









 本文深入探讨自注意力机制在深度学习中的应用,包括其实现方式、与CNN及RNN的对比,并介绍其在语言识别和图像处理等领域的实践案例。
本文深入探讨自注意力机制在深度学习中的应用,包括其实现方式、与CNN及RNN的对比,并介绍其在语言识别和图像处理等领域的实践案例。
[2022]李宏毅深度学习与机器学习第四讲(必修)-self-attention
做笔记的目的
1、监督自己把50多个小时的视频看下去,所以每看一部分内容做一下笔记,我认为这是比较有意义的一件事情。
2、路漫漫其修远兮,学习是不断重复和积累的过程。怕自己看完视频不及时做笔记,学习效果不好,因此想着做笔记,提高学习效果。
3、因为刚刚入门深度学习,听课的过程中,理解难免有偏差,也希望各位大佬指正。
输出的类型
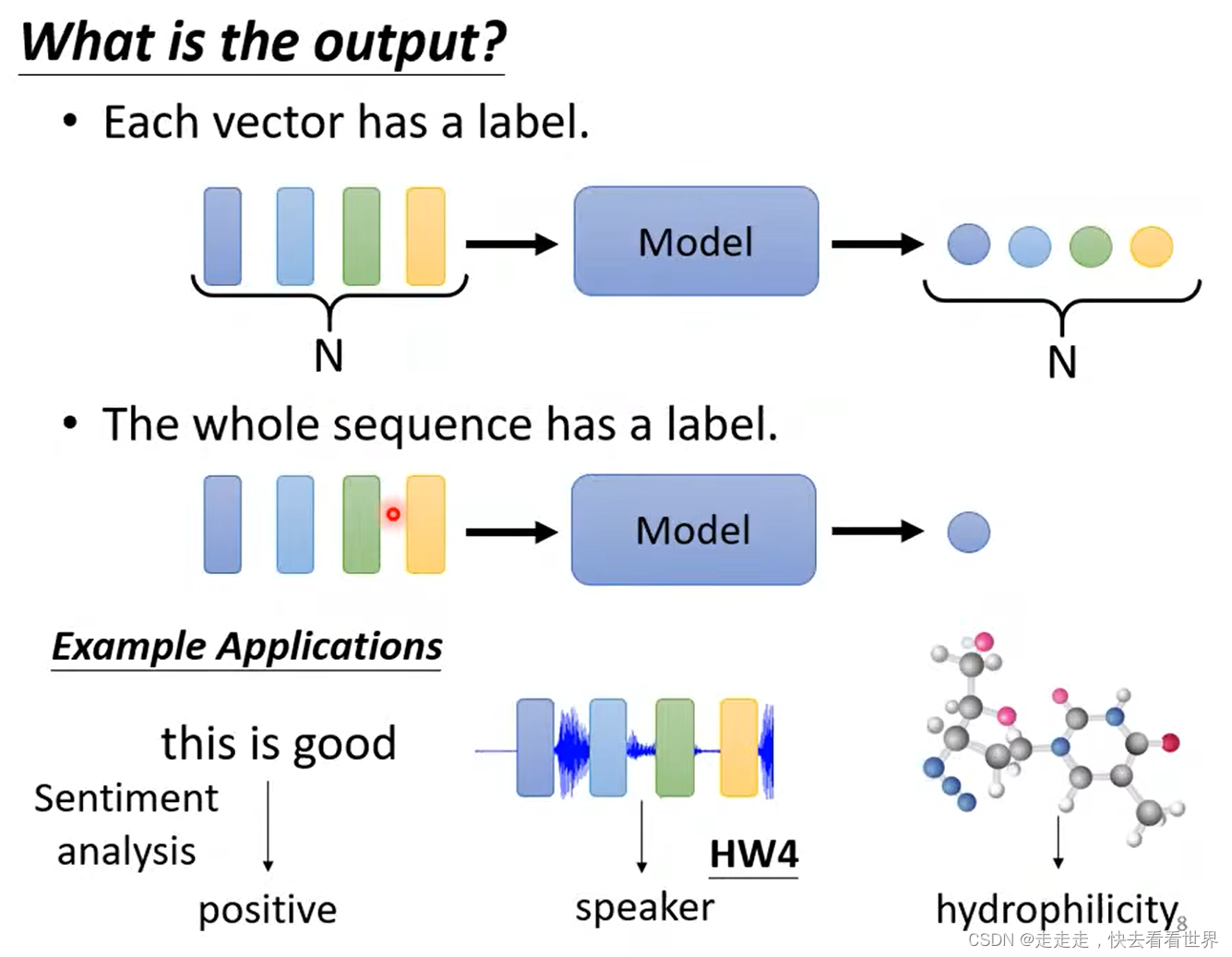
- Each vector has a label
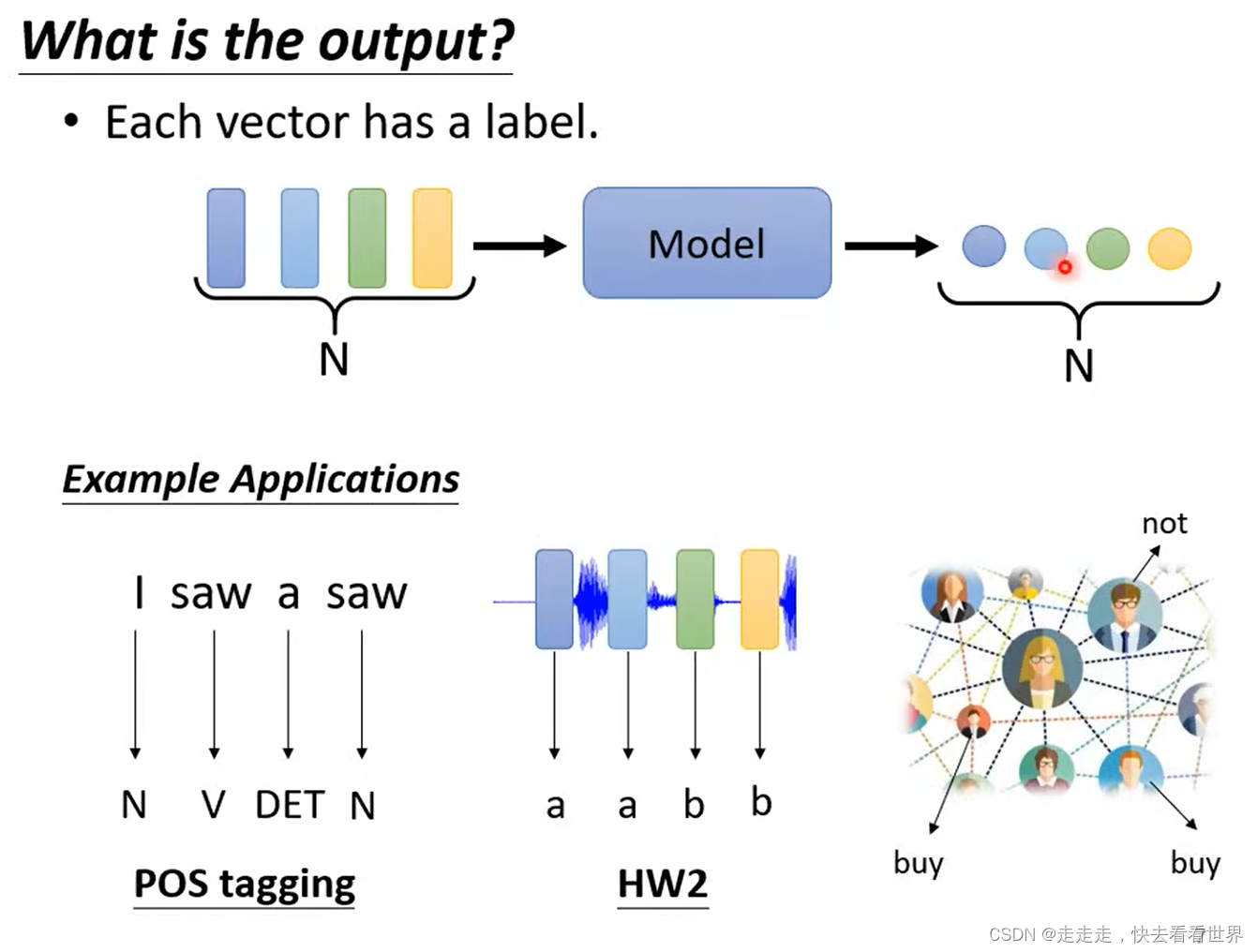
- whole vector sequence has a label
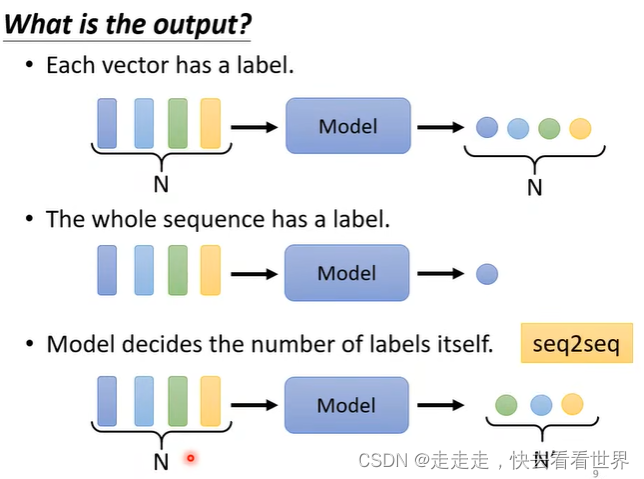
- Model decides the number of labels itself
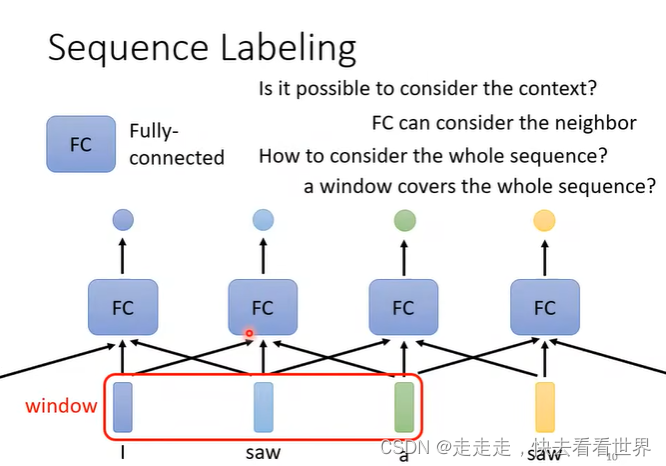
 Each vector has a label,可以用一个神经网络直接预测出label,但是如果向量间有联系可能就会比较难办。一种方法可以是设置一个窗口把这些向量都输入进来,但是如果window很大时,那么参数就会非常多,容易overfitting,这里可以用self-attention。
Each vector has a label,可以用一个神经网络直接预测出label,但是如果向量间有联系可能就会比较难办。一种方法可以是设置一个窗口把这些向量都输入进来,但是如果window很大时,那么参数就会非常多,容易overfitting,这里可以用self-attention。
Self-attention
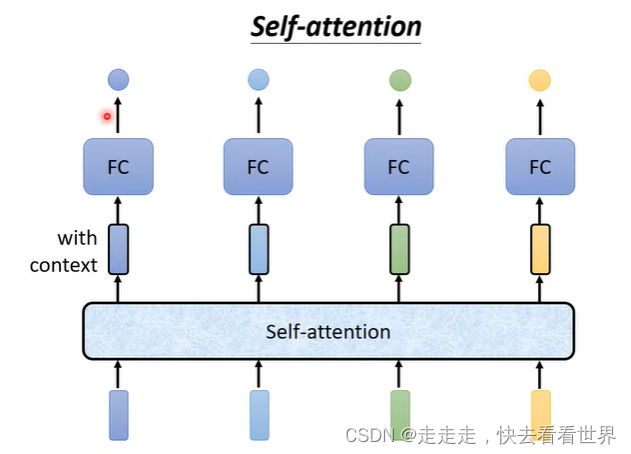
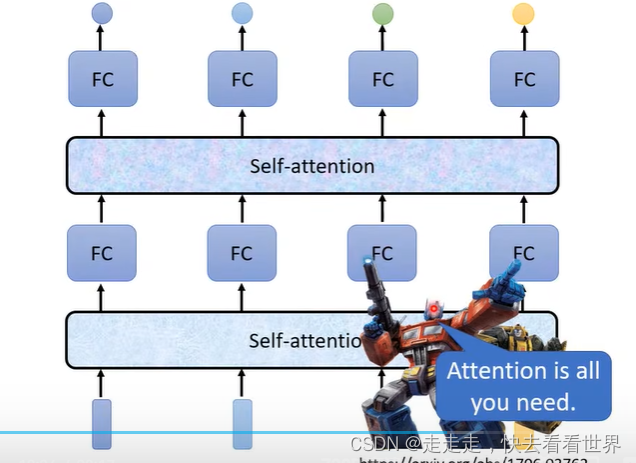
可以self-attention加全连接,来实现一些奇妙的功能。
具体实现
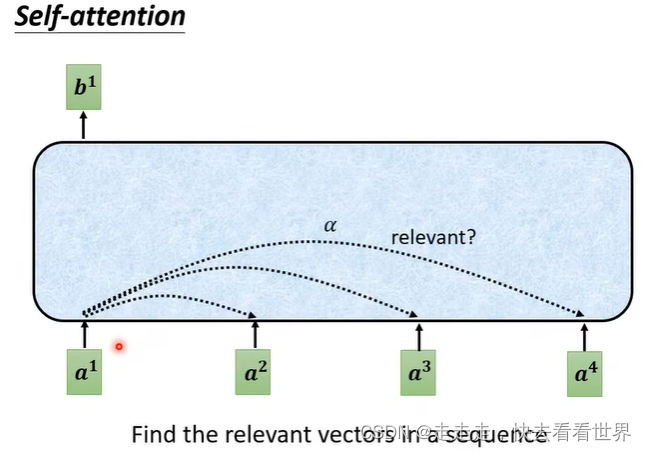
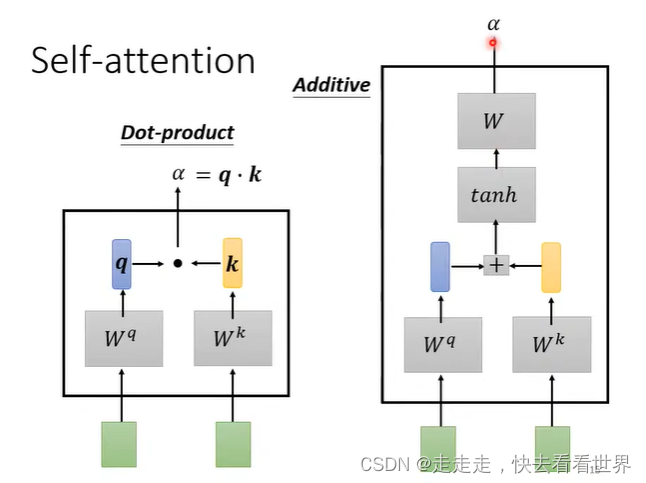
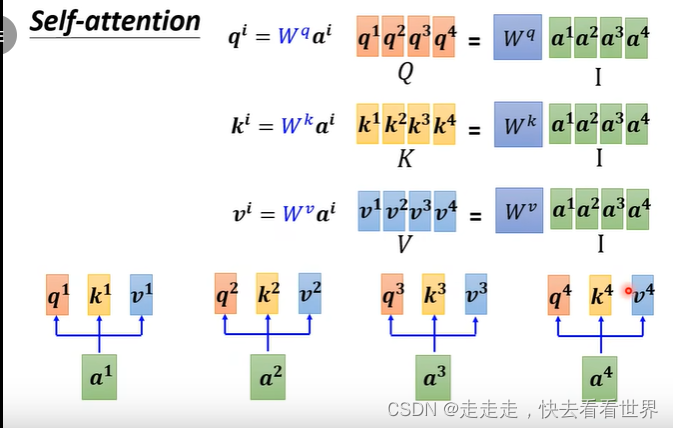
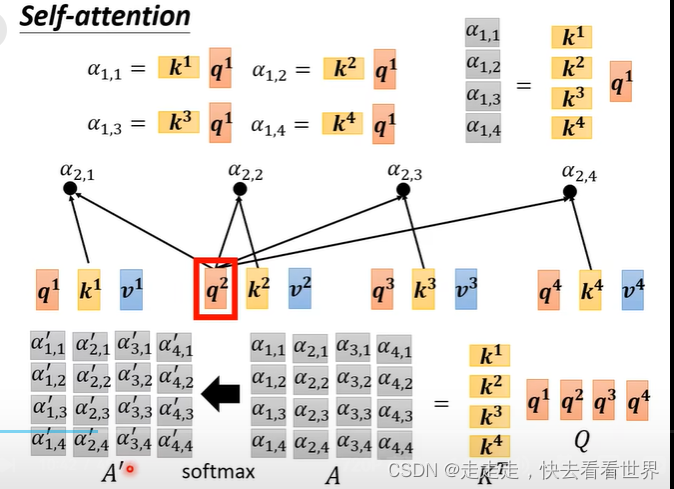
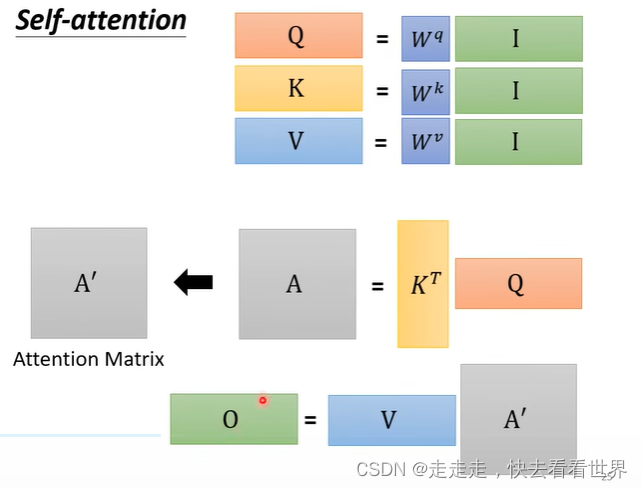
因为自己直接就知道self-attention的实现,所以这里就放一些图片,self-attention有很多实现的方法但是这里只讲Dot-product。在这个方法里面有一步归一化,可以用挺多方法的,这里用的是softmax。
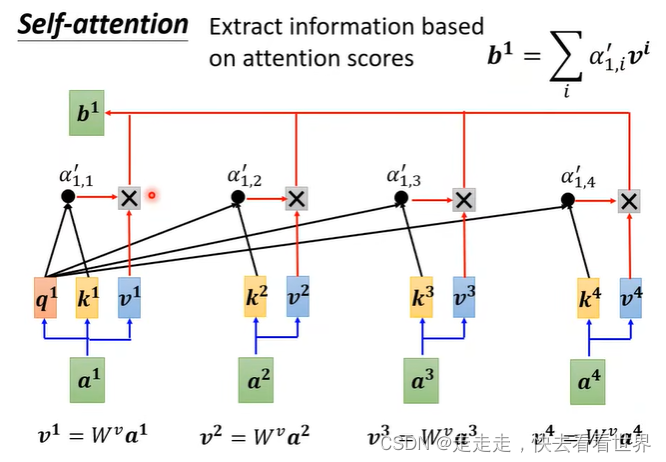
从矩阵角度看
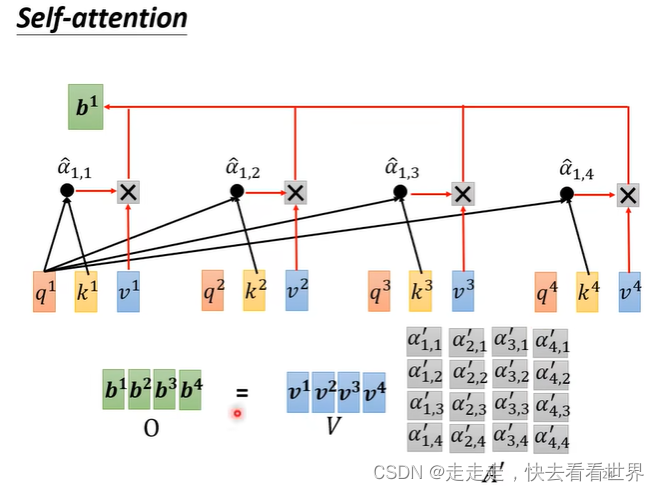
最终是这样的
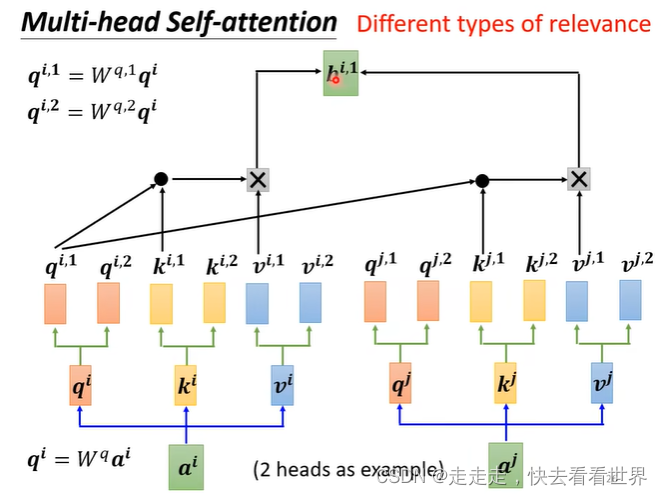
这里我们可以设置多个头也就是multi,因为相关信息不止一个,可能有很多种相关信息,设置多个头就可以学习到这些信息,具体做法如下:
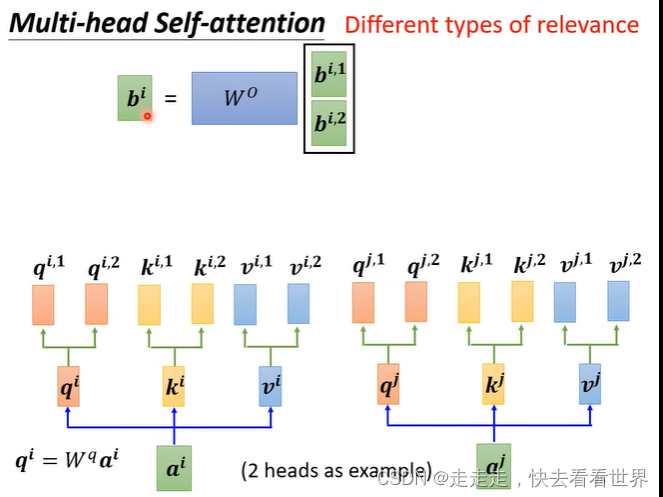
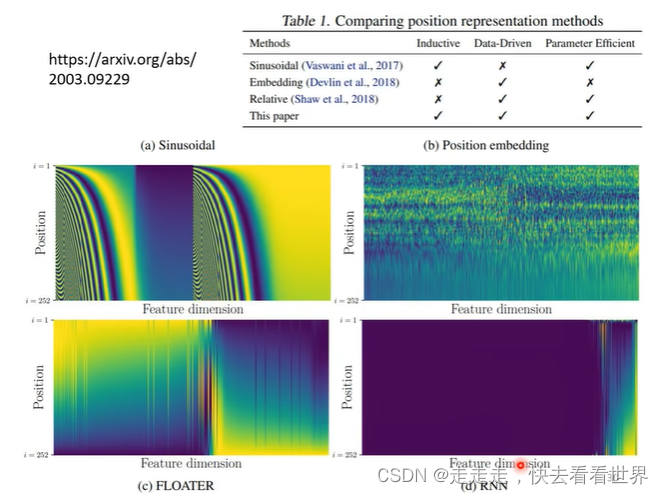
这里可以看到self-attention没有考虑到位置信息,所以在要考虑位置信息的任务里,可以在一开始加上位置编码。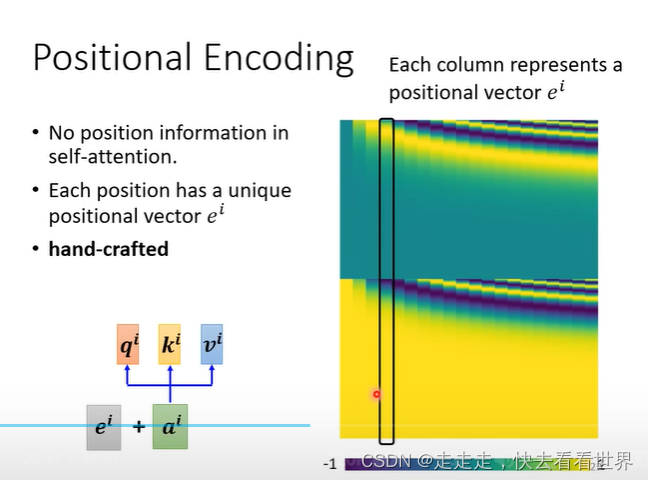
位置编码可以有很多种,同时位置编码甚至可以学习出来。什么样的位置编码更好,这是一个有待研究的问题。
应用
语言识别
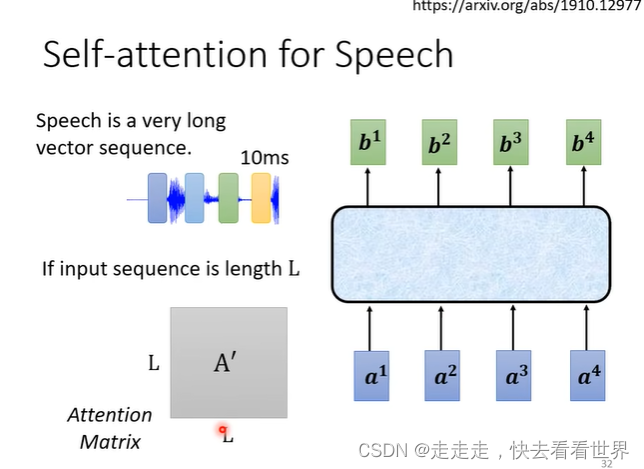
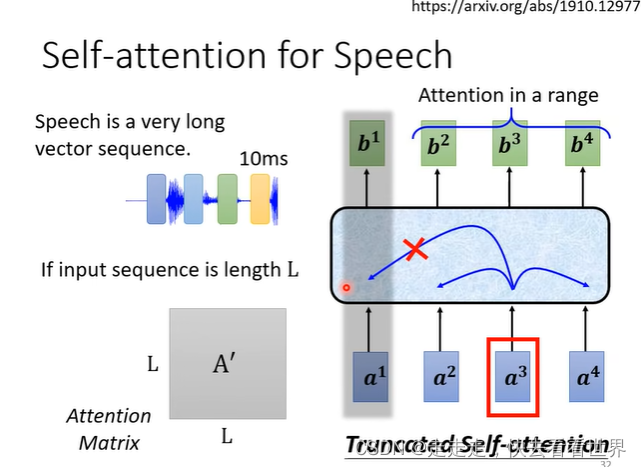
语音辨识并不需要看全局信息,同时在语言识别的任务里有很多向量,所以实际中也不可能让其看全局信息,因为矩阵和长度成平方的关系。所以这里可以用局部的attention
图像
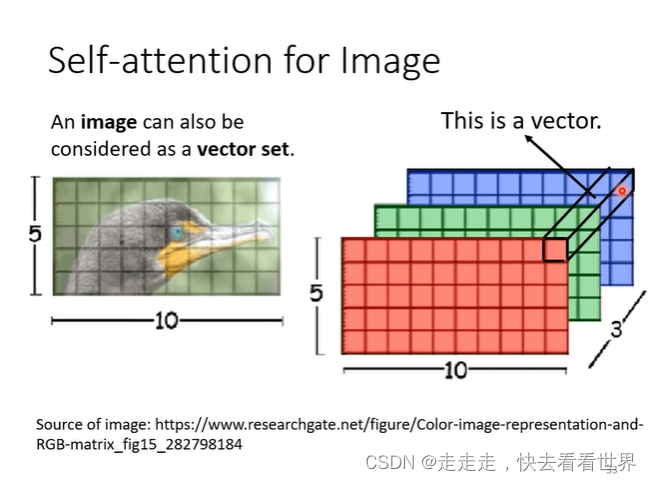
可以将图片看成一个5*10个3维向量。具体的应用如下:
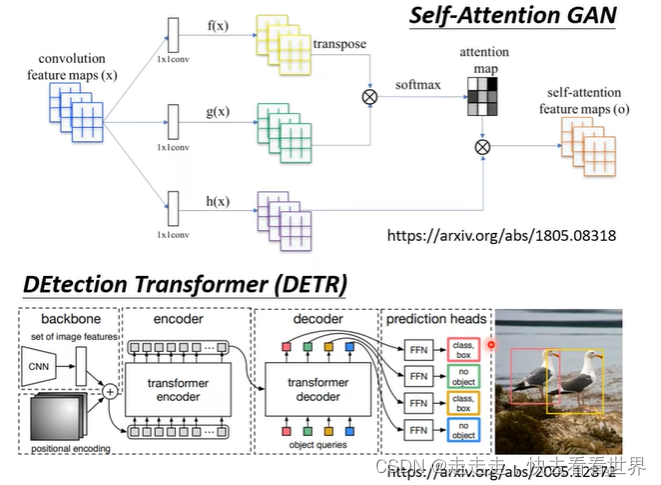
与其他模型的比较
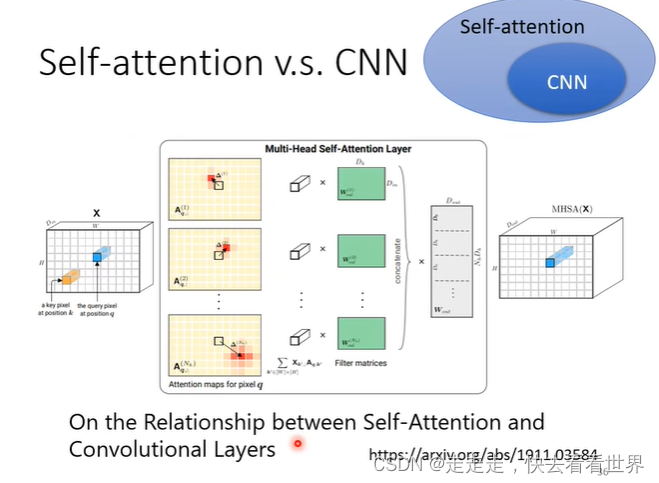
self-attention vs CNN

因为self-attention是可以看到全局信息的,所以CNN可以看成简化版的self attention,self-attention比CNN的弹性更大,所以需要更多的数据来训练模型,下面也证实了
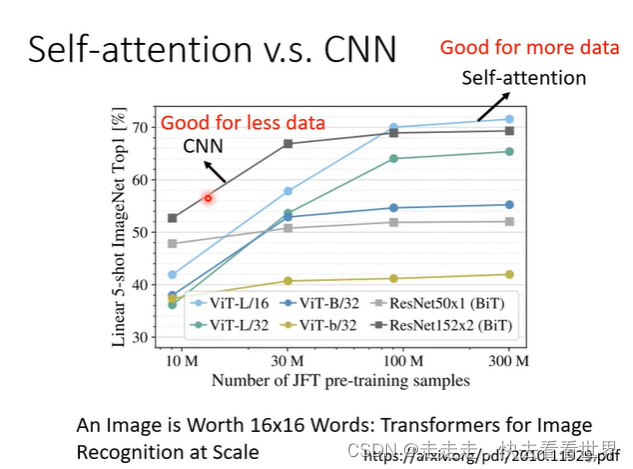
当训练数据比较小时,CNN的结果好,但是self-attention在较大的数据集上效果好。
self-attention vs RNN
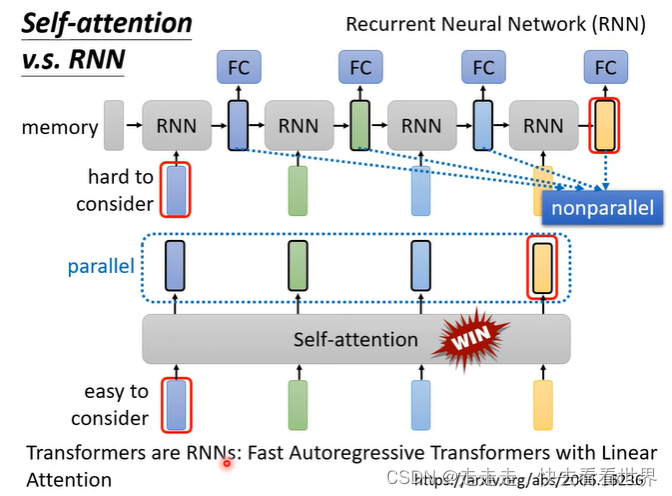
从这张图看,感觉RNN不能看到右边的信息。虽然单向RNN不能看到右边的信息,但是双向的RNN却可以看到。同时self-attention经过一定设计是可以取代RNN的,同时RNN有前后依赖,没有办法并行化,但是self-attention可以很好的并行。
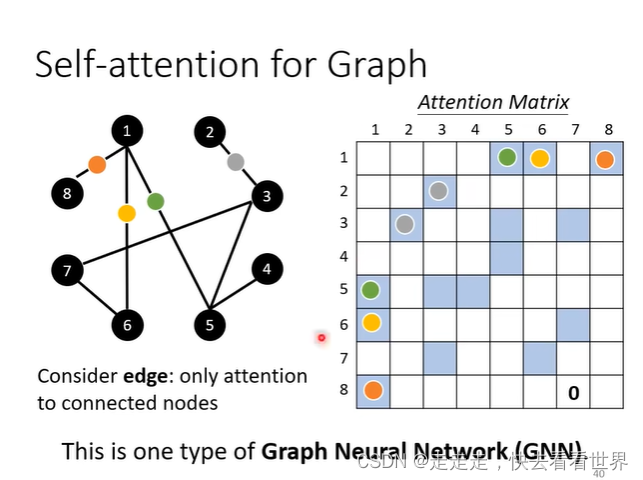
Self-attention for Graph
self-attention可以是一种GNN,在计算时,只计算和节点相连的节点。
self-attention运算量
self-attention运算量非常大,所以研究什么样的self-attention能又快又准是一个有价值的研究方向,近期也有人在做这一件事情。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









