






概述
BLIP系列是salesforce在多模态领域做的工作,个人觉得其设计思路较为精巧,稍作记录。本篇为BLIP系列的第一篇,记录的是这个系列的改进模型BLIP2.
设计思路简述
用一个Q-former来对齐图像和文本信息,连接Image encoder和LLM,实现多模态输入的处理。
模型结构
模型的核心结构是Q-Former,实际为插入了cross-attention的bert,增加了可学习的queries与image encoder的输出做cross-attention,提取图像特征中的关键部分。Image Encoder和LLM均为冻住的,复用训练好的模型。
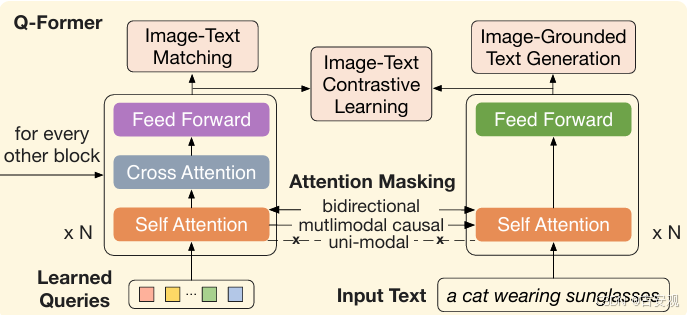
在BLIP2中,Q-Former是复用的,可以分别处理queries和text作为输入。Text输入时,cross-attention层会被跳过,直接输出text features。当queries和text一起输入时(多模态输入),会先分别算出他们的features然后拼接,将拼接后的特征输入LLM来获得最后的输出,因此将其称为Bridge。
训练策略 —— 两阶段训练
阶段一:对齐预训练
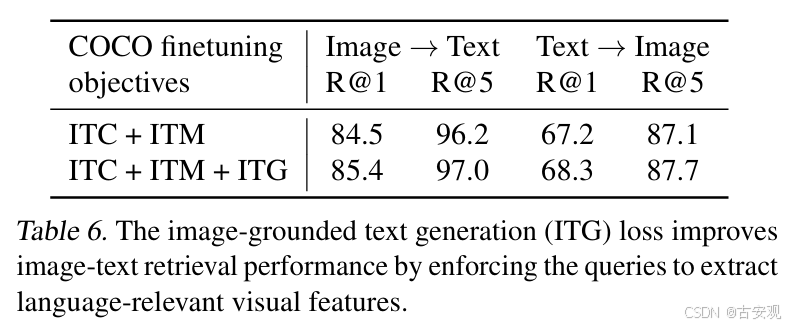
该阶段下主要目的是实现图像和文本的对齐,提取图像中与文本最相关的重要特征。训练目标分为三个,分别是ITC、ITM和ITG。ITC是文本和图像的对比loss,ITM是一个二分类loss,给定image-text pair判断其是否为一对(0/1),ITG则是根据图像来做文本生成,类似captioner。在BLIP2的代码实现中,ITC是将文本和query分别输入来获取特征,然后做loss,不需要mask;其余两个则是query和text一起,用mask来控制模型可以看到的区域。
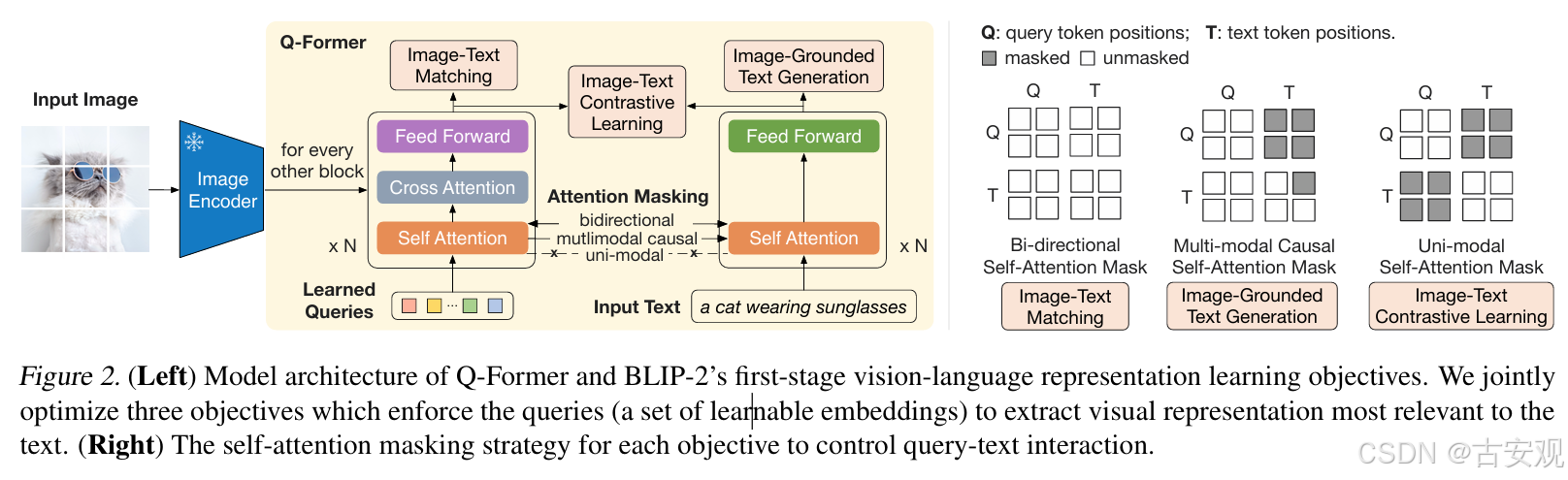
阶段二:生成
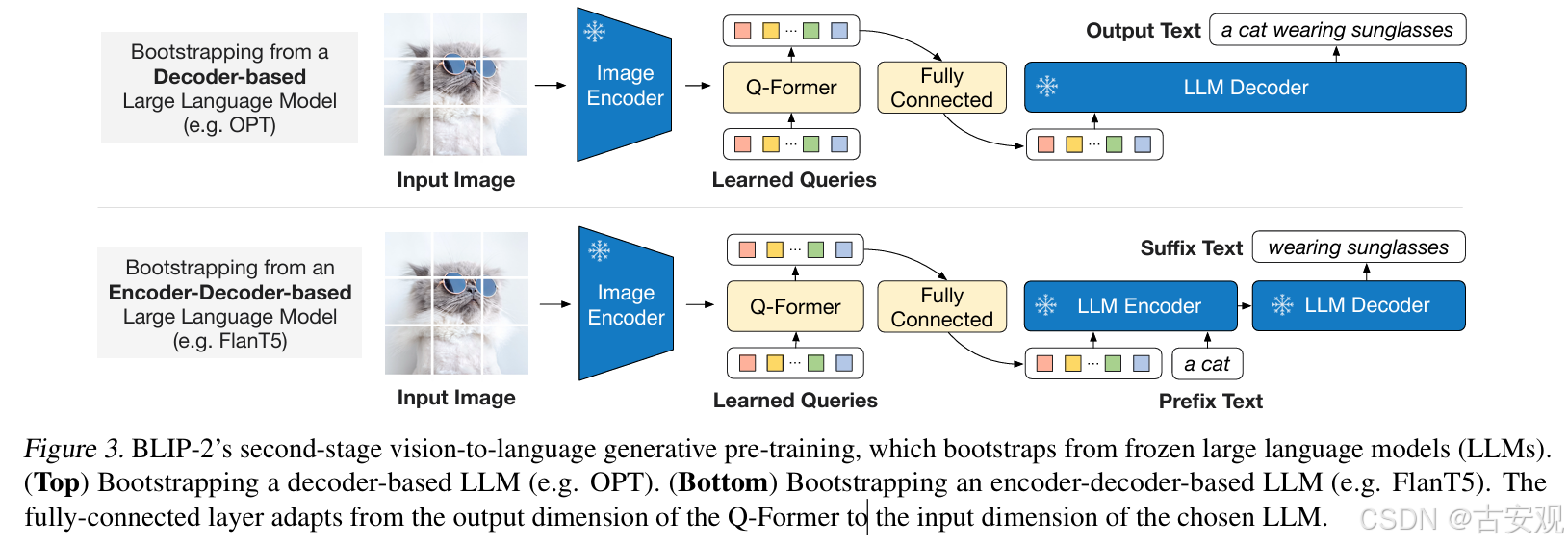
将阶段一训练好的模型接入LLM,通过一个全连接层来连接两个模型,使得Q-Former的输出和LLM的text embeddings保持维度统一。文中实验采用了两种架构的LLM,对于encoder-decoder架构的LLM会给一个prefix text来作为初始信息。
性能对比
BLIP2可以兼容不同的LLM,在VQA、caption等任务均体现不错的性能;Q-Former也可以单独作为text-encoder和vit一起,形成clip style的跨模态检索框架。
VQA
碎碎念:Flamingo似乎看到了很多次,但是都在被各种“暴打”,感觉也得找时间看看,不然为啥那么多多模态找他做baseline呢~
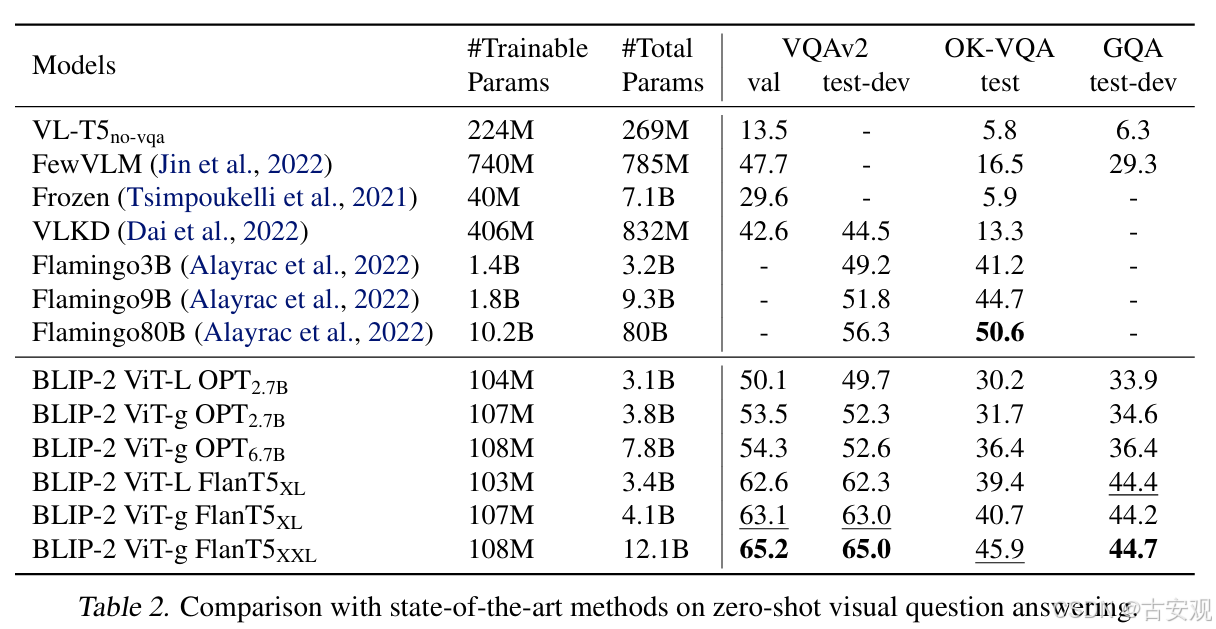
Image Captioning
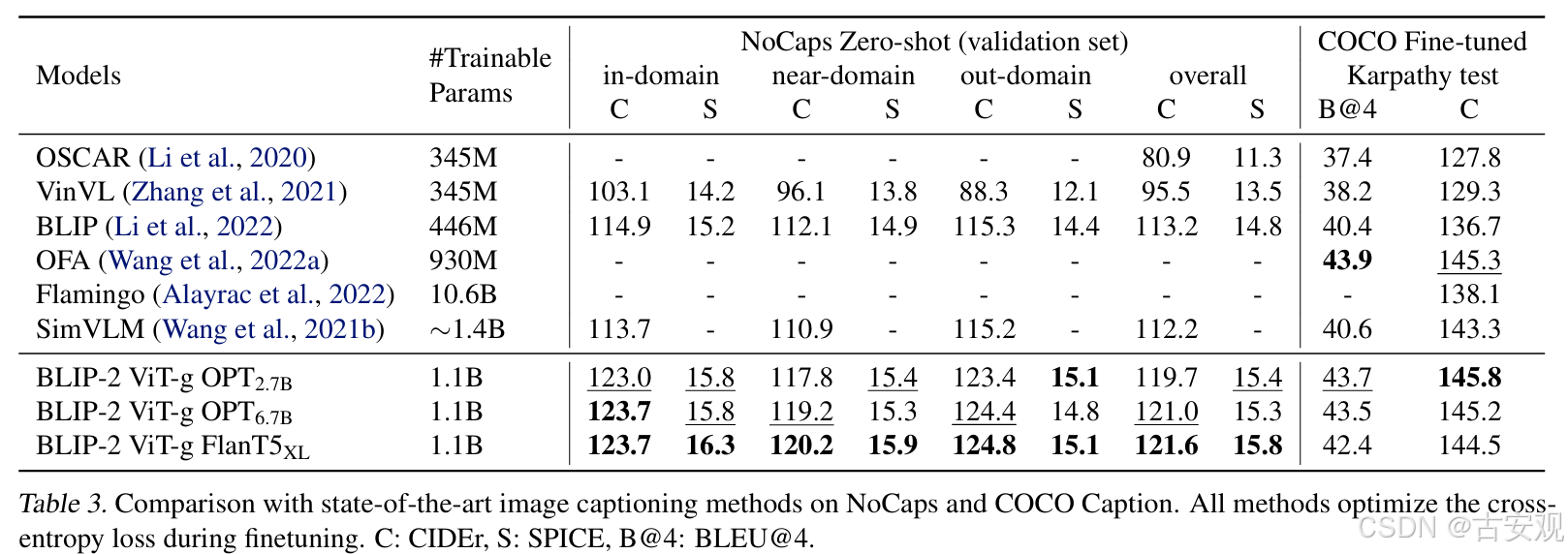
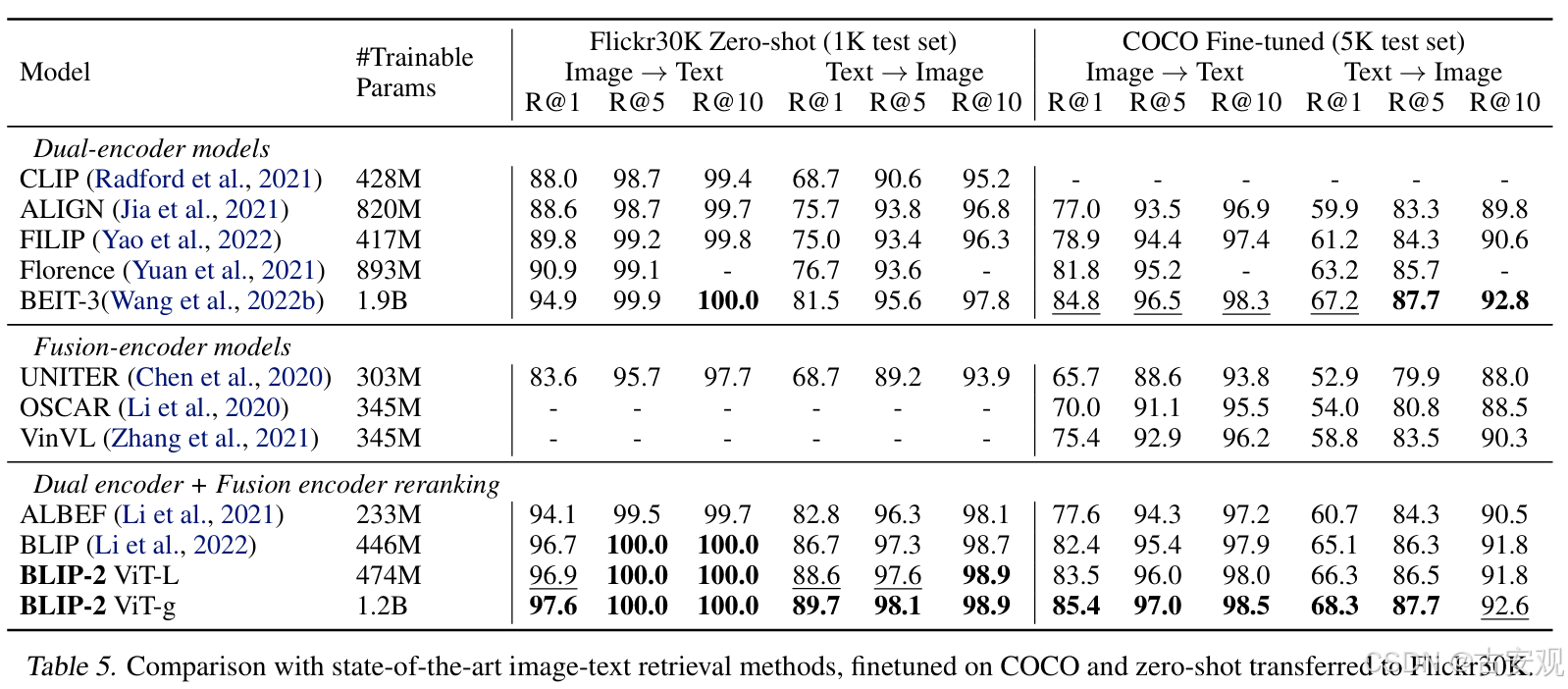
Image-Text Retrieval
Ablation Study
BLIP2的一些骚操作应用
Captioner
跟BLIP一样,BLIP2在预训练时有文本生成这样一个代理任务,因此Q-Former也可以作为captioner用来生成图文对的synthesis datasets,以扩充多模态数据集,例如M2-Encoder中,在数据清洗时对clip score较低的样本做增强,就是用BLIP2来重写caption。
Data Cleaner
由于BLIP2有ITM loss,因此可以在细粒度上对齐图像和文本,由itm打出来的分数同样可以作为数据筛选的一个标准(实测效果还不错,筛选的比例会比clip score更低),如Datacomp中就有人结合itm score作为标准获得了不错的数据清洗结果。

















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









