







 本文详细介绍了如何使用Python实现基于信息增益的决策树算法,从伪代码到具体函数的编写,包括数据集划分、特征选择、递归生成树等关键步骤。通过信息熵和信息增益计算最优特征,最终构建出决策树模型,并进行了模型验证,测试准确率达到了100%。此外,还提供了数据集和代码下载链接。
本文详细介绍了如何使用Python实现基于信息增益的决策树算法,从伪代码到具体函数的编写,包括数据集划分、特征选择、递归生成树等关键步骤。通过信息熵和信息增益计算最优特征,最终构建出决策树模型,并进行了模型验证,测试准确率达到了100%。此外,还提供了数据集和代码下载链接。
机器学习基于信息增益的决策树代码实现
1基本流程
根据西瓜书上的内容给出一下的伪代码描述,并且本文也是根据伪代码来编写的。
input:训练集D = {(
x
1
x_1
x1,
y
1
y_1
y1),(
x
2
x_2
x2,
y
2
y_2
y2),(
x
3
x_3
x3,
y
3
y_3
y3)…(
x
m
x_m
xm,
y
m
y_m
ym) };
特征集合A = {
a
1
a_1
a1,
a
2
a_2
a2,
a
3
a_3
a3…
a
m
a_m
am }.
process:
1.生成节点node.
2.if D中的样本全属于同一类 C :
3 将node节点标记为C类叶节点;return
4 end if:
5 if A为空集 or D中的样本取值相同:
6 将node标记为叶节点,其类别标记为D中类别样本数最多的类;return
7 end if;
8 从A 中选取最优属性
a
∗
a_*
a∗
9 for
a
∗
a_*
a∗的每一个值
d
s
∗
ds_*
ds∗:
10 为node生成分支;另
D
v
D_v
Dv表示为D中在
a
∗
a_*
a∗上取值为
d
s
∗
ds_*
ds∗的样本子集
11 if
D
v
D_v
Dv为空:
12 将分支节点表姐为叶节点,其类别标记为D中样本数最多的类;return
13 else:
14 继续调用该程序
output : 以node为节点的一颗决策树,在本代码中就是一个字典。
2特征选取(信息增益)
2.1信息熵:是度量样本集合纯度的一种指标,假设当前集合D中的第K类样本所占的比例为
p
k
p_k
pk(k = 1, 2 ,3 ,4…|y|),则信息熵的定义为:
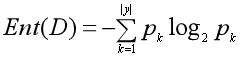
它的值越小,则纯度越高。
2.2 信息增益:其计算表达式为
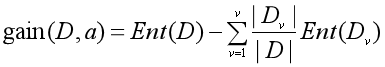
下面的这段代码就是关于信息增益的
#即 p*log(2,p),但是当p = 0时,结果仍然是0
def Ent(D):
set1 = set(D)
ent = 0
for value in set1:
if D.count(value) != 0:
ent = ent - (D.count(value)/len(D))*log2((D.count(value)/len(D)))
return ent
其他函数编写
我根据伪代码:编写了一下的几个函数,
1.递归调用函数,
2特征选择函数,
3.最大类别选择函数,
4.数据集划分的函数。
from math import log2
import copy
#递归生成树函数
def TreeGenerate(D, A):
class_list = [example[-1] for example in D]
if class_list.count(class_list[0]) == len(D): #如果样本中只有一类的C,则直接返回结果
return D[0][-1]
if len(D[0]) == 1: #如果D中再无特征可以选择,那么将返回C中类别多的作为结果
return majority(D)
#再者就是第三种情况了,选取最优属性,数据集划分,递归求解书结构
index = bestatribute(D)
feature = A[index]
#A.remove(feature)
new_A = A[:index]
new_A.extend(A[index+1:])
mytree = {feature:{}}
featValues = [example[index] for example in D]
keys = set(featValues)
for i in keys:
#这里缺少一个条件,就是在属性i上并无它的元素(在本题中已经出现了一些问题但是问题不大后期我会进行修改的)
mytree[feature][i] = TreeGenerate(splitdata(D,index,i), new_A)
return mytree
#计算数据集中那个类占的比例最高作为最优结果
def majority(D):
list1 = [example[-1] for example in D]
set1 = set(list1)
res = D[0,-1]
max_class = 0.0
for i in set1:
if list1.count(i)/len(list1) > max_class:
max_class = (list1.count(i)/len(list1))
res = i
return res
#最优属性的选择,基于信息增益的结算
def bestatribute(D):
best_gain = -1
index = -1
for i in range(len(D[0])-1):
list2 = [example[-1] for example in D]
gain = Ent(list2) #首先计算信息熵
list1 = [example[i] for example in D]
set1 = set(list1)
# 之后对其计算信息增益
for j in set1:
list2 = []
for data in D:
if data[i] == j:
list2.append(data[-1])
gain = gain - (list1.count(j)/len(list1))*Ent(list2)
if gain > best_gain:
index = i
best_gain = gain
return index
#数据集划分,选取不含制定列以及满足一定属性的数据
def splitdata(D,index,value):
retDataSet = []
for featVec in D:
if featVec[index] == value:
reducedFeatVec = featVec[:index] #chop out axis used for splitting
reducedFeatVec.extend(featVec[index+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
函数运行及决策树绘画
由于小编现在还不太会画这种树的图,所以我根据自己的结果手绘了一个数,还请大家多多见谅。
#这是主函数
if __name__ == '__main__':
fr = open('dataset_decision.txt',encoding='utf-8')
data =[inst.strip().split(' ') for inst in fr.readlines()]
atribute = ['色泽','根蒂','敲声','纹理','脐部','触感','好瓜']
atribute_copy = copy.deepcopy(atribute)
mytree = TreeGenerate(data,atribute)
这里是返回的mytree字典:
{'纹理': {'稍糊': {'触感': {'软粘': '是', '硬滑': '否'}},
'模糊': '否',
'清晰': {'根蒂': {'硬挺': '否', '蜷缩': '是',
'稍蜷': {'色泽': {'青绿': '是',
'乌黑': {'触感': {'软粘': '否', '硬滑': '是'}}}}}}}}
下图就是根据这个字典画出的决策树:
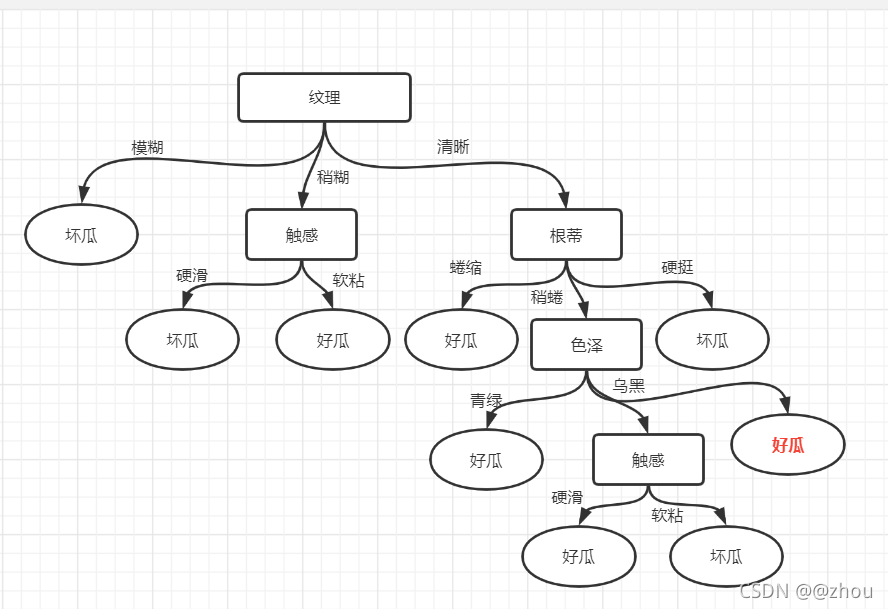
里面的红色字是少画的一个分支,因为我写的代码少考虑了一种情况,但是问题不大,加上红色的字西瓜书上给的完整决策树。
模型验证:
def predict(mytree,D,atribute):
if type(mytree) != dict:
return mytree
else:
for key, value in mytree.items():
if atribute_copy.index(key) != -1:
break
index = atribute_copy.index(key)
return predict(mytree[key][D[index]],D,atribute)
res = [predict(mytree,D,atribute_copy) for D in data]
把预测的结果放到res里面,然后与原数据进行比较,得到我们在原数据上的测试正确率达到100%。
res = ['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否']
y = ['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否']
数据集以及py文件的下载:
链接:https://pan.baidu.com/s/1xEuWXU28OX5W-TJWYgTCxw
提取码:1234


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









