







Docker学习笔记
一、容器技术概述
1.容器技术发展
问题
业务怎么上云?
- 应用在云端重新部署:以脚本或手工方式在云端重新部署。
- 打包本地已部署应用的系统镜像,通过P2V/V2V等方式上传到云端运行。
应用打包困难
- 因本地环境与云端环境不一致,用户须为每种语言、框架乃至每个版本的应用维护一个打好的包。而打包过程中,需要进行大量修改、配置、试错才能使本地应用运行环境和云端环境匹配。
解决
Docker镜像
- 容器镜像打包了应用及其依赖(包含完整操作系统的所有文件和目录)。
- 容器镜像包含了应用运行所需要的所有依赖。只需在隔离的“沙盒”中运行该镜像,无需进行任何修改和配置即可运行应用。
- 容器镜像核心在于实现应用及其运行环境整体打包以及打包格式统一。实现本地环境与云端环境的高一致性。
Docker&VM
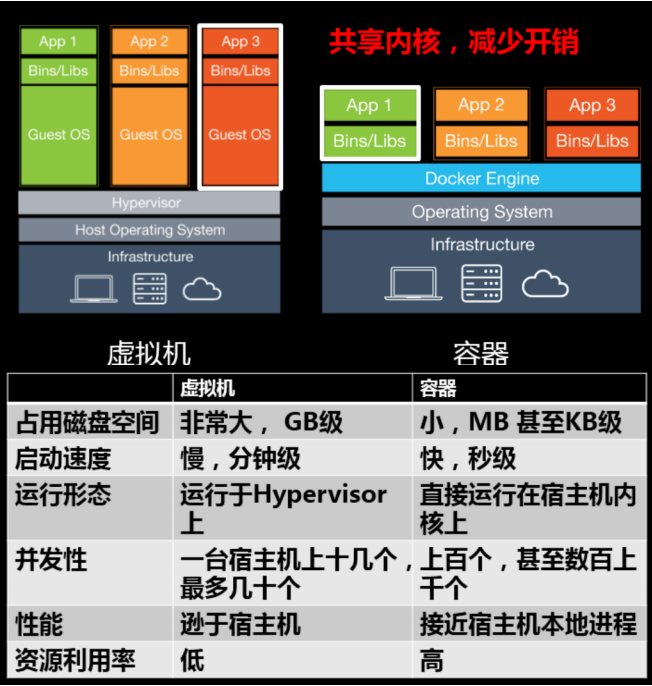
虚拟机:隔离出很多“子电脑”,占用空间大,启动慢。
容器:不需要虚拟出整个操作系统,只需要虚拟一个小规模的环境(类似“沙箱”)。 启动时间很快,对资源的利用率很高(一台主机可以同时运行几千个 Docker容器)。
为什么Docker比 VM 快
(1)docker有着比虚拟机更少的抽象层。由于docker不需要Hypervisor实现硬件资源虚拟化,运行在docker容器上的程序直接使用的都是实际物理机的硬件资源。因此在CPU、内存利用率上docker将会在效率上有明显优势。
(2)docker利用的是宿主机的内核而不需要Guest OS。因此当新建一个容器时,docker不需要和虚拟机 一样重新加载一个操作系统内核。避免引寻、加载操作系统内核这个比较费时费资源的过程,当新建一个虚拟机时,虚拟机软件需要加载Guest OS,这个新建过程是分钟级别的。而docker由于直接利用宿主机的操作系统,省略了返个过程,因此新建一个docker容器只需要几秒钟。
(更详细的解释见容器镜像结构)
2.容器技术基础
Docker架构
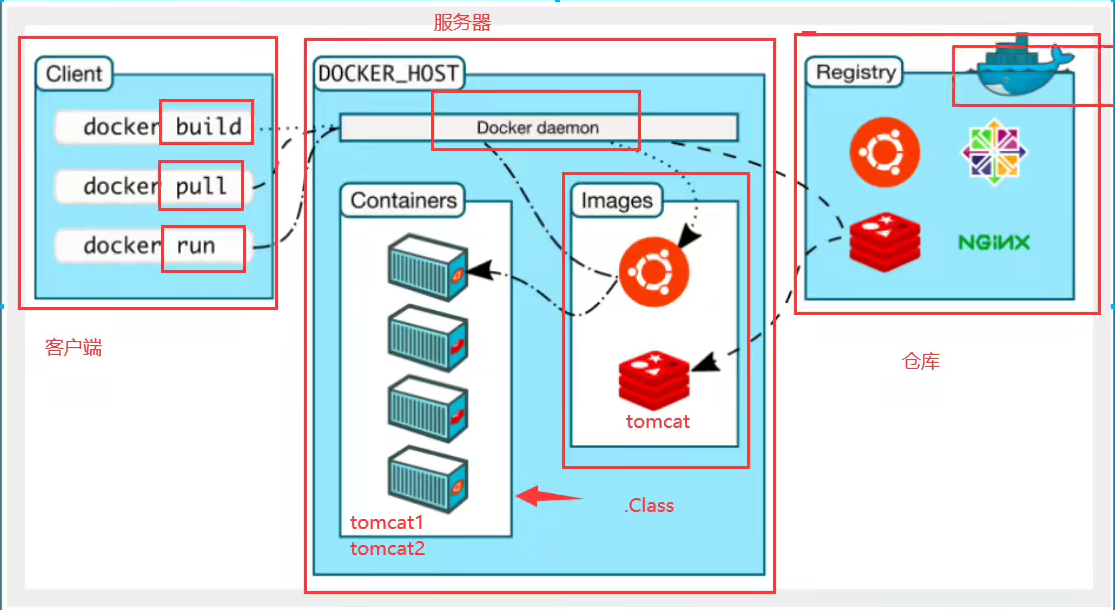
镜像和容器的关系就类似于类和对象,例如tomcat镜像 ==> run ==> tomcat1容器(提供服务),容器来提供服务且相互隔离。
仓库(Repository)是集中存放镜像文件的场所。
Docker是怎么工作的
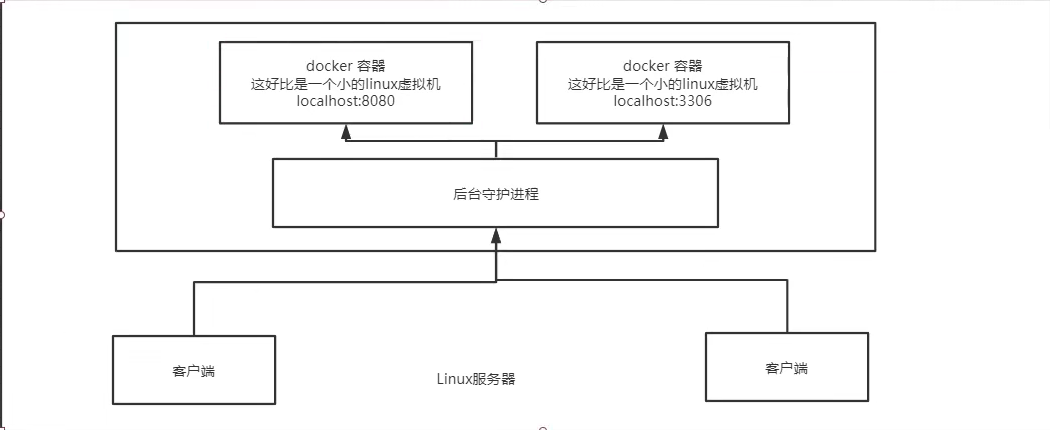
Docker是一个Client-Server结构的系统,Docker守护进程运行在主机上, 然后通过Socket连接从客户端访问,守护进程从客户端接受命令并管理运行在主机上的容器。 容器是一个运行时环境。
3.容器基础操作
(1)基本命令
docker version # 显示 Docker 版本信息。
docker info # 显示 Docker 系统信息,包括镜像和容器数。。
docker --help # 帮助
(2)镜像操作
查看镜像

# 同一个仓库源可以有多个TAG,代表这个仓库源的不同版本,使用REPOSITORY:TAG 定义不同的镜像,如果不定义镜像的标签版本,docker将默认使用lastest 镜像
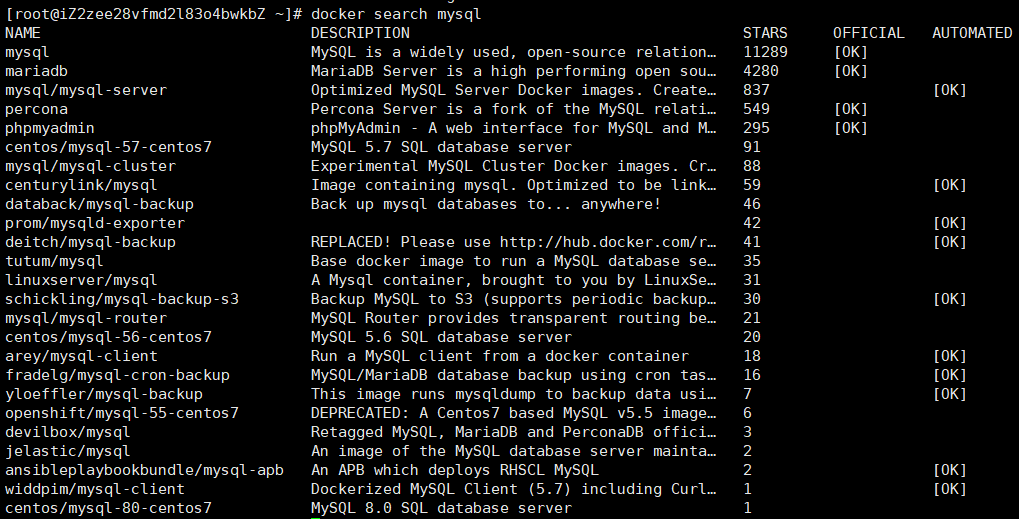
从Docker Hub仓库中搜索镜像
获取镜像
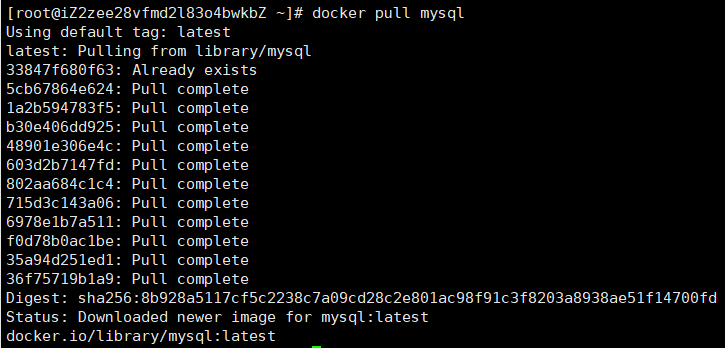
# 指定版本下载
docker pull mysql:5.7
删除镜像

(3)容器操作
新建容器并启动(有镜像才能建容器)
# 命令
docker run [参数] IMAGE [COMMAND][ARG...]
# 常用参数
--name="Name" # 给容器指定一个名字
-d # 后台方式运行容器,并返回容器的id
-i # 以交互模式运行容器,通过和 -t 一起使用
-t # 给容器重新分配一个终端,通常和 -i 一起使用
-P # 随机端口映射(大写)
-p # 指定端口映射(小结),一般可以有四种写法
ip:hostPort:containerPort
ip::containerPort
hostPort:containerPort (常用,如8080:80)
containerPort
# 新建容器并进入
docker run -it centos /bin/bash
# 退出容器
exit
# 容器不停止退出
ctrl+P+Q
注意:端口映射完要去你的服务器安全组把这个端口放行,然后用服务器公网ip:端口号即可访问
例如:

现在做了一个8088到9000的映射,Portainer是一个可视化界面
先去阿里云安全组放行8088(注意不是9000,9000是容器端口号)

可以先在docker中本机访问测试一下:
curl localhost:8088
在浏览器需要使用公网ip:端口号去访问:
列出所有运行的容器
# 命令
docker ps [参数]
# 常用参数
-a # 列出当前所有正在运行的容器 + 历史运行过的容器
-l # 显示最近创建的容器
-n=? # 显示最近n个创建的容器
-q # 静默模式,只显示容器编号。

启动&停止
docker start (容器id or 容器名) # 启动容器
docker restart (容器id or 容器名) # 重启容器
docker stop (容器id or 容器名) # 停止容器
docker kill (容器id or 容器名) # 强制停止容器
删除容器
docker rm 容器id # 删除指定容器
docker rm -f $(docker ps -a -q) # 删除所有容器
docker ps -a -q|xargs docker rm # 删除所有容器
后台启动容器
# 命令
docker run -d 容器名
# 问题:Docker容器后台运行,就必须有一个前台进程,容器运行的命令如果不是那些一直挂起的命令,就会自动退出。
# 比如,你运行了nginx服务,但是docker前台没有运行应用,这种情况下,容器启动后,会立即自杀,因为他觉得没有程序了,所以最好的情况是将你的应用使用前台进程的方式运行启动。
查看容器中运行的进程信息
# 命令
docker top 容器id
查看容器/镜像的元数据
# 命令
docker inspect 容器id
进入正在运行的容器
# 命令
docker exec -it 容器id 命令行

# 命令
docker attach 容器id
# 区别
# exec是在容器中打开新的终端,并且可以启动新的进程(常用)
# attach直接进入容器启动命令的终端,不会启动新的进程
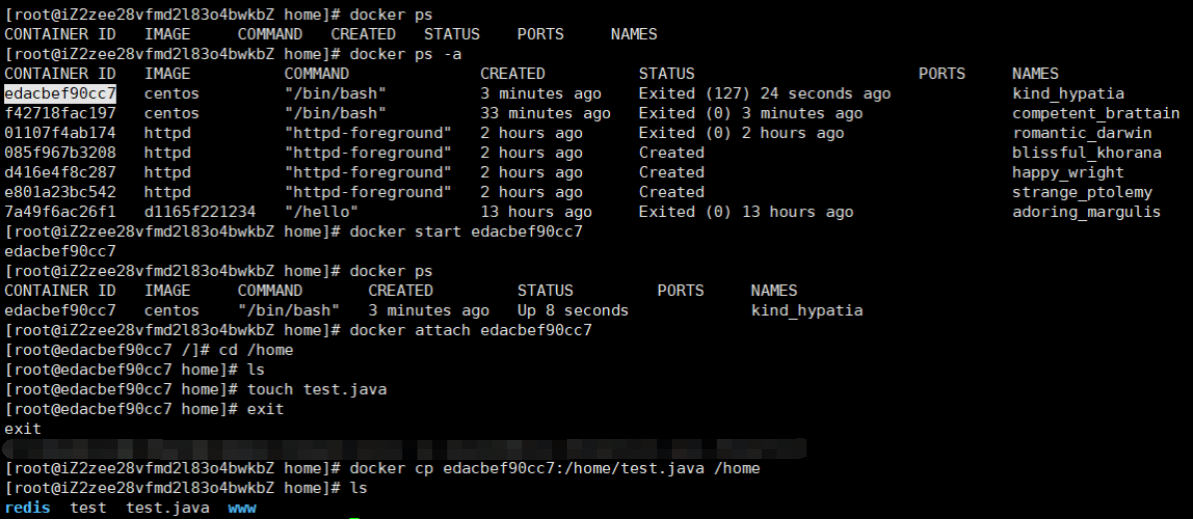
从容器内拷贝文件到主机上
# 命令
docker cp 容器id:容器内路径 目的主机路径
# 新建文件
touch 文件名
二、容器镜像
镜像是一种轻量级、可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码、运行时、库、环境变量和配置文件。
1.容器镜像结构
UnionFS(联合文件系统):Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统, 它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。Union 文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
bootfs(boot file system)主要包含bootloader和kernel,bootloader主要是引导加载kernel,Linux刚启动时会加载bootfs文件系统,在Docker镜像的最底层是bootfs。这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs (root file system) ,在bootfs之上。包含的就是典型 Linux 系统中的 /dev, /proc, /bin, /etc 等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。
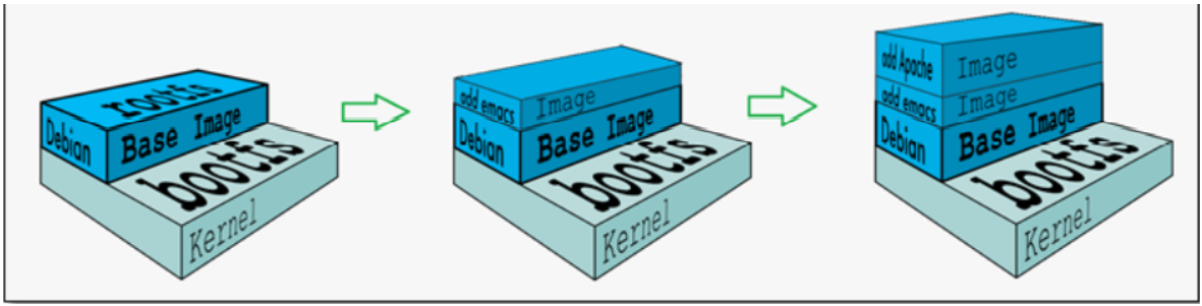
(内核==> 内核 + image ==> 内核 + image + image ==> ...)
对于一个精简的OS,rootfs可以很小,只需要包含最基本的命令,工具和程序库就可以了,因为底层直接用Host的kernel,自己只需要提供rootfs就可以了。由此可见对于不同的Linux发行版,bootfs基本是一致的,rootfs会有差别,因此不同的发行版可以公用bootfs。
这也就解释了为什么容器启动比虚拟机快这么多,虚拟机每次启动都要加载bootfs,而容器使用宿主机内核,只用加载rootfs即可。

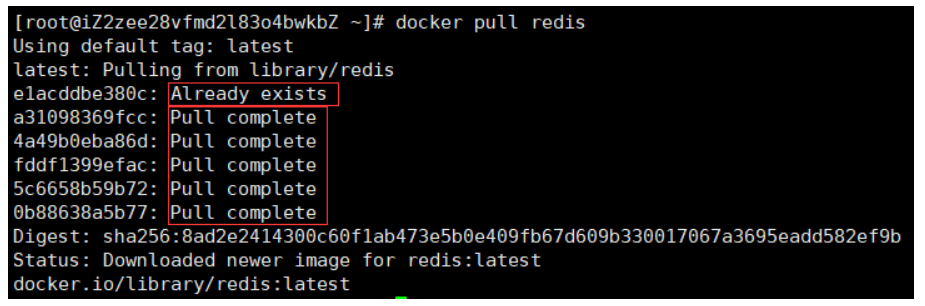
由于采用UnionFS,不难理解docker在拉取镜像时是一层层拉,如果需要拉的部分已经存在(比如我之前已经拉过centos了,而当前镜像的某一层也是centos,他就不会再去拉了)
所有的 Docker 镜像都起始于一个基础镜像层,当进行修改或增加新的内容时,就会在当前镜像层之 上,创建新的镜像层。在上面我们看到在rootfs中每一层都是一个镜像层,就类似下图结构:
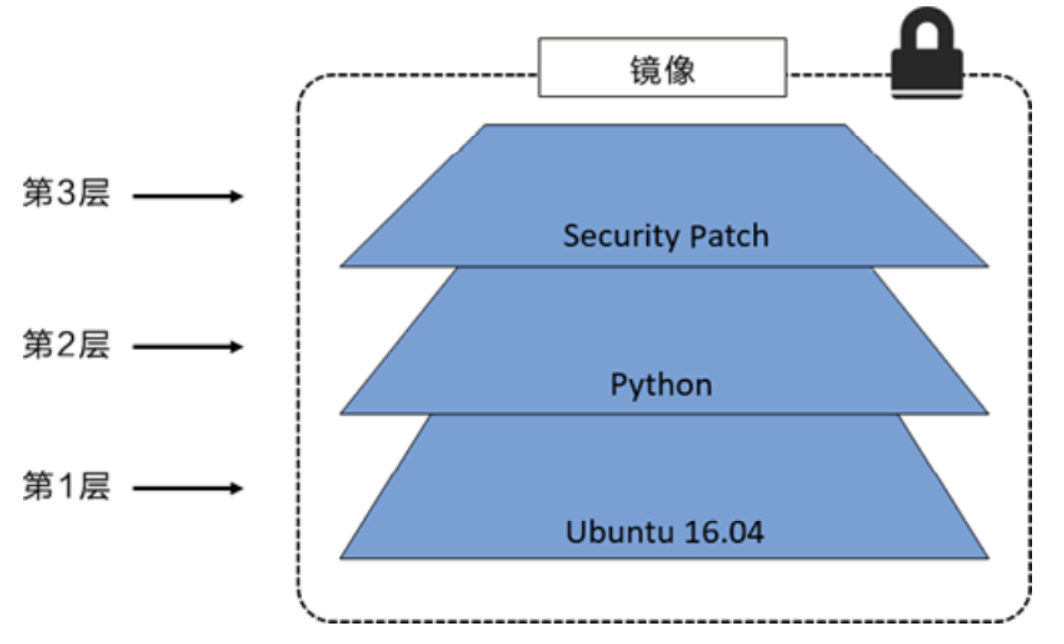
那比如我们要给这个Ubuntu再加一个jdk环境,就再在上面加一个第4层,放上需要的相应文件即可。
Docker镜像都是只读的,当容器启动时,一个新的可写层被加载到镜像的顶部,这一层就是我们通常说的容器层,容器之下的都叫镜像层:
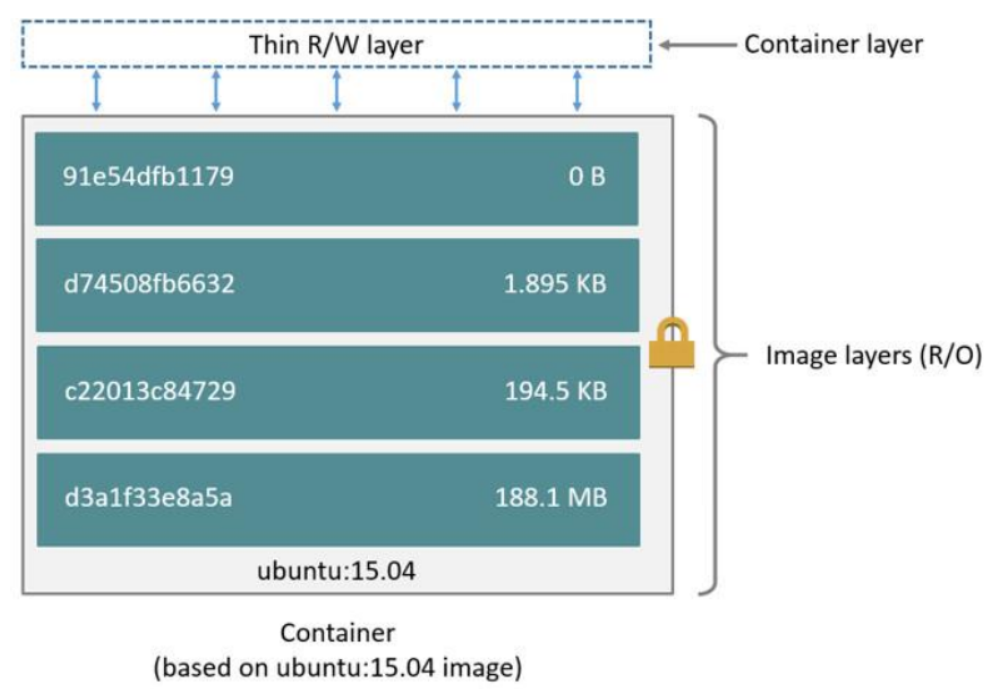
如果某层的某个文件是另一层同类文件的更新版本就会进行覆盖,如:
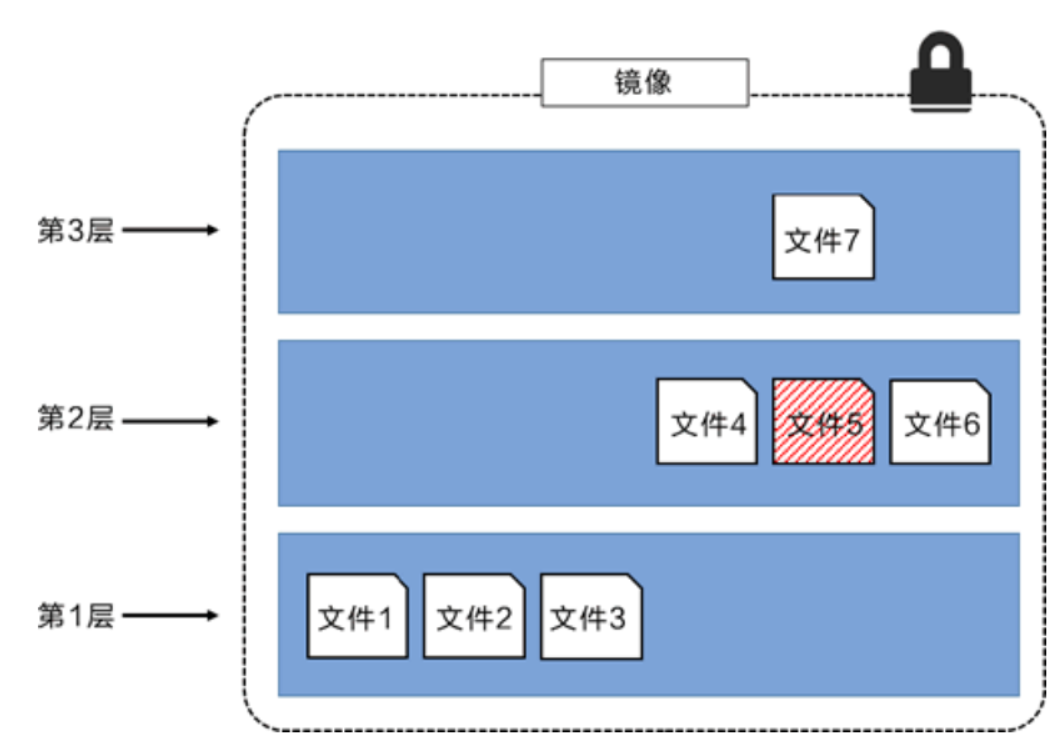
但是从外面看过来只能看到一个统一的视图,这也正是UnionFS的特性:
每一个镜像层都是Linux操作系统文件与目录的一部分。在使用镜像时,docker会将所有的镜像层联合挂载到一个统一 的挂载点上,表现为一个完整的Linux操作系统供容器使用。
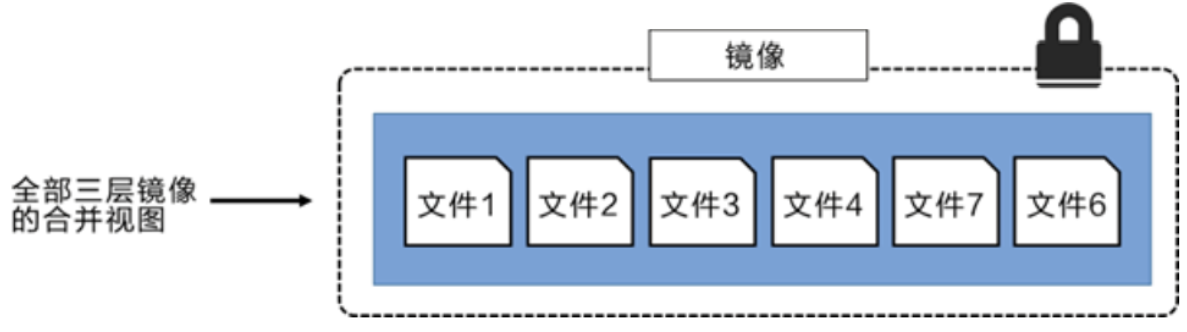
这通常用于通过容器层对镜像层更新,即在加了容器层进行修改后再打包成一个完整镜像。
2.构建容器镜像
(1)commit
# docker commit 提交容器副本使之成为一个新的镜像
docker commit -m="提交的描述信息" -a="作者" 容器id 要创建的目标镜像名:[标签名]
例:我们拉一个tomcat镜像,创建容器并进入后往webapps底下随便放点东西,然后提交为一个新的镜像:

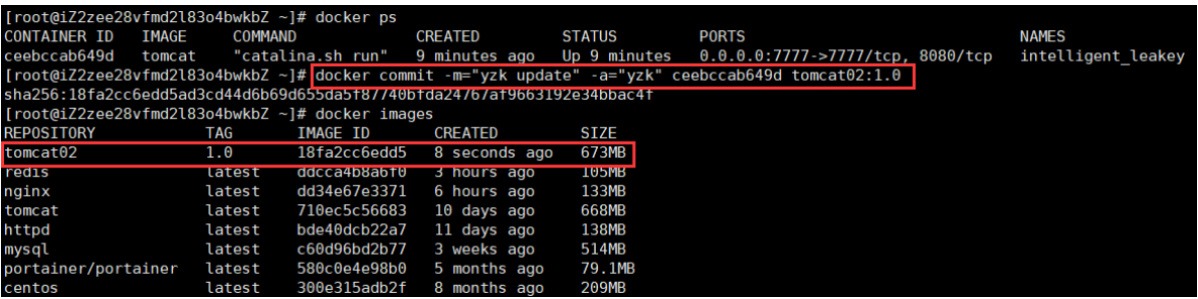
(2)Dockerfile
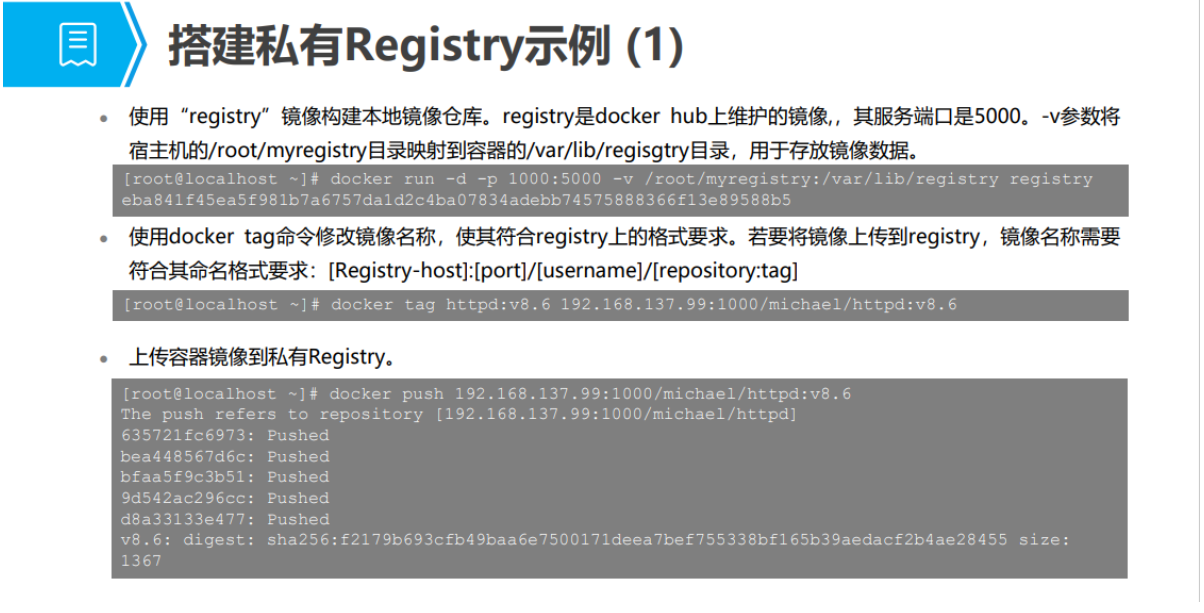
实际开发运维中的流程:开发应用 => Dockerfile => 打包为镜像 => 上传到仓库(私有仓库,公有仓库)=> 下载镜像 => 启动运行
Dockerfile是用来构建Docker镜像的构建文件,是由一系列命令和参数构成的脚本。
构建步骤
流程:
1、docker从基础镜像运行一个容器
2、执行一条指令并对容器做出修改
3、执行类似 docker commit 的操作提交一个新的镜像层
4、Docker再基于刚提交的镜像运行一个新容器
5、执行Dockerfile中的下一条指令直到所有指令都执行完成
1)编写Dockerfile文件
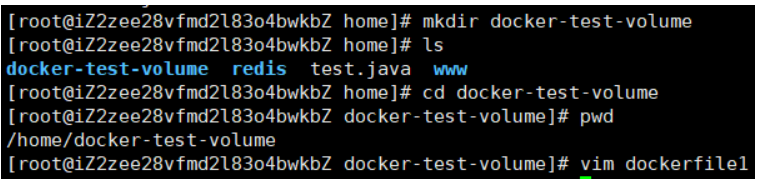
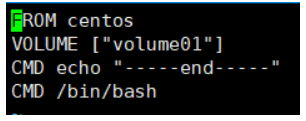
2)docker build 构建镜像
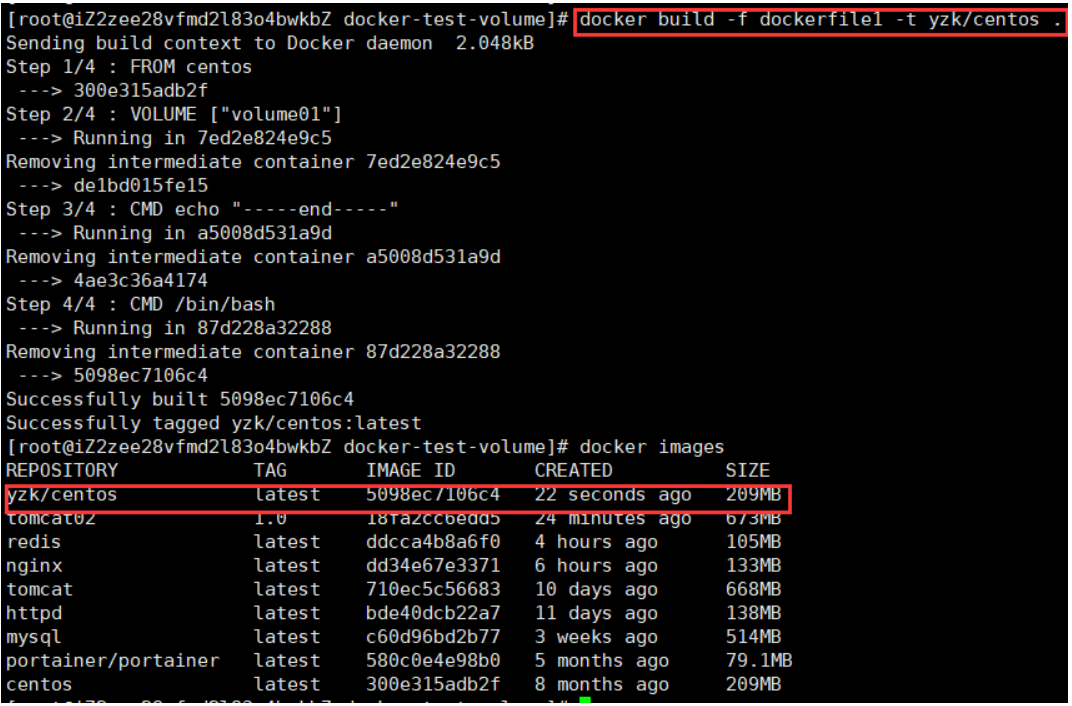
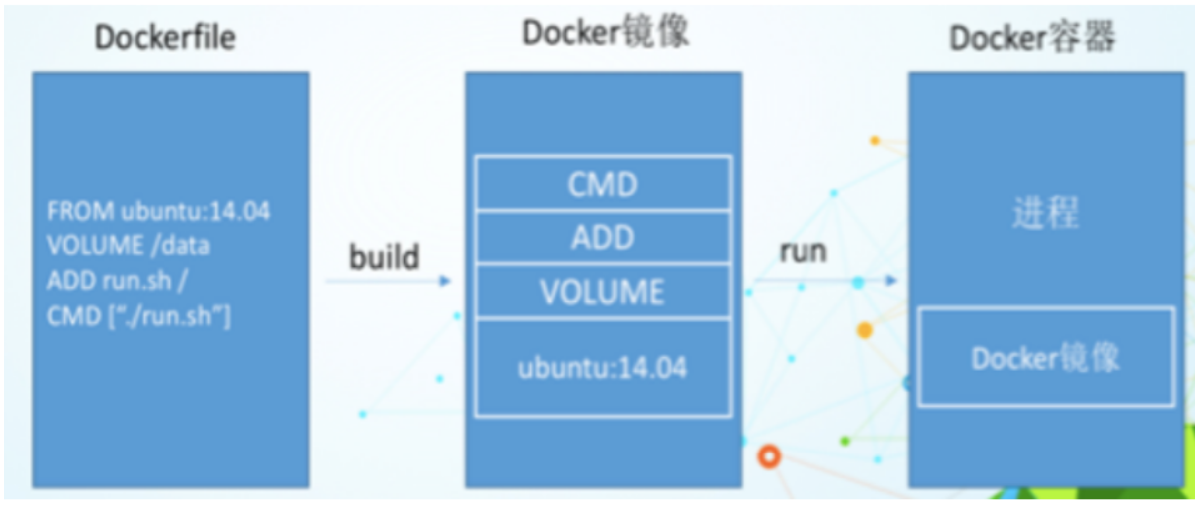
Dockerfile指令
FROM # 基础镜像,当前新镜像是基于哪个镜像的
MAINTAINER # 镜像维护者的姓名混合邮箱地址
RUN # 容器构建时需要运行的命令
EXPOSE # 当前容器对外保留出的端口
WORKDIR # 指定在创建容器后,终端默认登录的进来工作目录,一个落脚点
ENV # 用来在构建镜像过程中设置环境变量
ADD # 将宿主机目录下的文件拷贝进镜像且ADD命令会自动处理URL和解压tar压缩包
COPY # 类似ADD,拷贝文件和目录到镜像中
VOLUME # 容器数据卷,用于数据保存和持久化工作
CMD # 指定一个容器启动时要运行的命令,dockerFile中可以有多个CMD指令,但只有最后一个生效
ENTRYPOINT # 指定一个容器启动时要运行的命令,和CMD一样
ONBUILD # 当构建一个被继承的DockerFile时运行命令,父镜像在被子镜像继承后,父镜像的ONBUILD被触发

3.镜像发布
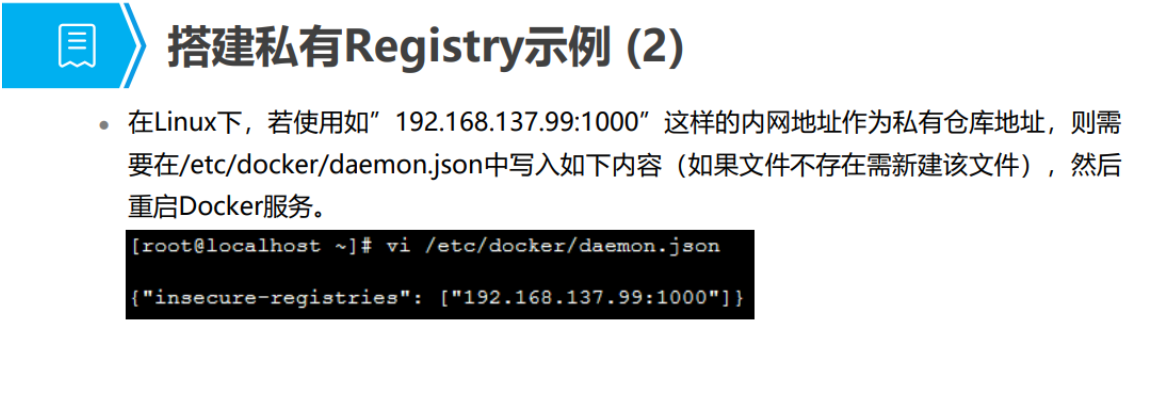
三、容器网络
1.容器网络
(1)docker0
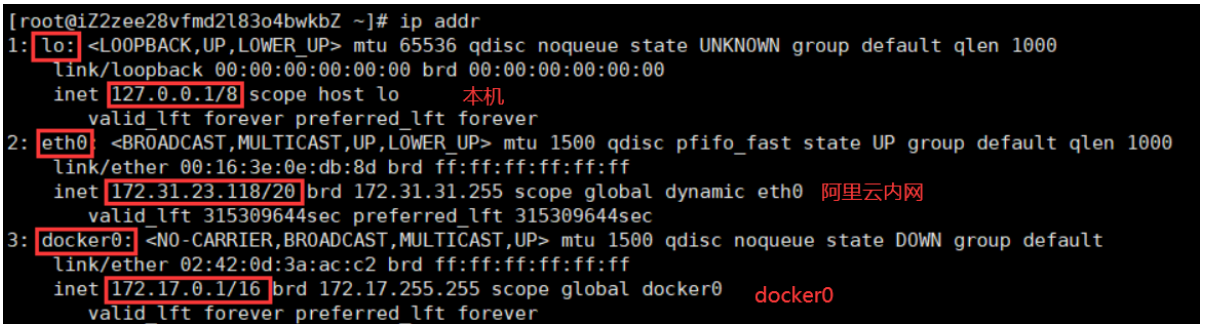
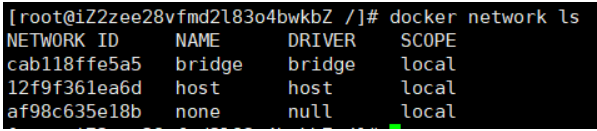
在docker中查看全部网络:
现在我们建一个tomcat的容器,查看内部有哪些网络:
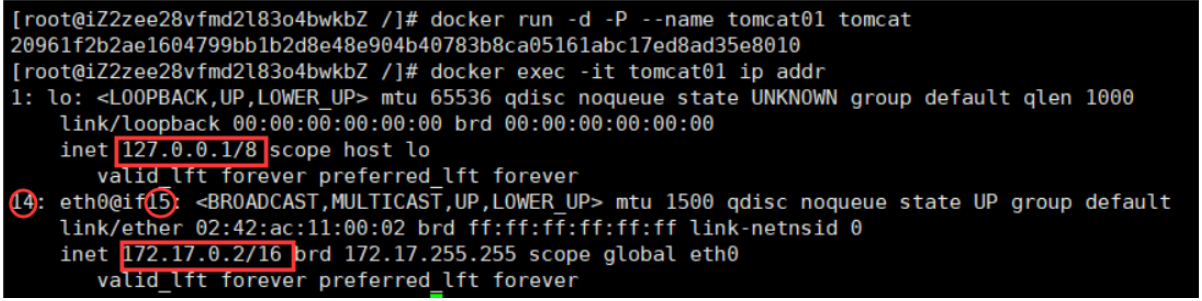
可以看到docker给它分配了一个同一网段下的ip地址eth0@if15,每一个安装了Docker的Linux主机都有一个docker0的虚拟桥接网卡。每启动一个容器,Linux主机就会多了一个虚拟网卡。
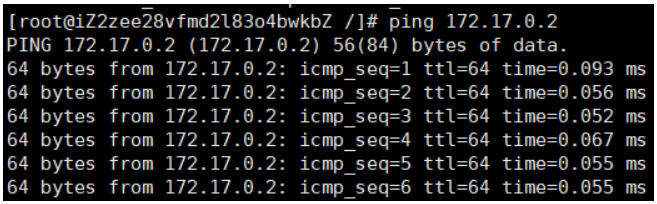
显然Linux是可以直接ping通容器内部的:
这时我们再在docker中查看全部网络:
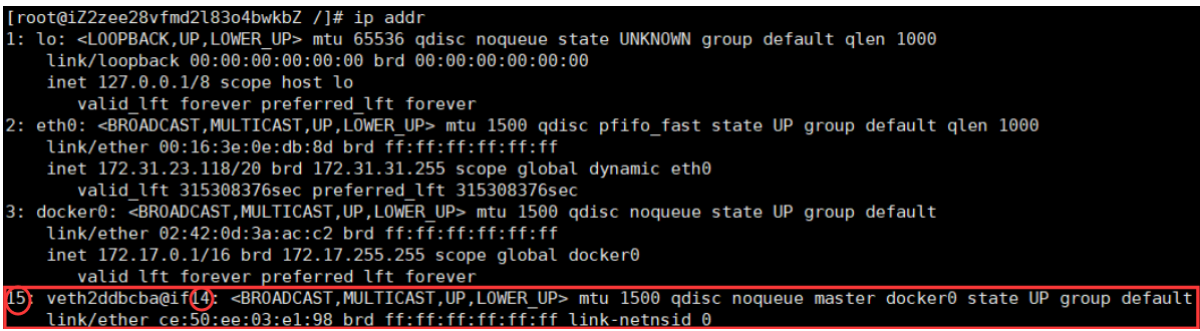
可以看到网卡是成对增加相互匹配的,这就是veth pair技术
veth-pair是一对的虚拟设备接口,它都是成对出现的。一端连着协议栈,一端彼此相连。正因为这个特性,它常常充当一个桥梁,连接着各种虚拟网络设备
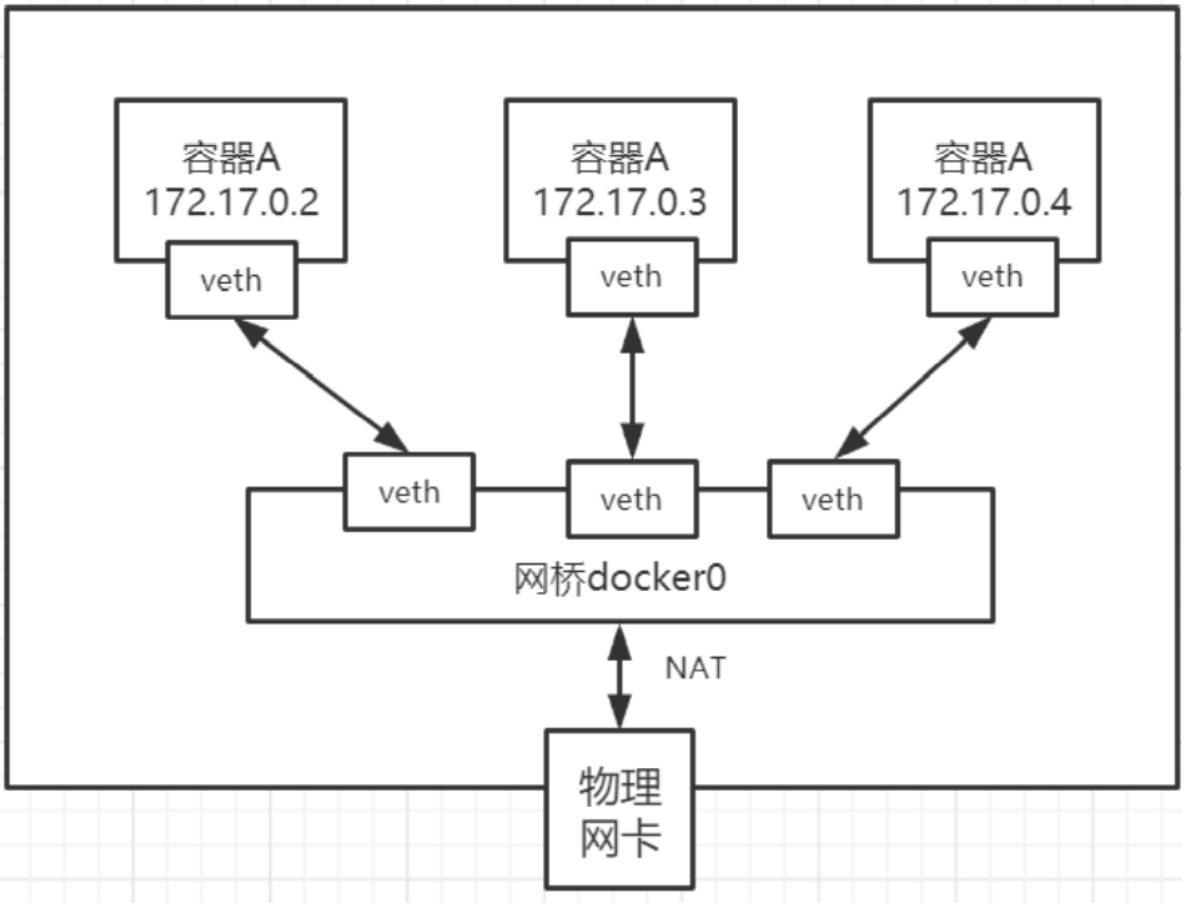
Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信,比如我们再建一个tomcat容器,让刚才的tomcat1来ping它:
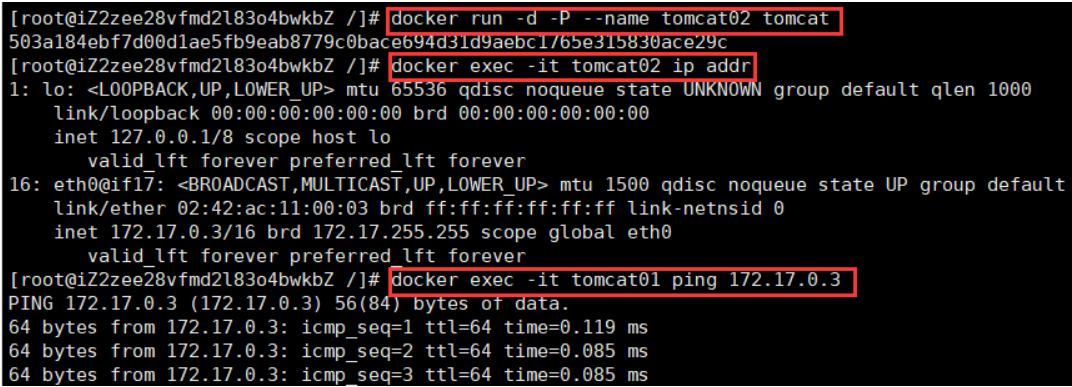
显然容器之间也是可以ping通的,过程如下:
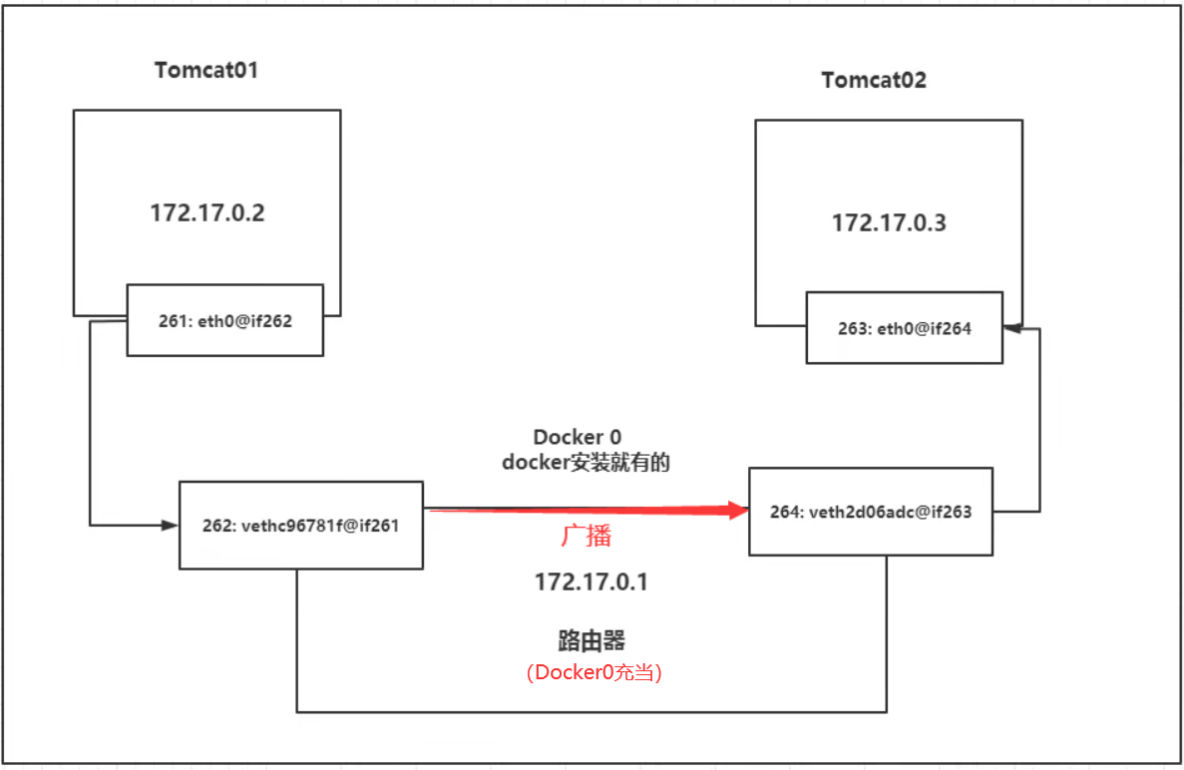
Docker中的网络接口默认都是虚拟的接口。虚拟接口的优势就是转发效率极高(因为Linux是在内核中进行数据的复制来实现虚拟接口之间的数据转发,无需通过外部的网络设备交换),对于本地系统和容器系统来说,虚拟接口跟一个正常的以太网卡相比并没有区别,只是他的速度快很多。
(2)自定义网络
常用网络模式:
1)bridge:默认值,在Docker网桥docker0上为容器创建新的网络栈
2)none:不配置网络
3)host:和宿主机共享网络namespace
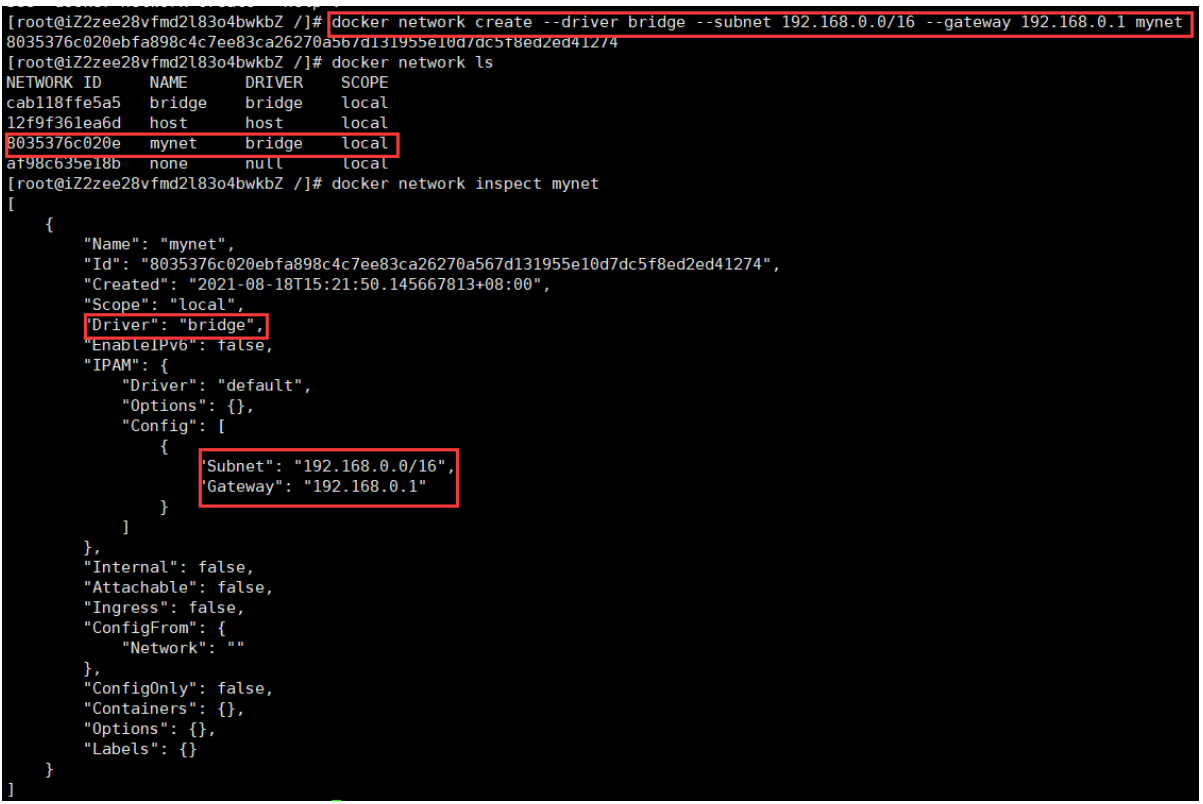
下面来自定义一个网络,配置网络模式、子网范围和网关:
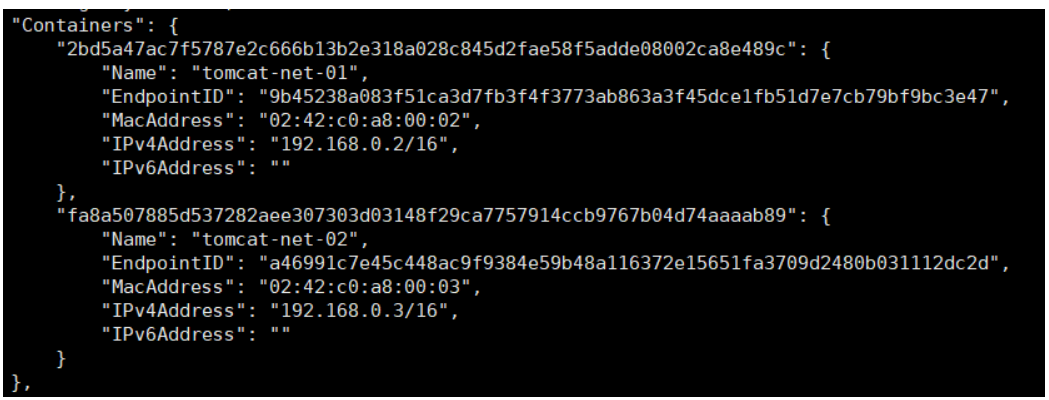
在这个网络下添加两个容器:

可以在自定义网络下看到添加成功:
自定义网络优点(以redis为例):不同的集群使用不同的网络,保证集群的安全性
(3)网络连通
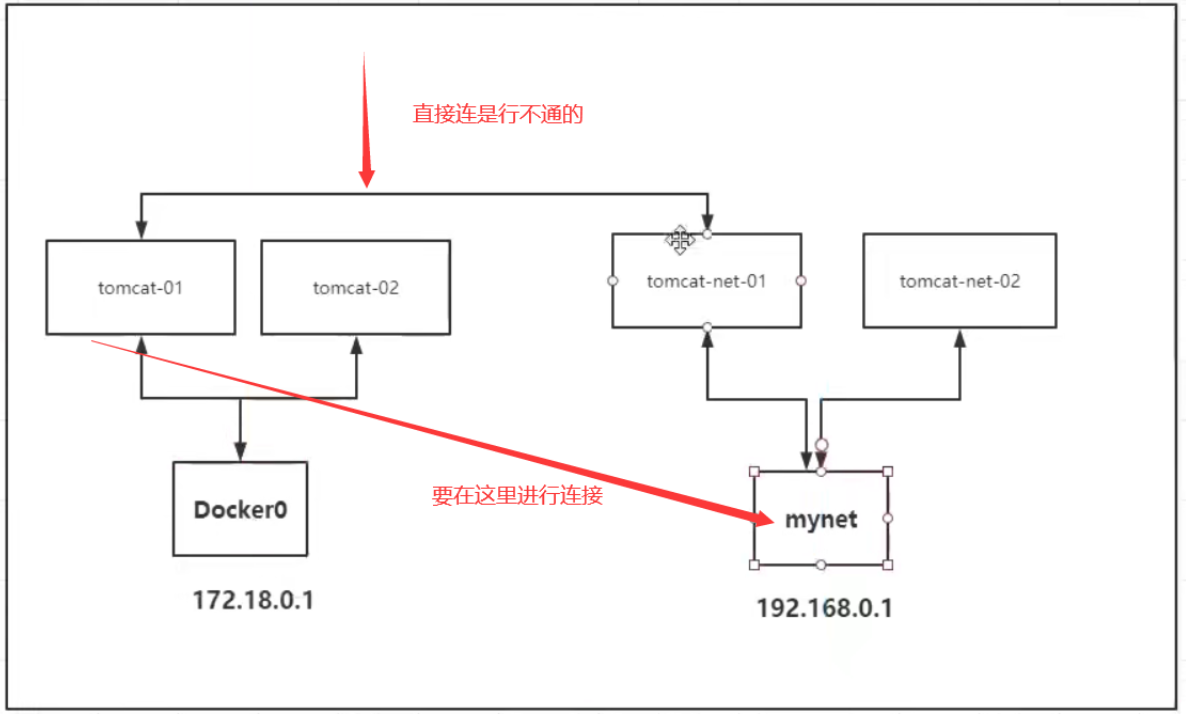
显然容器不可能直接连,而网卡相连会导致网络变化,正确的做法是将容器连到网卡上:

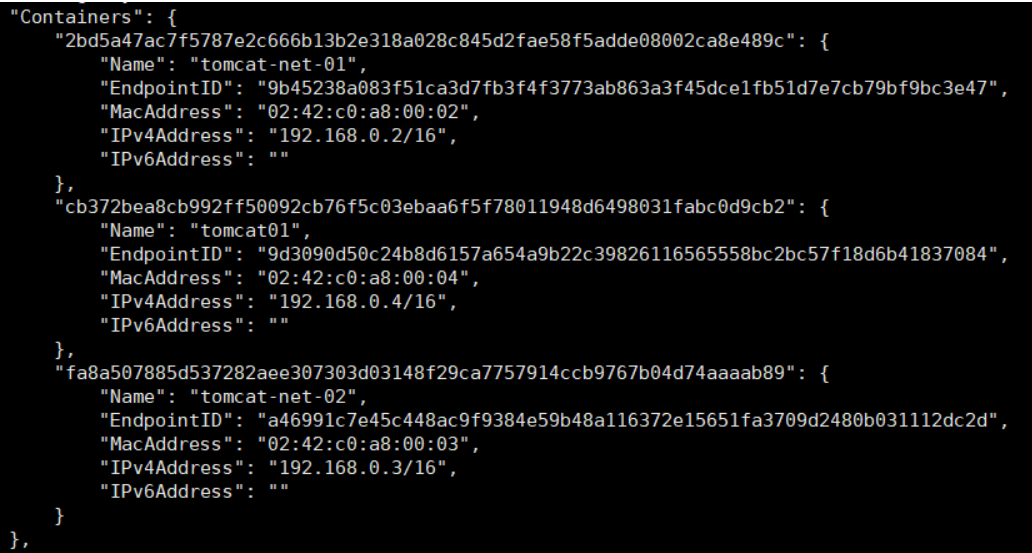
而这个容器在原来的网卡下:
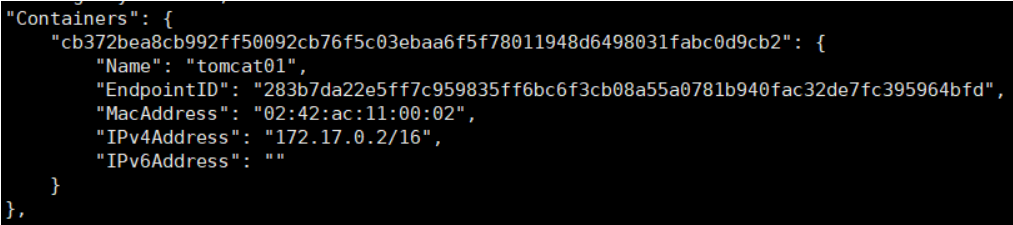
这样一个容器就有了两个ip地址,分属不同的网络
四、容器存储
1.容器数据卷
(1)理念
将应用和运行的环境打包形成容器运行,运行可以伴随着容器,但是我们对于数据的要求,是希望能够持久化的。就好比你安装一个
MySQL,结果你把容器删了就相当于删库跑路了。 所以我们希望容器之间可以共享数据,Docker容器产生的数据,如果不通过docker
commit生成新的镜像,使得数据作为镜像的一部分保存下来,那么当容器删除后,数据自然也就没有了,这样是行不通的。为了能保存
数据在Docker中我们就可以使用卷,让数据挂载到我们本地,这样数据就不会因为容器删除而丢失了。
(2)作用
卷就是目录或者文件,存在一个或者多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能提供一些用于持续存储或共享数
据的特性。卷的设计目的就是数据的持久化,完全独立于容器的生存周期,因此Docker不会在容器删除时删除其挂载的数据卷。
(3)特点
1、数据卷可在容器之间共享或重用数据
2、卷中的更改可以直接生效
3、数据卷中的更改不会包含在镜像的更新中
4、数据卷的生命周期一直持续到没有容器使用它为止
(4)挂载
# 命令
docker run -it -v 宿主机绝对路径目录:容器内目录 镜像名
# 查看数据卷是否挂载成功
docker inspect 容器id
挂载后在容器中创建的文件也会在宿主机中看到,即使停止容器后在宿主机上修改文件,再查看容器中对应的文件,发现数据依旧同步。
(5)具名挂载和匿名挂载
# 匿名挂载
-v 容器内路径
docker run -d -P --name nginx01 -v /etc/nginx nginx
# 匿名挂载的缺点,就是不好维护,通常使用命令 docker volume维护
docker volume ls
# 具名挂载
# 不是/开始就是卷名,是/开始就是目录名
-v 卷名:/容器内路径
docker run -d -P --name nginx02 -v nginxconfig:/etc/nginx nginx
# 改变文件的读写权限
# ro: readonly
# rw: readwrite
# 指定容器对我们挂载出来的内容的读写权限
docker run -d -P --name nginx02 -v nginxconfig:/etc/nginx:ro nginx
docker run -d -P --name nginx02 -v nginxconfig:/etc/nginx:rw nginx
(6)数据卷容器
命名的容器挂载数据卷,其他容器通过挂载这个(父容器)实现数据共享,挂载数据卷的容器,称之为数据卷容器。
容器之间配置信息的传递,数据卷的生命周期一直持续到没有容器使用它为止。 存储在本机的文件则会一直保留。

















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









