path}")
示例


结果:可以发现每个样本数据都是几个完整的句子组成,且总单词数量小于200.
nltk安装问题
报错:[nltk_data] Error loading punkt: <urlopen error [Errno 111] Connection [nltk_data] refused>
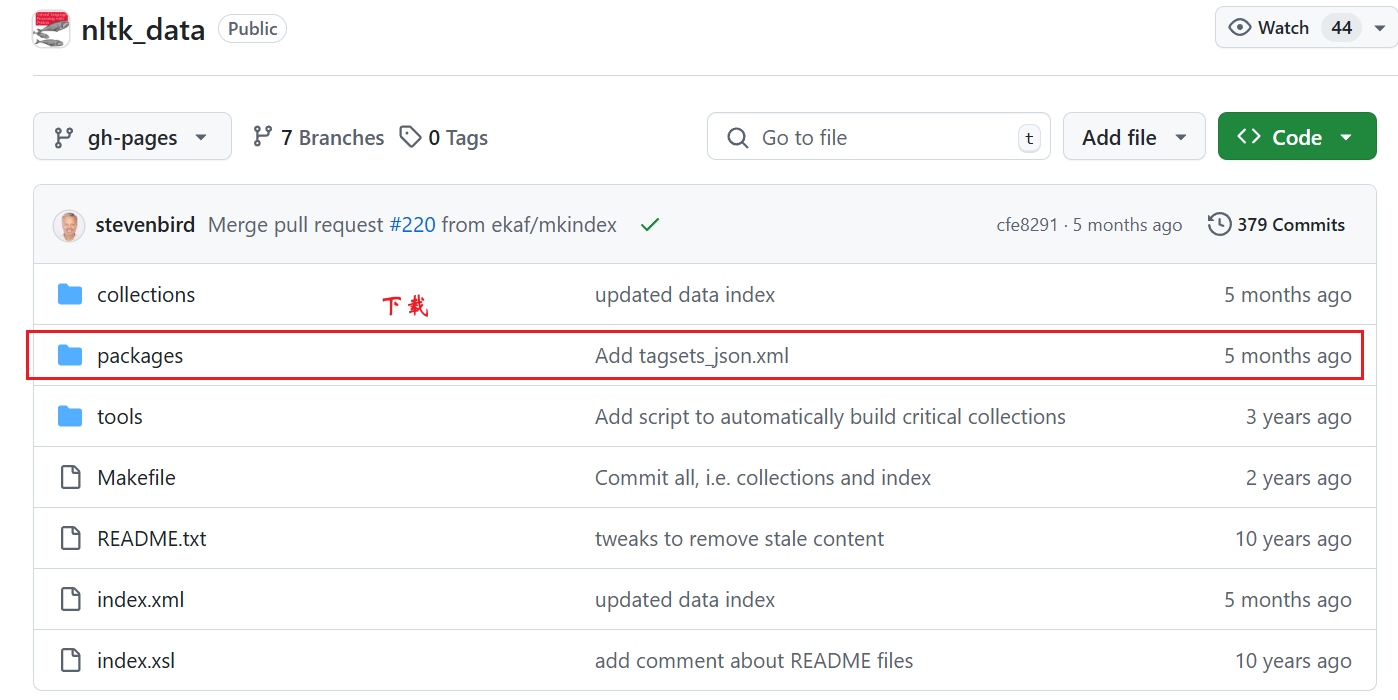
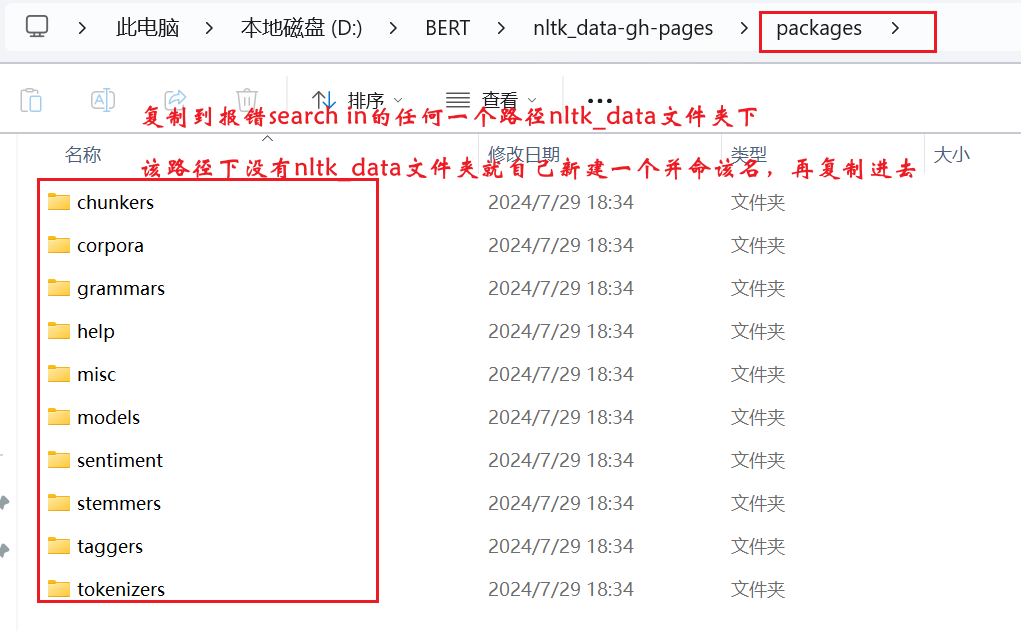
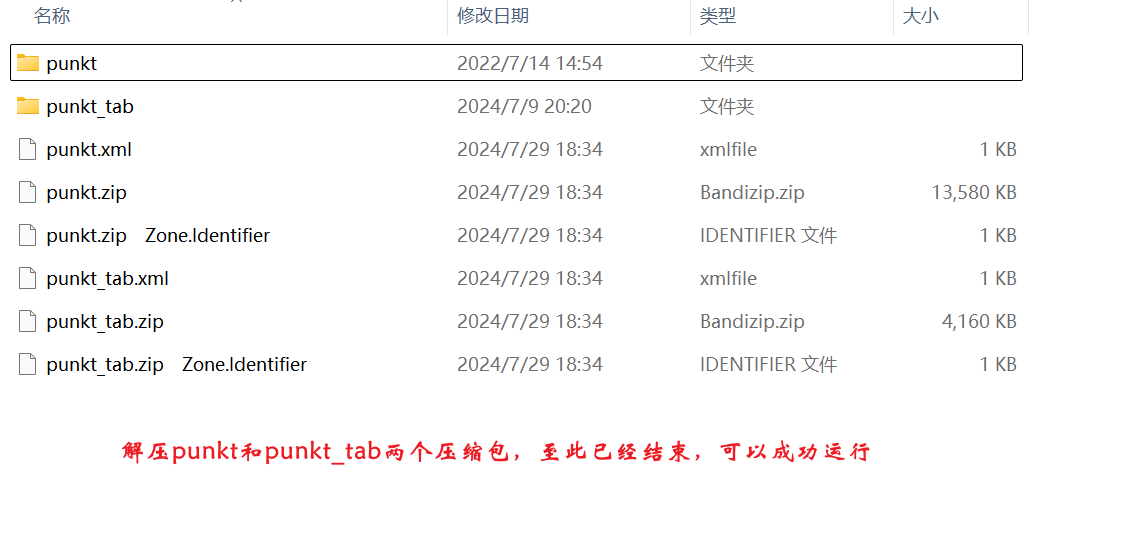
nltk下载安装问题:需要手动github下载packages整个包,把所有子文件复制到报错信息的searche in任何一个路径下,最后进入tokenizers里面把punkt和punkt_tab都解压即可。
github下载:https://github.com/nltk/nltk_data
比如我的路径:\home\jldai\nltk_data\tokenizers


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









