






Volatile
Volatile的作用
Volatile的作用:具有多线程间内存可见性,禁止指令重排序,但不具备原子性,在我们的认知中,多线程场景下通常使用锁来实现,但是Java为我们提供了Volatile关键字,在某些场景下比锁使用的更加方便。
下面就Volatile的几个特性来说明其用处:
1、多线程环境下内存可见性
package com.test;
import java.util.concurrent.TimeUnit;
public class ThreadDemo extends Thread {
//声明一个变量
private boolean result = false;
public boolean getResult(){
return result;
}
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
//在线程运行时改变其变量值
result = true;
System.out.println(result);
}
}package com.test;
public class VolatileDemoOne {
public static void main(String[] args) {
ThreadDemo threadDemo = new ThreadDemo();
threadDemo.start();
while (true){
if(threadDemo.getResult()){
System.out.println("11111111");
}
}
}
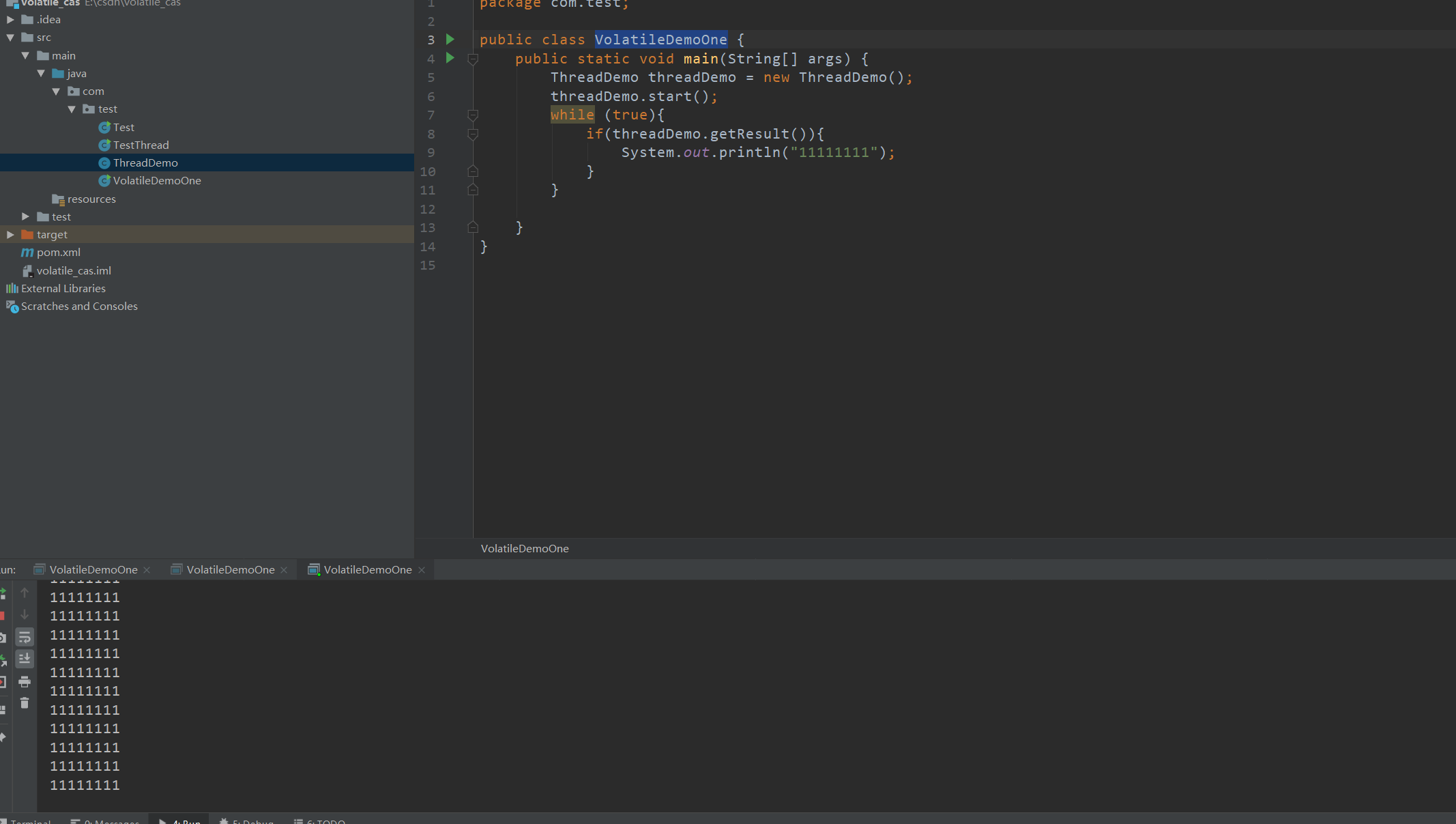
}正常情况下result在线程中已被修改为true,此时控制台将会一直打印11111111,但是此时却没有打印我们预期的结果.这就牵扯到我们的JMM内存模型
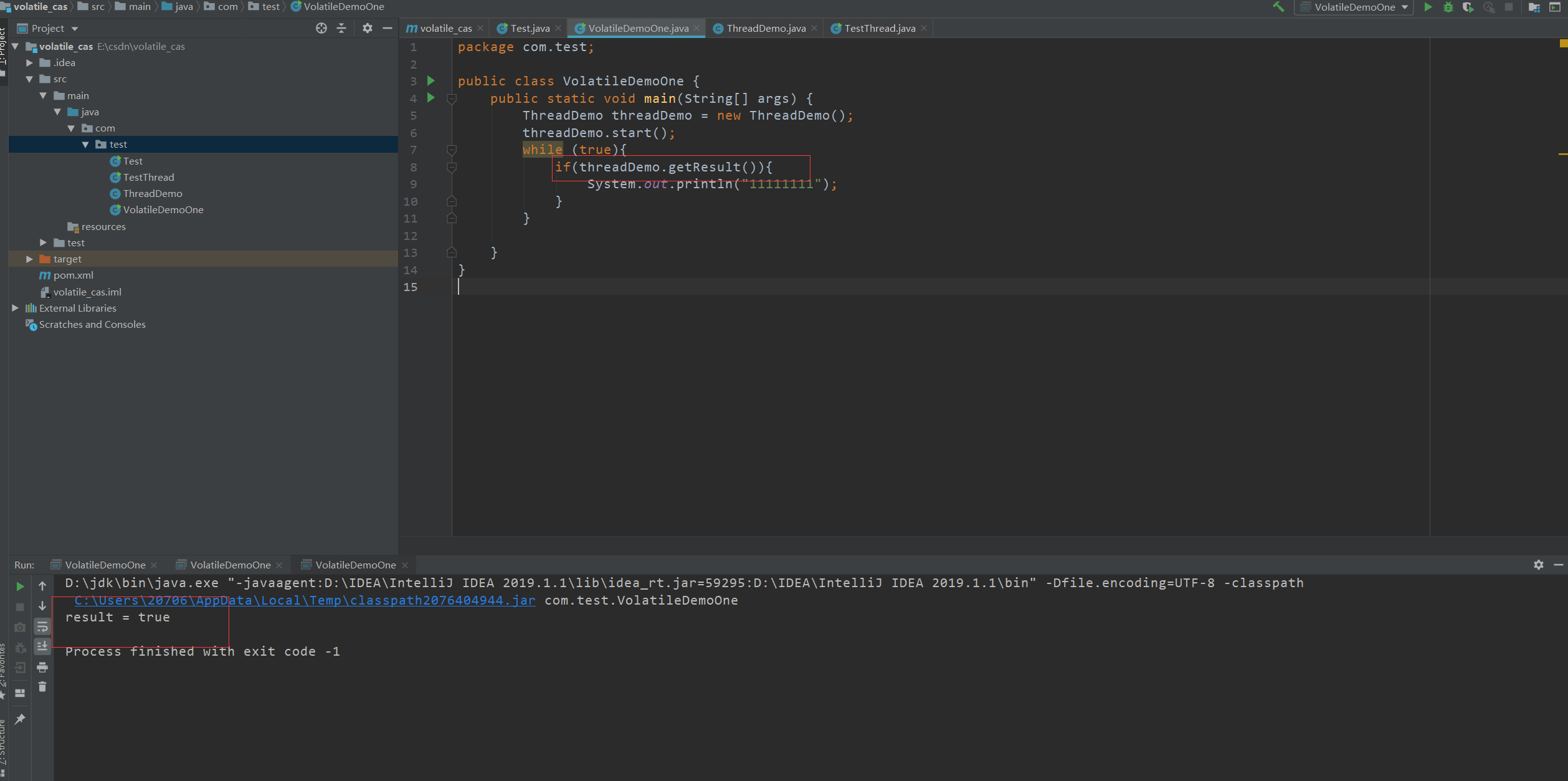
JMM内存模型其实就类似于我们的计算机模型
计算机模型:
在我们现在多核CPU的情况下,多个CPU对我们主内存数据进行读写操作,为了提高其运行速率,将各个cpu读取到的数据存储到与CPU相对应的高速缓存中,这样就实现了各个CPU在自己的高速缓存中对数据进项操作,大大提高了运行效率,为了防止两个高速缓存中的数据不一致问题,计算机采取缓存一致性协议来保证每个CPU对应的高速缓存中的数据与主内存一致。
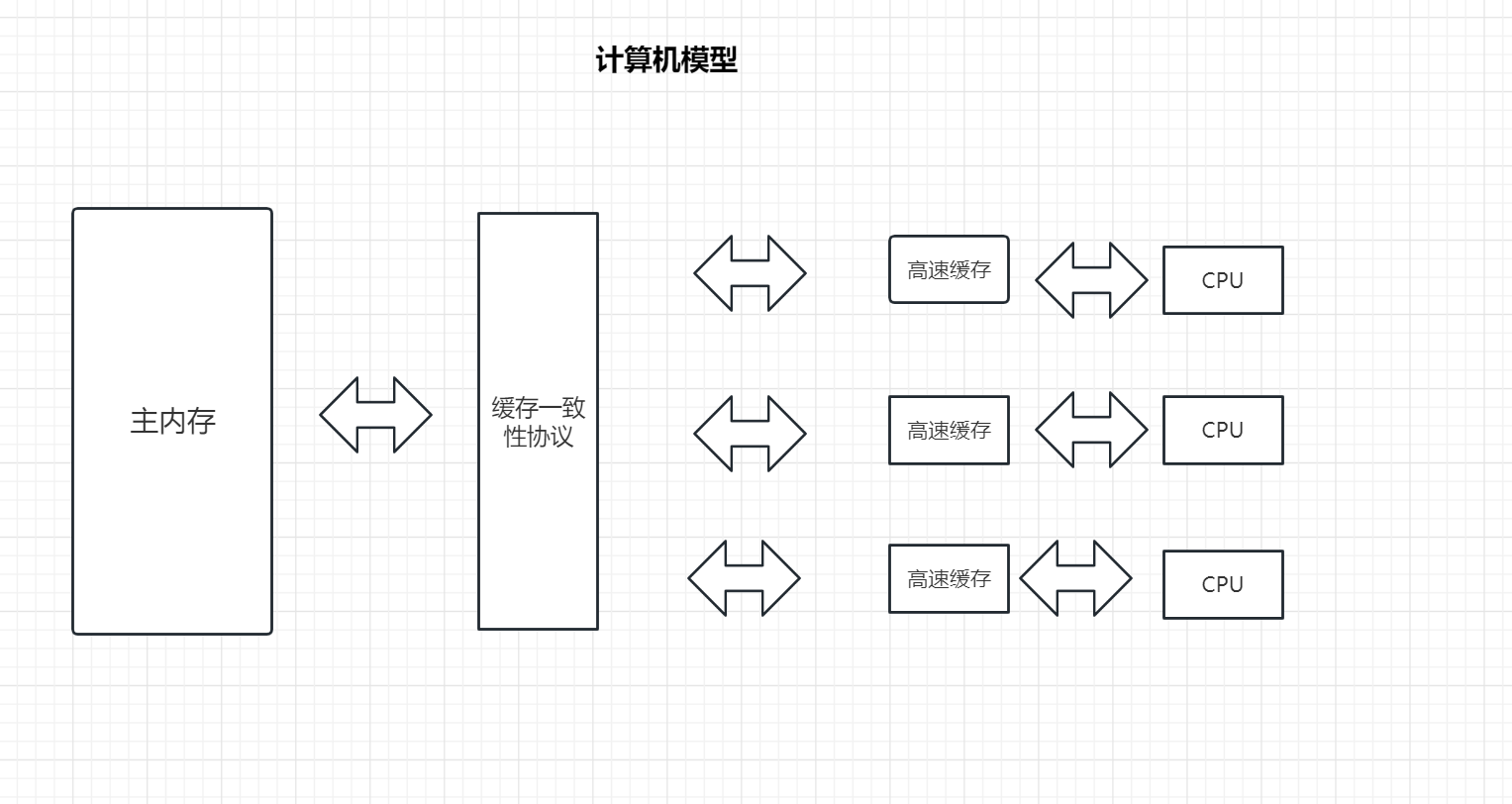
JMM内存模型
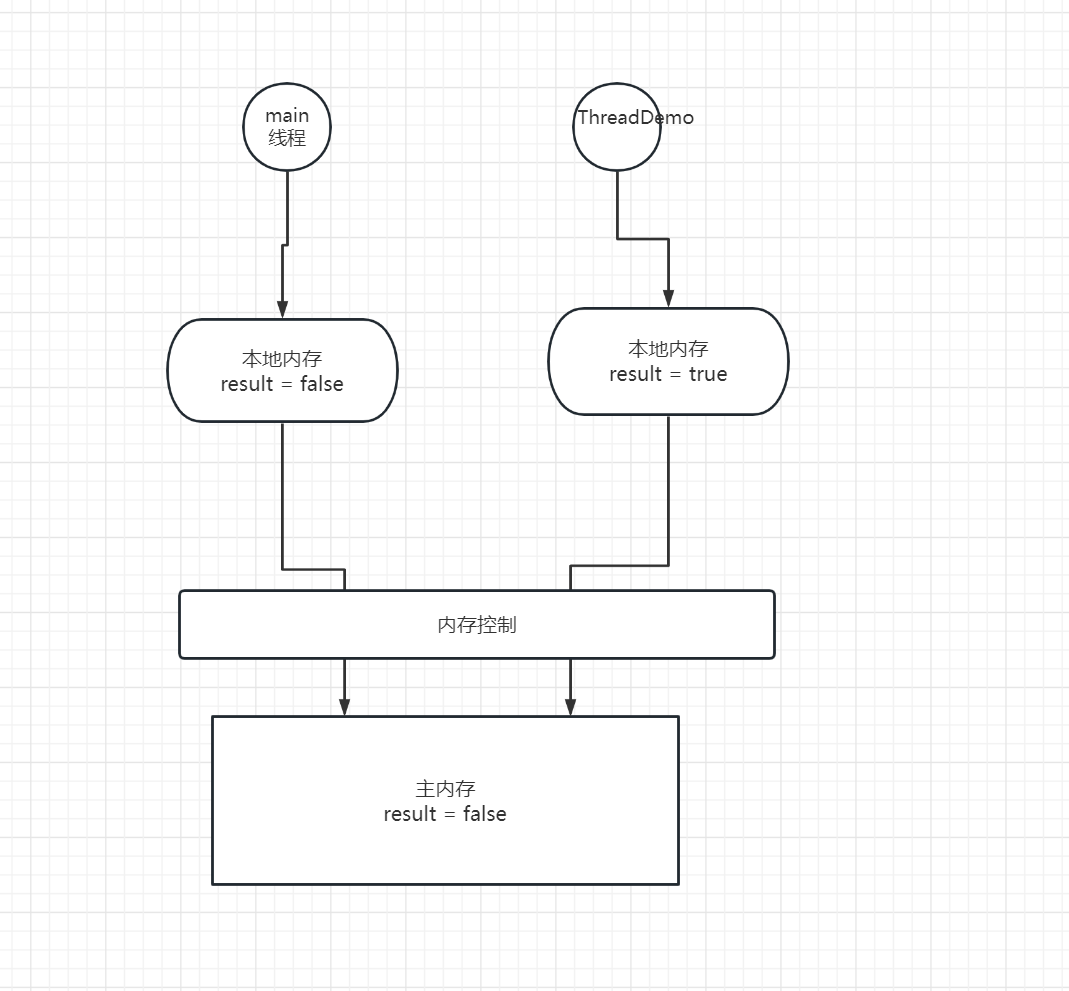
我们可以由图得知,JMM内存模型与我们计算机模型非常相似,那么是如何出现上述原因的呢?
首先当我们启动两个线程去获取变量数据时,都会去主内存中获取数据,并写入到自己的本地内存中,而ThreadDemo线程此时将自己的本地内存中的result改为false,并将数据同步到主内存中,但是此时我们的main线程还是在操作自己工作空间中的老数据,main线程ThreadDemo线程之间不能相互读取各自工作内存中的数据,而main线程读取到的result为false,出现我们控制台的结果。
两个线程之间变量的可见性可以通过Volatile来实现
我们只需要在用Volatile来修饰result即可解决刚才的问题
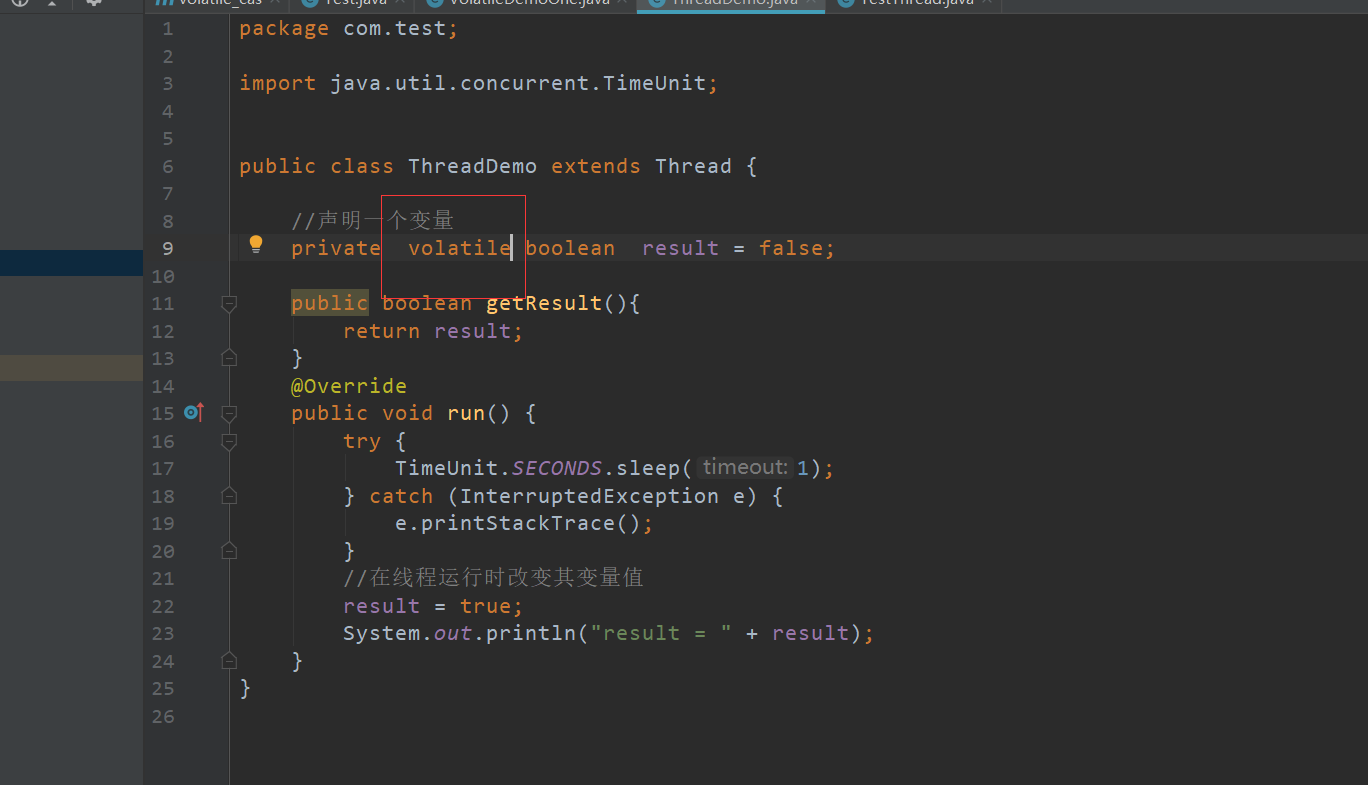
在重新运行得到正常结果
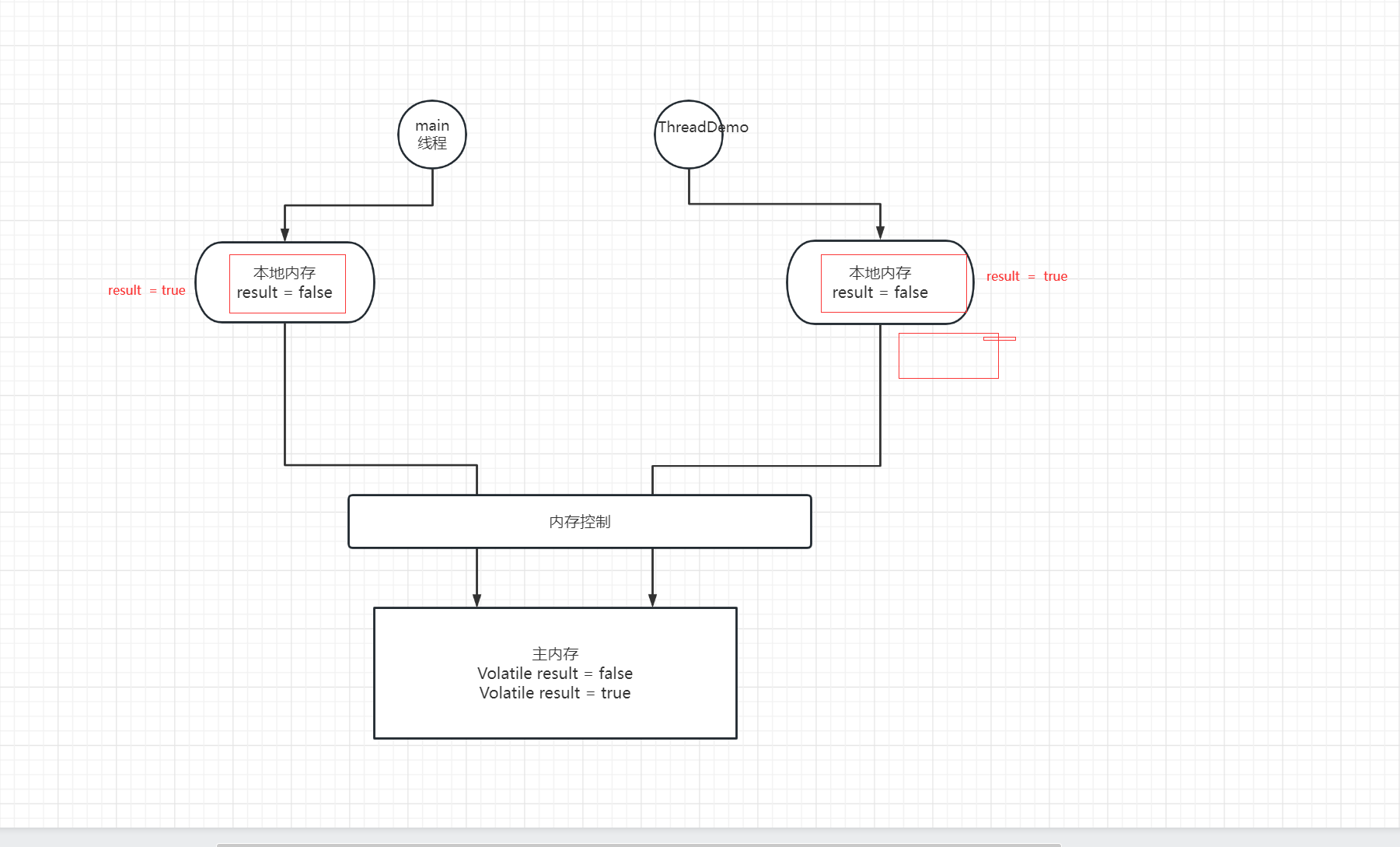
可以用以下几步来说明改变的原因:
1:开始时两个线程都去主内存中获取result数据并写入到自己的工作内存中
2:此时ThreadDemo线程将result修改为true,但result是被volatile修饰的,此时result发生更新操作,其他所以使用该变量的线程会立刻收到更新消息并将自己的工作内存中关于该变量的信息删除,并重新从主内存中获取该变量的信息
3:此时main线程获取到的result的信息为true
4:此时结果正常打印
2、禁止指令重排序
在jvm运行我们的程序时,jvm会为了优化有时可能不会按照我们写的顺序去执行代码,而是按照jvm排序后的顺序去执行代码,此处可以由以下代码验证:
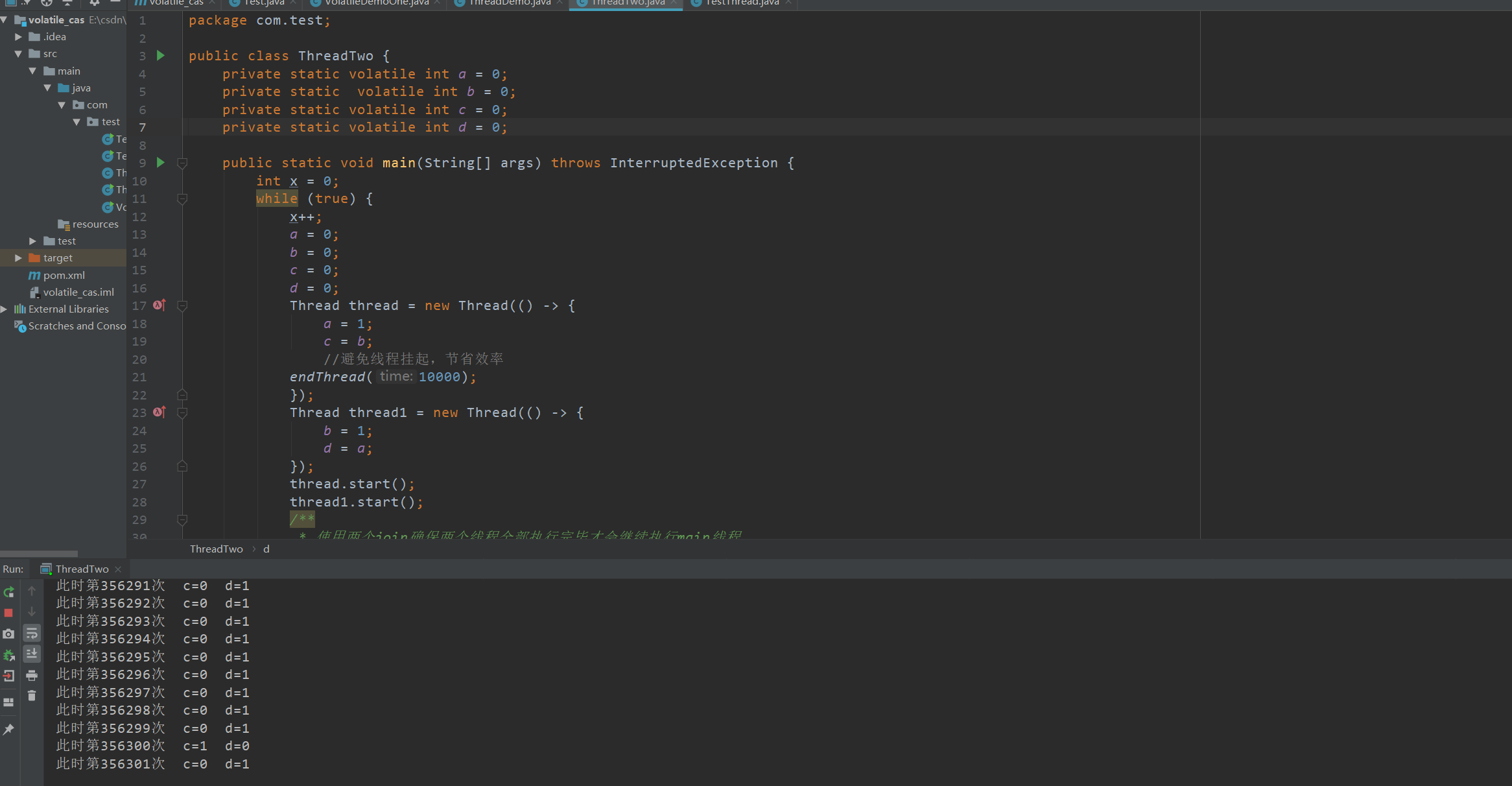
package com.test;
public class ThreadTwo {
private static int a = 0;
private static int b = 0;
private static int c = 0;
private static int d = 0;
public static void main(String[] args) throws InterruptedException {
int x = 0;
while (true) {
x++;
a = 0;
b = 0;
c = 0;
d = 0;
Thread thread = new Thread(() -> {
a = 1;
c = b;
//避免线程挂起,节省效率
endThread(10000);
});
Thread thread1 = new Thread(() -> {
b = 1;
d = a;
});
thread.start();
thread1.start();
/**
* 使用两个join确保两个线程全部执行完毕才会继续执行main线程
*/
thread.join();
thread1.join();
System.out.println("此时第" + x + "次 c="+c+" d="+d);
if (c == 0 && d == 0) {
break;
}
}
}
public static void endThread(long time) {
long start = System.nanoTime();
long end;
do {
end = System.nanoTime();
} while (start + time >= end);
}
}
正常情况下将会一直重复下去,不会break终止循环
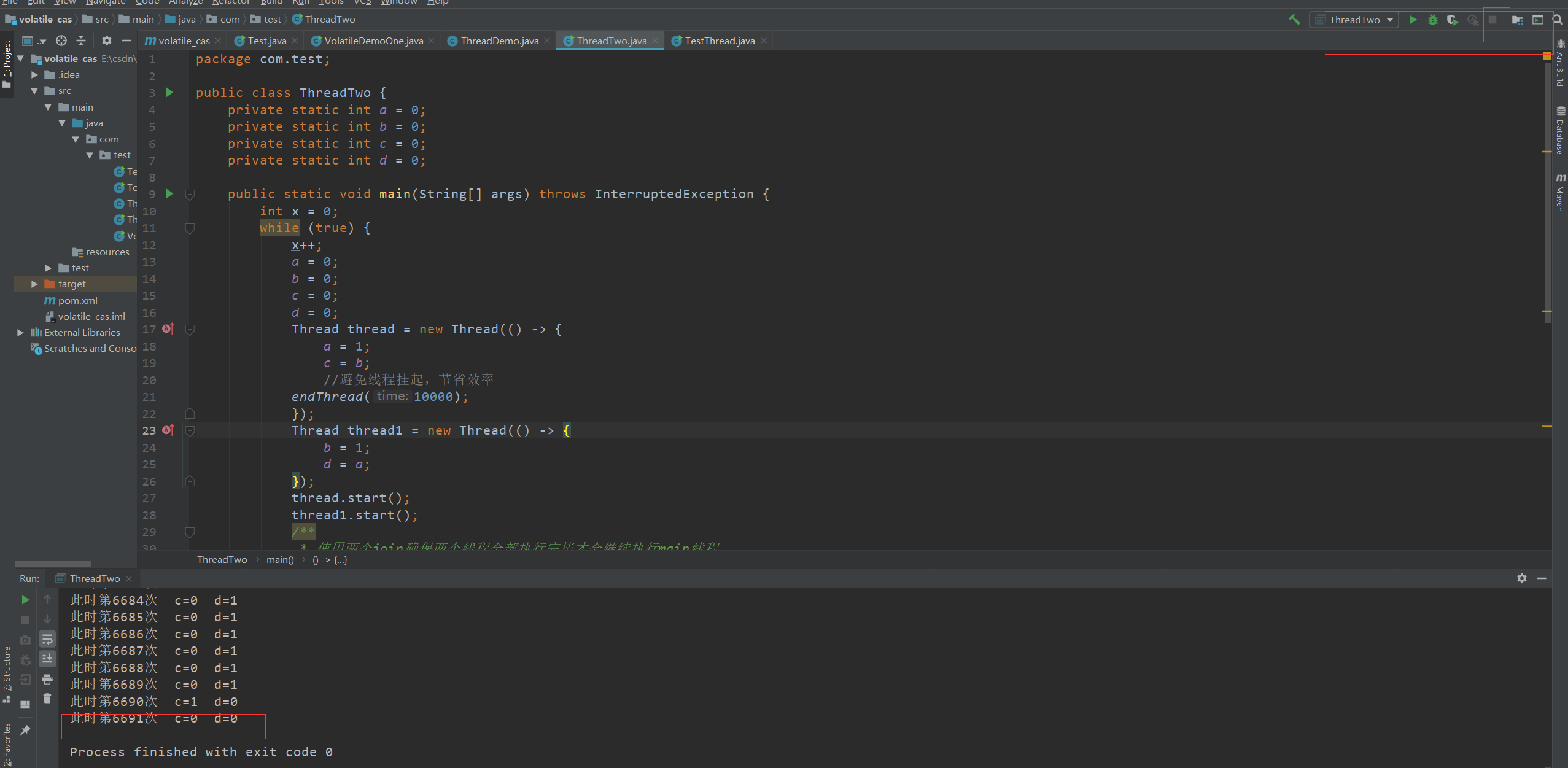
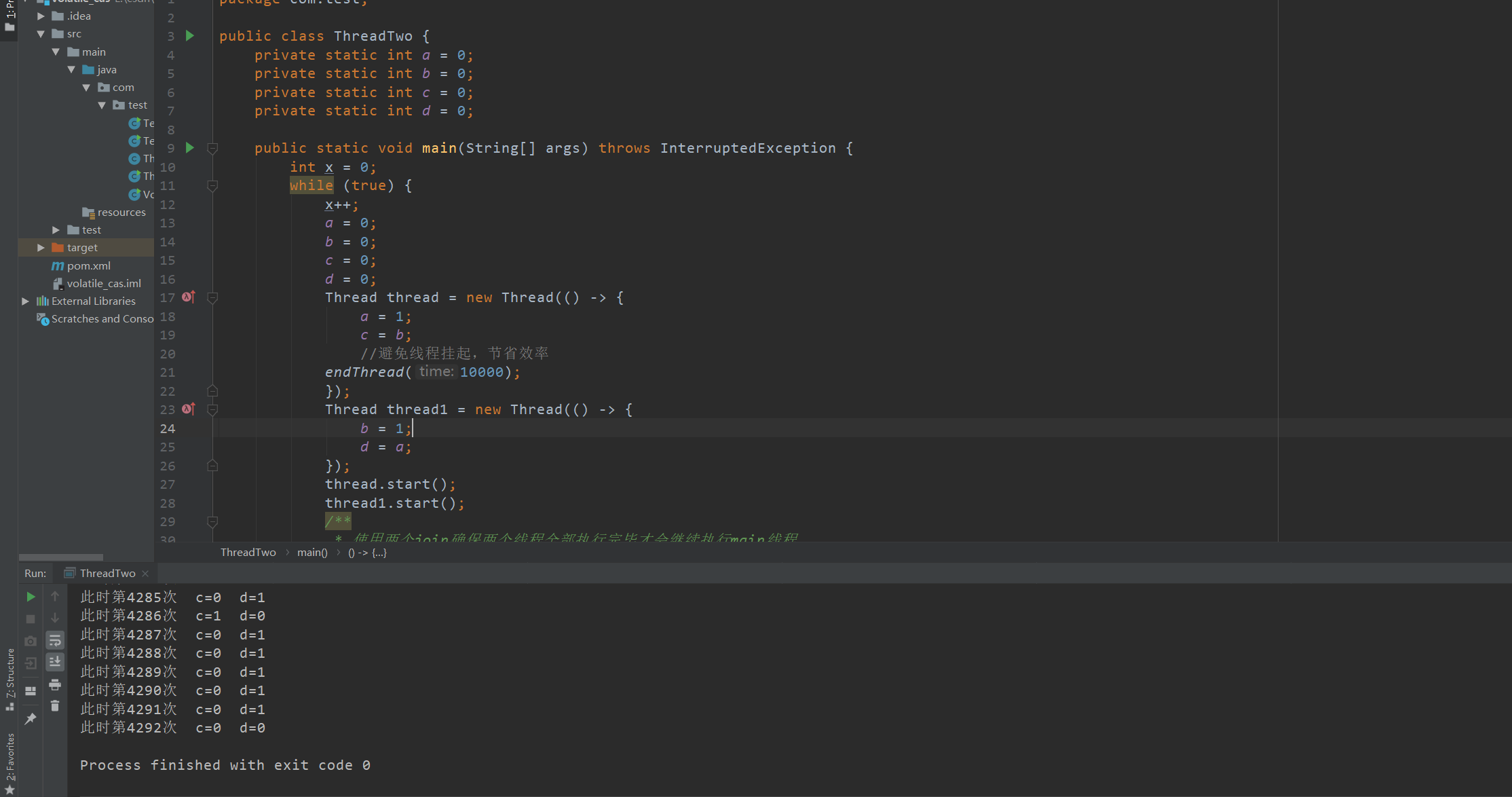
多运行几次发现程序并不会一直循环下去,而出现此种结果的现象就是在我们的程序运行时,jvm会对我们的代码进行排序执行,将我们代码中的a = 1 和c = b 互换位置,将b = 1 和d = a 互换位置,此时运行的结果就是c = 0并且d = 0.为了防止出现此种现象,我们可以使用volatile关键字来修饰我们的四个变量,防止jvm对我们的程序进行指令重排序。效果如下:
那么volatile是如何禁止指令重排序的呢?
volatile使用一个名叫内存屏障的东西来禁止指令重排序,就类似于在我们两行代码中间加上了一道墙,编译器、优化器无法再调换语句顺序。
内存屏障
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
volatile使用了内存屏障就保证了我们的代码顺序不会被编译器、处理器所重排,保证了程序运行的准确性。
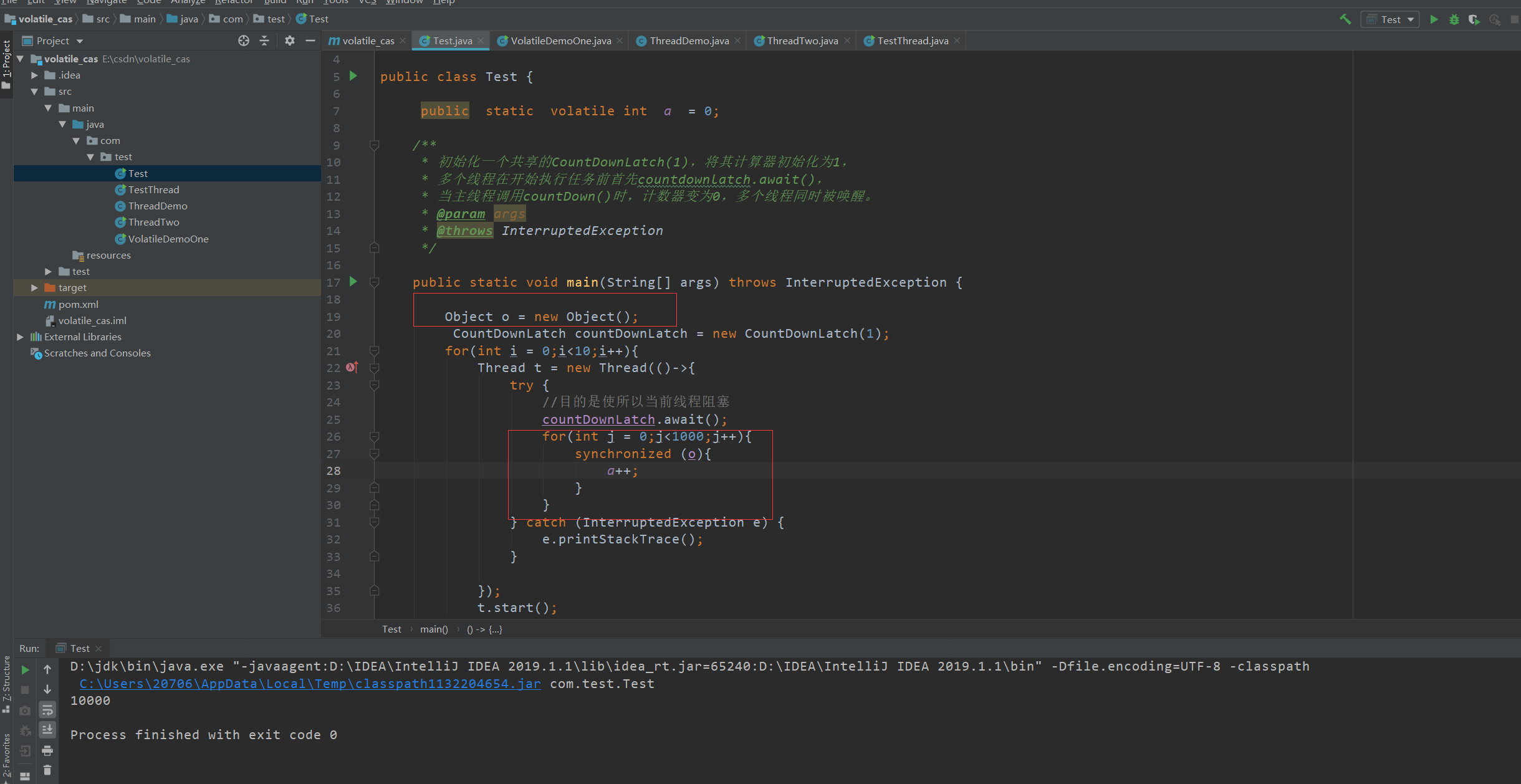
3、不具有原子性
可以使用多线程之间的++操作来证明volatile不具备原子性
下面是10个线程并行++操作,因为++不是原子性操作,在多线程环境下不安全,因此计算出的结果会小于实际结果10000。
package com.test;
import java.util.concurrent.CountDownLatch;
public class Test {
public static int a = 0;
/**
* 初始化一个共享的CountDownLatch(1),将其计算器初始化为1,
* 多个线程在开始执行任务前首先countdownlatch.await(),
* 当主线程调用countDown()时,计数器变为0,多个线程同时被唤醒。
* @param args
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
for(int i = 0;i<10;i++){
Thread t = new Thread(()->{
try {
//目的是使所以当前线程阻塞
countDownLatch.await();
for(int j = 0;j<1000;j++){
a++;
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start();
}
Thread.sleep(200);
//唤醒所有阻塞的线程,实现并行效果
countDownLatch.countDown();
Thread.sleep(3000);
System.out.println(a);
}
}
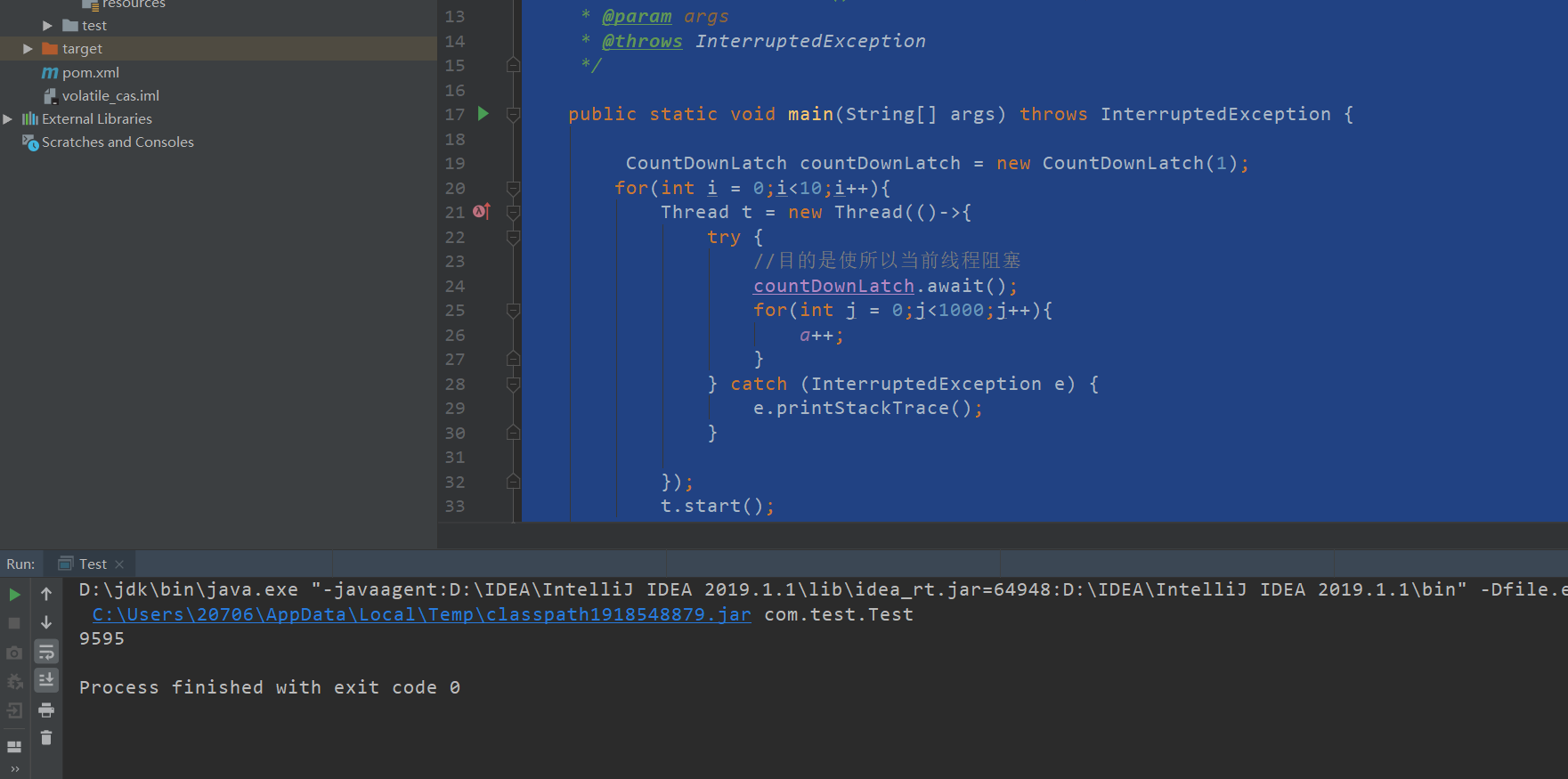
如果我们使用volatile修饰变量得到的结果也是小于10000的,因此猜想volatile不具备原子性。
而出现此结果的原因可以看下图所示:
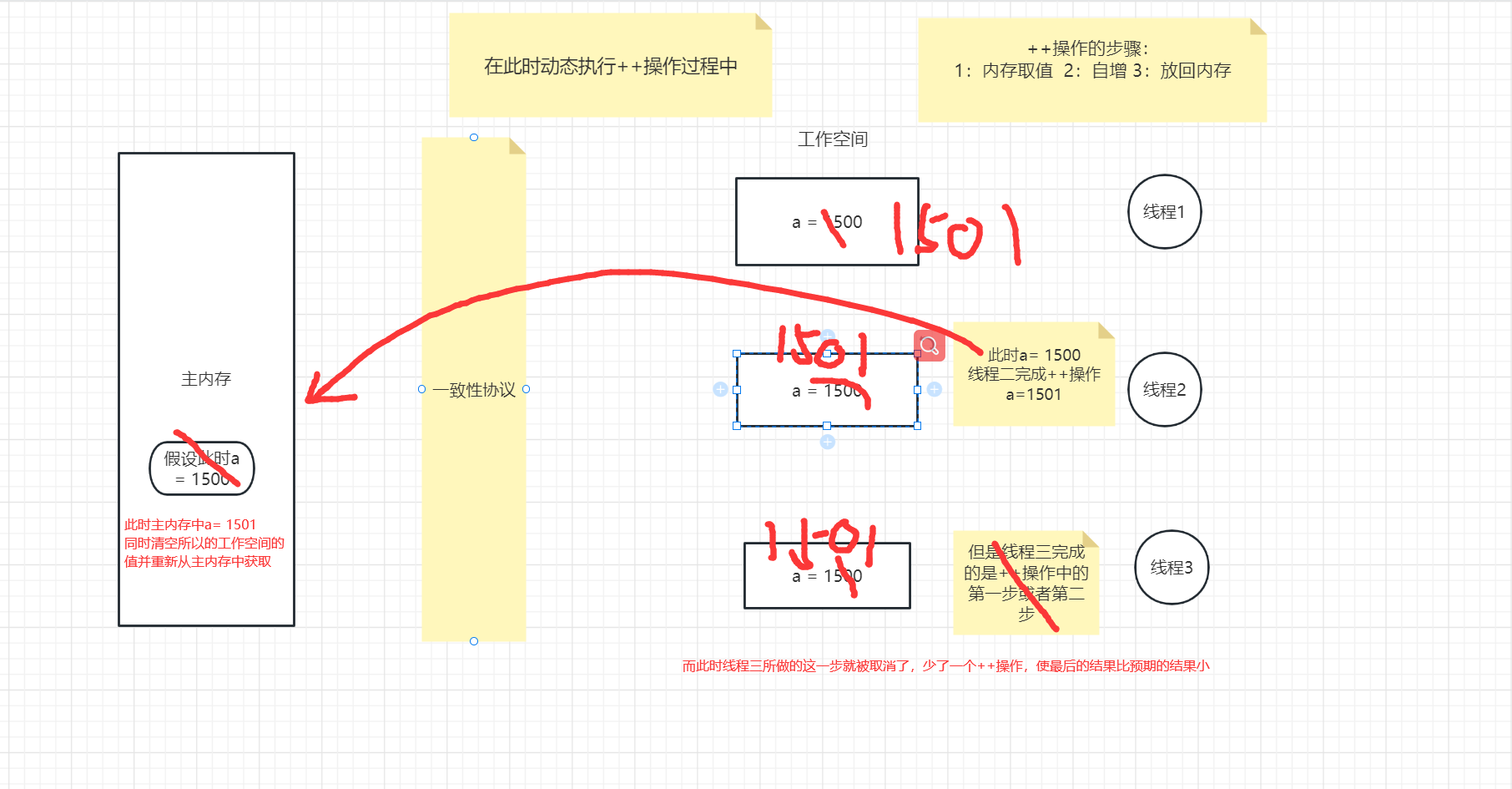
如果我们想要实现线程安全的++操作,第一时间想到的就是加锁处理,但是这无疑是有点浪费效率的,在java中的juc包下就有一个天然线程安全自增原子类AtomicInteger,可以帮助我们来实现线程安全的++操作。
加锁处理:
使用AtomicInteger原子类:
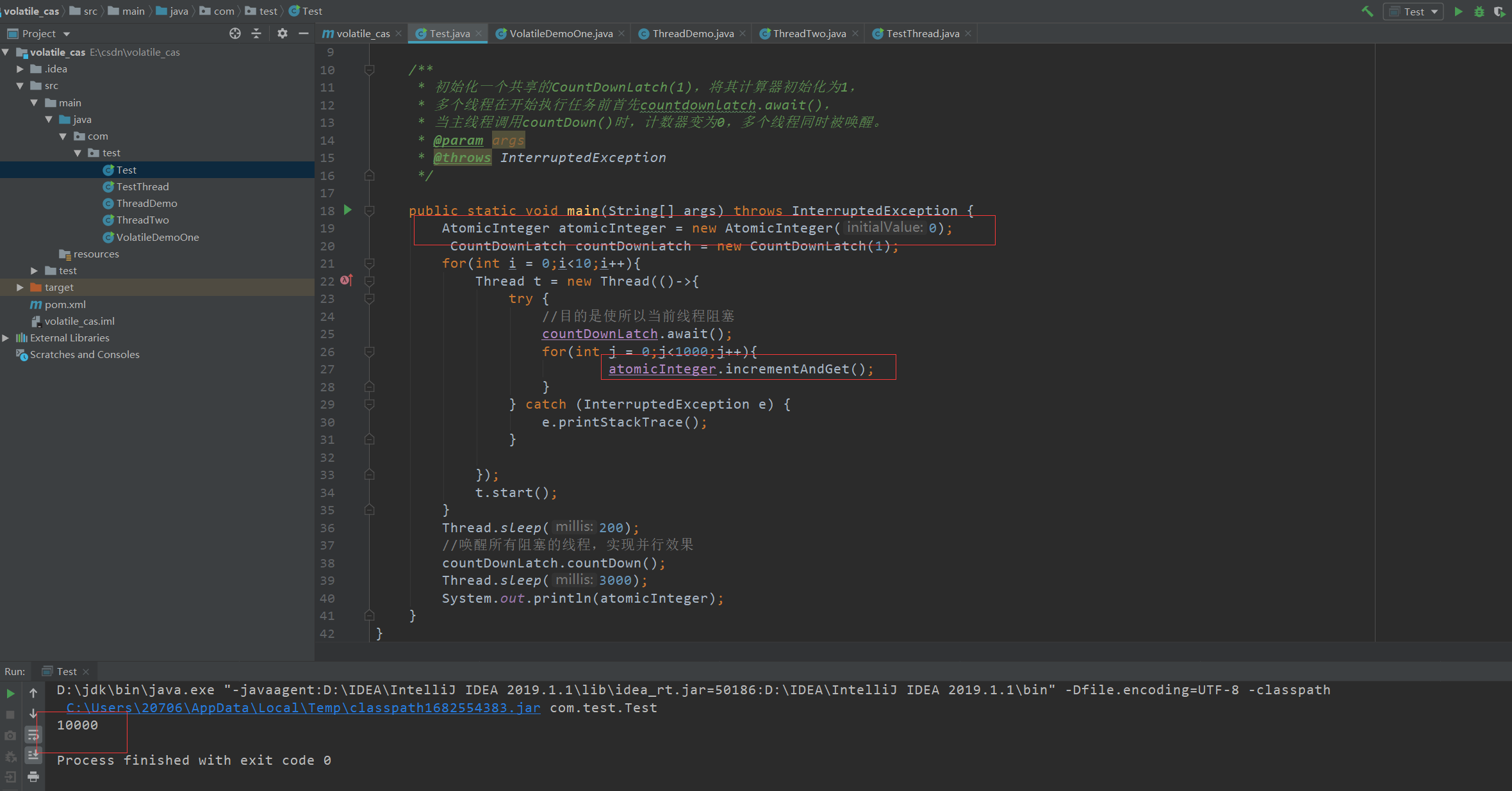
AtomicInteger本质上就是通过使用CAS来保证我们的自增线程安全的
CAS
CAS的定义
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。其本质就是比较与替换。 如果V==A,那么将把B的值赋给V并写入到内存中,完成替换 。否则,处理器不做任何操作。
基于cas的实现有AtomicBoolean,AtomicInteger Lock 等,CAS 基于 利用unsafe提供了原子性操作方法实现
举例
volatile int a = 1
目标是要线程安全的修改 a 使用CAS 修改
1.获取 a 值 (旧值(1))
2.调用CAS(旧值(1),要修改的值(2))
• cas 底层是Unsafe 的cas 实现( 将传入的旧值(1) 和 现在a 的值相比,如果相等,就将要修改的值2 赋值给 a,如果不相等,则不设置(因为不相等代表其他线程修改过 a的值))
AtomicInteger 自增实现
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}Unsafe类中的compareAndSwapInt(Object var1, long var2, int var4, int var5)
var1:要修改的对象起始地址 如:0x00000111
var2:需要修改的具体内存地址 如100 。0x0000011+100 = 0x0000111就是要修改的值的地址
注意没有var3
var4:期望内存中的值,拿这个值和0x0000111内存中的中值比较,如果为true,则修改,返回ture,否则返回false,等待下次修改。
var5:如果上一步比较为ture,则把var5更新到0x0000111其实的内存中。
原子操作,直接操作内存。
cas 存在 aba问题?
什么意思呢?就是说一个线程把数据A变为了B,然后又重新变成了A。此时另外一个线程读取的时候,发现A没有变化,就误以为是原来的那个A。这就是有名的ABA问题。ABA问题会带来什么后果呢?我们举个例子。
一个小偷,把别人家的钱偷了之后又还了回来,还是原来的钱吗,你老婆出轨之后又回来,还是原来的老婆吗?ABA问题也一样,如果不好好解决就会带来大量的问题。最常见的就是资金问题,也就是别人如果挪用了你的钱,在你发现之前又还了回来。但是别人却已经触犯了法律。
账户: 100
提款机1 : 100 ,50
提款机2 : 100 ,50
只有一个成功 账户余额 50,另外一个提款机1 失败
账户: 100
提款机1 : 100 ,50 A
用户:存50 50, +50 结果 100 B
提款机2 : 100 ,50 A 成功,但是结果是错误的
使用版本号解决ABA?
在每修改一次目标值,都给对应的目标值,绑定一个版本号
具体使用 AtomicStampedReference 为对应的目标对象进行包装 增加版本(时间标记),解决ABA 问题
public static void main(String[] args) {
String str1 = "aaa";
String str2 = "bbb";
AtomicStampedReference<String> reference = new AtomicStampedReference<String>(str1,1);
reference.compareAndSet(str1,str2,reference.getStamp(),reference.getStamp()+1);
System.out.println("reference.getReference() = " + reference.getReference());
boolean b = reference.attemptStamp(str2, reference.getStamp() + 1);
System.out.println("b: "+b);
System.out.println("reference.getStamp() = "+reference.getStamp());
boolean c = reference.weakCompareAndSet(str2,"ccc",4, reference.getStamp()+1);
System.out.println("reference.getReference() = "+reference.getReference());
System.out.println("c = " + c);
}性能问题?
除此之外,在并发量非常高的情况下,CAS失败的几率将变得非常高,重试的次数也会跟着增加,越多线程重试,CAS失败的几率就越高,变成恶性循环。因此在并发量非常高的环境中,如果仍然想通过原子类来更新的话,可以使用AtomicLong的替代类:LongAdder。 Adder 类解决
将单一value的更新压力分担到多个value中去,降低单个value的“热度”,分段更新,这样,线程数再多也会分担到多个value上去更新,只需要增加value的个数就可以降低value的 “热度”,这样AtomicLong中的恶性循环就可以解决了。
在LongAdder中cells就是这个“段”,cell中的value就是存放更新值的,这样,当我需要总数时,把cell中的value都累加一下不就可以了么
让我们看一下LongAdder更新的原则:
1.当并发低时先采用CAS进行更新,如果更新成功即返回
2.当并发高且CAS更新失败时,则进入分段更新
测试
public class AtomicityLongAdder {
private final LongAdder count = new LongAdder();
public void increase() {
count.increment();
}
public long count(){
return count.longValue();
}
}
public class Test {
public static void main(String[] args) {
Long time = System.currentTimeMillis();
final AtomicityLongAdder atomicityLongAdder = new AtomicityLongAdder();
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
public void run() {
for (int j = 0; j < 10000; j++) {
atomicityLongAdder.increase();
}
}
}).start();
}
System.out.println("Thread.activeCount()"+Thread.activeCount());
while(Thread.activeCount() > 2) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("运行时间:" + (System.currentTimeMillis() - time));
System.out.println("LongAdder(乐观锁):" + atomicityLongAdder.count());
}
}AtomicInteger 对比?
public class Test2 {
public static void main(String[] args) {
Long time = System.currentTimeMillis();
final AtomicInteger atomicInteger = new AtomicInteger();
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
public void run() {
for (int j = 0; j < 10000; j++) {
atomicInteger.incrementAndGet();
}
}
}).start();
}
System.out.println("Thread.activeCount()"+Thread.activeCount());
while(Thread.activeCount() > 2) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("运行时间:" + (System.currentTimeMillis() - time));
System.out.println("LongAdder(乐观锁):" + atomicInteger.intValue());
}
}Unsafe类介绍**
Unsafe类是在sun.misc包下,不属于Java标准。但是很多Java的基础类库,包括一些被广泛使用的高性能开发库都是基于Unsafe类开发的,比如Netty、Hadoop、Kafka等。
使用Unsafe可用来直接访问系统内存资源并进行自主管理,Unsafe类在提升Java运行效率,增强Java语言底层操作能力方面起了很大的作用。
Unsafe可认为是Java中留下的后门,提供了一些低层次操作,如直接内存访问、线程调度等。
import java.lang.reflect.Field;
import sun.misc.Unsafe;
public class UnsafePlayer {
public static void main(String[] args) throws Exception {
//通过反射实例化Unsafe
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
//实例化Player
Player player = (Player) unsafe.allocateInstance(Player.class);
player.setName("li lei");
System.out.println(player.getName());
}
}
class Player{
private String name;
private Player(){}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









