






 这篇博客介绍了C++中的函数,包括函数的作用、类型、声明与调用、函数重载、内置函数、函数模板、内部与外部函数、默认参数、参数传递方式,以及递归算法的应用。还探讨了const和static的区别、变量作用域和生存期,并举例说明了如何使用memset和memcpy函数。
这篇博客介绍了C++中的函数,包括函数的作用、类型、声明与调用、函数重载、内置函数、函数模板、内部与外部函数、默认参数、参数传递方式,以及递归算法的应用。还探讨了const和static的区别、变量作用域和生存期,并举例说明了如何使用memset和memcpy函数。
ciao~
俺又来啦

为了方便查看俺就把目录放在下面,😃


————————分割线————————
这周学函数
yeah
最爱的函数(才怪
废话少说 开始吧
函数
认识函数
第一个问题 为啥要用函数
- 避免重复造作
- 分而治之思想
第二个问题 什么是函数
1.能够完成特定功能的独立代码块
2.能够接收数据,并对接受的数据进行处理;可以不接受数据,可以不返回结果,可以返回结果。
函数的一般形式
类型 函数名(类型 参数1,类型 参数2,…
)
{
声明语句序列;
可执行语句序列;
return表达式;
}
return语句的用法
1.允许有多个return语句。
2.任意一个return语句执行,结束函数的执行,返回到主调函数。
return语句返回值类型的确定
1.表达式的类型应跟返回值的类型保持一致
2.对于没有返回值的函数,可以明确定义为空类型“void”。
函数库
#include<iostream>//标准词库
#include<cmath>//数学词库
#include<ctime>//提供time函数
#include<cstdlib>//种子算法
这位dalao的帖子更加的详细 https://blog.youkuaiyun.com/sai19841003/article/details/7957115?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-7&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-7
这位dalao的帖子更加详细 https://blog.youkuaiyun.com/sai19841003/article/details/7957115?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-7&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-7
例子——判断素数
int pdprime(int n)
{
int i;
for(i=2;i<=n;i++)
{
if(n%i==0)
{return 0;}
if(i==n)
{return 1;}
}
}
调用和声明
调用
流程
形参和实参
int(返回值类型) funMax(int x,int y)
// x,y为形参
{
if(x>y)
return x;// return函数:函数出口
else
return y;
}
int main()
{
int x,y
}
调用
1.调用格式
函数名(实参表)
2.调用方式
有返回值
M=FUNMAX(x,y) //表达式形式的调用
无返回值
fun(a,b) //语句形式的调用
声明
意义
1.有助于编译器对函数参数类型的匹配检查。
格式
数据类型 函数名 (形参列表)
最好放在程序的初始位置
Tips
- 通常来说,不需要建立存储空间的声明称为声明,即非定义声明,也称引用性声明。把需要建立存储空间的声明称为定义。
函数重载
同一作用域,可以由一组具有相同函数名,不同 参数列表的函数,减少函数名,提高可读性。
必须满足至少两个条件:
- 形参的个数不一样
- 形参的类型不一样
内置函数
将调用函数中的函数称为内置函数(inline function),又称为内嵌函数也称内联函数。一般规模很小(五个语句一下)且频繁使用。
不能包括循环语句和switch等复杂语句
可以节省运行时间,但却增加了目标程序的长度,可以在声明函数和定义函数时同时写inline,也可只在声明时加inline。
函数模板
建立一个通用函数,其函数类型和形参类型不具体指定,用一个虚拟的类型代表。
这个通用函数就称为函数模板。
一般类型为
template OR template
(参数可以不只一个)
内部函数和外部函数
内部函数(静态函数)
只能被本文件中其他函数调用
在定义内部函数时,在函数名和函数类型的前面加static。eg: static int fun(int a,int b)
外部函数坑
有默认参数的函数
格式 float area(float r=6.5)//函数声明
头文件坑
内容
一般包含一下:
- 对类型的声明
- 函数声明
- 内置(inline)函数的定义
- 宏定义。用#define定义的符号常量和用const声明的常变量。
- 全局变量定义
- 外部变量声明
- 还可根据需要包含其他头文件
默认形参值
eg:
double area(double r=6.5)
r的值固定,即为默认形参。
注意
1.默认值的参数必须放在形参表列中的最右端。
2.声明中给出默认值,定义时不能再给出默认值。
const和static的区别
- const定义的常量在超出其作用域之后其空间会被释放,而static定义的静态常量在函数执行后不会释放其存储空间。
- static修饰全局变量,并未改变其存储位置及生命周期,而是改变了其作用域,使当前文件外的源文件无法访问该变量且对全局函数也是有隐藏作用。
作用域
分类
文件作用域 在{}外
函数或者块作用域在{}内
生存期
变量能保存值的时间范围
变量的种类
局部变量
具有函数作用域或块作用域的变量,增加模块内聚性。
同一源文件中,全局变量与局部变量同名则在局部变量作用范围内,全局变量被屏蔽,不起作用。
寄存器变量
寄存器变量是放在CPU中,需要时直接从寄存器取出参加运算,不必再去内存中去存取。
int fac(int n)
{
register int i,f=f*i;
for(i=1;i<=n;i++)
{f=f*i;}
return f;
}
全局变量
具有文件作用域的变量,模块的可移植性降低。
之前声明的全局变量int i,和下文中出现变量::i是同一变量,均为std标准域中的全局变量。
用extern声明外部变量
用extern声明全局变量,以扩展全局变量的作用域。
- 在一个文件内声明全局变量
如果外部变量想在定义点之前的函数引用该全局变量,则应该在引用之前用关键字extern对变量做外部变量声明,表示该变量是一个在下面定义的全局变量。这种声明称为提前引用声明。 - 在多文件的程序中声明外部变量
- 一个程序包含两个文件,两个文件都要用同一个外部变量num,需在任何一个文件中定义外部变量num,在另一个文件中用extern对num作外部变量。
变量的声明和定义
外部变量
- 定义只能有一次,位置在所有函数之外。
- 声明可有很多次,位置在函数内,也可在函数外。
存储类别
静态变量格式
static 变量类型 变量名;
外部变量
延展全局变量的作用域
参数传递
函数之间共享数据是通过参数传递完成的
函数封装的体现
值传递
方式
函数的形参的类型为简单变量 (非指针变量)
实参的值不变
地址传递
特征
形参的改变会影响实参的改变
方式
形参为指针
写个代码感受一下
void fun(int *a,int *b)
{
int t;
t=*a;
*a=*b;
*b=t;
}
int main()
{
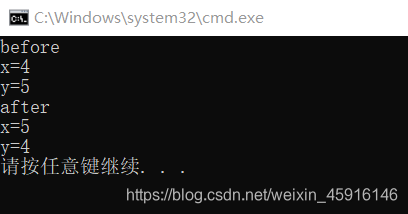
int x=4,y=5;
cout<<"x="<<x;
cout<<"y="<<y;
fun(&x,&y);
cout<<"x="<<x;
cout<<"y="<<y;
return 0
}
参数为数组名
将实参数组的首地址赋予形参数组名,形参数组名取得首地址后与实参数组为同一数组。
一维数组
代码如下
int a[10]={0,1,2,3,4,5,6,7,8,9} cout<<Max(a,10)<<endl;
int Max(int b[ ], int n) {代码段}
此时,int a[]= int b[]
//int b[] 不限制传递的元素个数
二维数组
格式
用指针数组的指针变量
eg: fun(double (*p)[N])
用二维数组
eg:fun(double a[][N]);
引用
引用可看作另外的变量的别名,对形参做的任何操作都会影响主调函数的实参变量。
//原函数中
funSwape( x,y );
//被调函数为
void funSwape(int &a,int &b)
//&a,%b即为引用
//x的别名为&a y的别名&b
//&a &b与x y的作用域不同
递归算法
概念
核心思想是分解。
把一个复杂的问题使用同一个策略将其分解为较简单的问题,如果这个问题仍然不能解决则再次分解,直到问题能被直接处理为止。
递归算法是指一种通过重复将问题分解为同类的子问题而解决问题的方法。
这种直接或间接调用自身的算法称为递归算法。
通俗的讲
先传‘递’出去,再回‘归’到本位。
要素
边界条件和递归方程
例子——求n!
代码如下:
//递归法求n的阶乘 未完善当n<0时
/*void Print(double t,double n)
{
if(t==0)
{
cout<<":)算你🐎呢 负数没有阶乘";
}
if(t==1)
{
cout<<n<<"的阶乘为1";
}
else
{
cout<<n<<"的阶乘为"<<t;
}
}
double Input(double n)//n!相对比较大 用double型
{
if(n<0)
{
return 0;
}
else if(n==0 || n==1)//应该用“或”
{
return 1;
}
else
{
return n*Input(n-1);//自己调用自己 当n=1是停止
}
}
int main()
{
double n,t;
cout<<"请输入你要计算的整数n"<<endl;
cin>>n;
t=Input(n);
Print(t,n);
return 0;
}
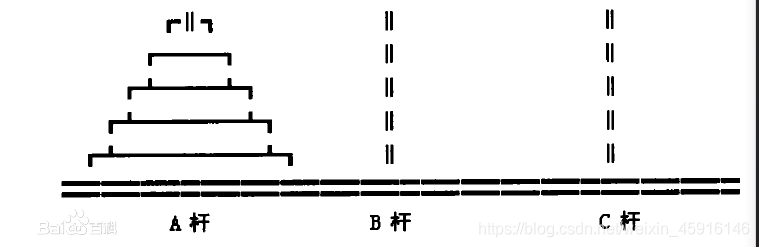
例子—汉诺塔问题
有A,B,C三根柱子,A柱上按大小顺序从下往上摞着n片圆盘,现在要将这些圆盘从A柱移至C柱,并保持上小下大的顺序。移动规则如下:1、每次只能移动一个盘。2、大盘不能放在小盘上。
作者:Fireman A
链接:https://www.zhihu.com/question/24385418/answer/257751077
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
文章如下:
对递归的理解的要点主要在于放弃!
放弃你对于理解和跟踪递归全程的企图,只理解递归两层之间的交接,以及递归终结的条件。想象你来到某个热带丛林,意外发现了十层之高的汉诺塔。正当你苦苦思索如何搬动它时,林中出来一个土著,毛遂自荐要帮你搬塔。他名叫二傻,戴着一个草帽,草帽上有一个2字,号称会把一到二号盘搬到任意柱。你灵机一动,问道:“你该不会有个兄弟叫三傻吧?”“对对,老爷你咋知道的?他会搬一到三号盘。“”那你去把他叫来,我不需要你了。“于是三傻来了,他也带着个草帽,上面有个3字。你说:”三傻,你帮我把头三个盘子移到c柱吧。“三傻沉吟了一会,走进树林,你听见他大叫:”二傻,出来帮我把头两个盘子搬到C!“由于天气炎热你开始打瞌睡。朦胧中你没看见二傻是怎么工作的,二傻干完以后,走入林中大叫一声:“老三,我干完了!”三傻出来,把三号盘从A搬到B,然后又去叫二傻:“老二,帮我把头两个盘子搬回A!”余下的我就不多说了,总之三傻其实只搬三号盘,其他叫二傻出来干。最后一步是三傻把三号盘搬到C,然后呼叫二傻来把头两个盘子搬回C事情完了之后你把三傻叫来,对他说:“其实你不知道怎么具体一步一步把三个盘子搬到C,是吧?”三傻不解地说:“我不是把任务干完了?”你说:“可你其实叫你兄弟二傻干了大部分工作呀?”三傻说:“我外包给他和你屁相干?”你问到:“二傻是不是也外包给了谁?“三傻笑了:“这跟我有屁相干?”你苦苦思索了一夜,第二天,你走入林中大叫:“十傻,你在哪?”一个头上带着10号草帽的人,十傻,应声而出:“老爷,你有什么事?”“我要你帮把1到10号盘子搬到C柱““好的,老爷。“十傻转身就向林内走。“慢着,你该不是回去叫你兄弟九傻吧““老爷你怎么知道的?““所以你使唤他把头九个盘子搬过来搬过去,你只要搬几次十号盘就好了,对吗?““对呀!““你知不知道他是怎么干的?““这和我有屁相干?“你叹了一口气,决定放弃。十傻开始干活。树林里充满了此起彼伏的叫声:“九傻,来一下!“ “老八,到你了!““五傻!。。。“”三傻!。。。“”大傻!“你注意到大傻从不叫人,但是大傻的工作也最简单,他只是把一号盘搬来搬去。若干年后,工作结束了。十傻来到你面前。你问十傻:“是谁教给你们这么干活的?“十傻说:“我爸爸。他给我留了这张纸条。”他从口袋里掏出一张小纸条,上面写着:“照你帽子的号码搬盘子到目标柱。如果有盘子压住你,叫你上面一位哥哥把他搬走。如果有盘子占住你要去的柱子,叫你哥哥把它搬到不碍事的地方。等你的盘子搬到了目标,叫你哥哥把该压在你上面的盘子搬回到你上头。“你不解地问:“那大傻没有哥哥怎么办?“十傻笑了:“他只管一号盘,所以永远不会碰到那两个‘如果’,也没有盘子该压在一号上啊。”但这时他忽然变了颜色,好像泄漏了巨大的机密。他惊慌地看了你一眼,飞快地逃入树林。第二天,你到树林里去搜寻这十兄弟。他们已经不知去向。你找到了一个小屋,只容一个人居住,但是屋里有十顶草帽,写着一到十号的号码。
不难发现,我们只需要找到递归的终止条件和两层之间的关系即可。
代码如下:
using namespace std;
#include <iostream>
void move(char getdisk,char putdisk)
{
cout<<getdisk<<"->"<<putdisk<<endl;
}
void fun(int n,char a,char b,char c)
{
if(n==1)
{
move(a,c);
}
else
{
fun(n-1,a,c,b);//n-1个盘子已移走
move(a,c);//A柱子上只剩一个盘子
fun(n-1,b,a,c);//B柱子上的盘子移动到C柱子
}
}
int main()
{
int n;
cin>>n;
fun(n,'A','B','C');
return 0;
}
函数家族们
想把看到的函数尽可能记录下来
memset函数
不是menset函数呀
引用自百度百科
定义
作用是在一段内存块中填充某个给定的值,它是对较大的结构体或数组进行清零操作的一种最快方法。
memset()函数原型是extern void *memset(void *buffer, int c, int count)
buffer:为指针或是数组,c:是赋给buffer的值,count:是buffer的长度.
正确用法:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char a[5];
memset(a,'1',5);
for(int i=0;i<5;i++)
cout<<a[i]<<"";
system("pause");
return 0;
}
错误用法:
#include <iostream>
#include <cstring>
#include <windows.h>
using namespace std;
int main()
{
int a[5];
memset(a,1,20);
//也等价于memset(a,1,sizeof(a));.
for(int i=0;i<5;i++)
cout<<a[i]<<"";
system("pause");
return 0;
}
问题是:第一个程序为什么可以,而第二个不行?
答:因为第一个程序的数组a是字符型的,字符型占据内存大小是1Byte,而memset函数也是以字节为单位进行赋值的,所以你输出没有问题。而第二个程序a是整型的,使用 memset还是按字节赋值,这样赋值完以后,每个数组元素的值实际上是0x01010101即十进制的16843009。
如果用memset(a,1,20),就是对a指向的内存的20个字节进行赋值,每个都用数1去填充,转为二进制后,1就是00000001,占一个字节。一个int元素是4字节,合一起是0000 0001,0000 0001,0000 0001,0000 0001,转化成十六进制就是0x01010101,就等于16843009,就完成了对一个int元素的赋值了。
memcpy函数
引用自百度百科
函数原型
void *memcpy(void destin, void source, unsigned n);
参数
destin-- 指向用于存储复制内容的目标数组,类型强制转换为 void 指针。
source-- 指向要复制的数据源,类型强制转换为 void 指针。
n-- 要被复制的字节数。
功能
从源source所指的内存地址的起始位置开始拷贝n个字节到目标destin所指的内存地址的起始位置中。
所需头文件
C语言:#include<string.h>
C++:#include<cstring>
strcpy和memcpy主要有以下3方面的区别。
1、复制的内容不同。strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。
2、复制的方法不同。strcpy不需要指定长度,它遇到被复制字符的串结束符"\0"才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。
3、用途不同。通常在复制字符串时用strcpy,而需要复制其他类型数据时则一般用memcpy


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









